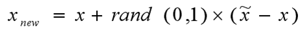目录:SMOTE算法
- 1、不平衡数据的背景知识
- 2、SMOTE算法的理论思想
- 3、SMOTE模块的使用
1、不平衡数据的背景知识
在实际应用中,分类问题中类别的因变量可能存在严重的偏倚,即类别之间的比例严重失调,如欺诈问题,欺诈类观测在样本集中毕竟占少数;客户流失问题中,忠实的客户往往也是占很少一部分:在某营销活动中,真正参与活动的客户也同样只是少部分。
如果数据存在严重的不平衡,预测得出的结论往往是有偏的,即分类结果会偏向于较多观测的类。对于这种问题该如何处理呢?
最简单的办法就是构造1:1的数据,要么将多的那一类砍掉一部分(欠采样),要么将少的那一类进行Bootstrap抽样(欠采样)。但这样做会存在问题,对于第一种方法,砍掉的数据会导致某种隐含信息的丢失,而第二种方法中,有放回的抽样形成的简单复制,又会使模型产生过拟合。
为了解决数据的非平衡问题,2002年Chawla提出了SMOTE算法,即合成少数过采样技术,它是基于随机采样算法的一种改进方案。该技术是目前处理非平衡数据的常用手段,并受到学术界和工业界的一致认同,接下来简单描述一下该算法的理论思想。
2、SMOTE算法的理论思想
SMOTE算法的基本思想是对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使得原始数据中的类别不再严重失衡。该算法的模拟过程采用了KNN算法,模拟生成新样本的步骤如下:
- 采样最近邻算法,计算出每个少数类样本的K个近邻;
- 从K个近邻中随机挑选N个样本进行随机线性插值;
- 构造新的少数类样本;
- 将新样本与原数据进行合成,产生新的训练集;

如上图所示,实心圆点代表的样本数量明显要多于五角星代表的样本点,如果使用SMOTE算法模拟增加少类别的样本点,则需要经过如下几个步骤:
-
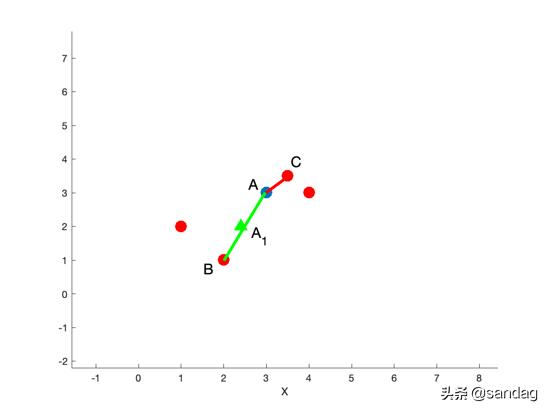
利用KNN算法,选择离样本点 x 1 x_1 x1最近的K个同类样本点;
-
从最近的K个同类样本点中,随机挑选M个样本点,这里为了简单介绍,选择M为2,M的取值依赖于最终所希望的平衡率。
-
对于每一个随机选中的样本点,构造新的样本点。新样本点的构造需要使用下方的公式: x n e w = x i + r a n d ( 0 , 1 ) ∗ ( x j − x i ) , j = 1 , 2 , . . . , M x_{new}=x_i+rand(0,1)*(x_j-x_i),j=1,2,...,M xnew=xi+rand(0,1)∗(xj−xi),j=1,2,...,M其中 x i x_i xi表示少数类别中的一个样本点; x j x_j xj表示从K近邻中随机挑选的样本点j:rand(0,1)表示生成0-1的随机数。
举个例子进行说明,假设图中样本点 x 1 x_1 x1的观测值为 ( 2 , 3 , 10 , 7 ) (2,3,10,7) (2,3,10,7),从图中的5个近邻随机挑选两个样本点,它们的观测值分别为 ( 1 , 1 , 5 , 8 ) (1,1,5,8) (1,1,5,8)和 ( 2 , 1 , 7 , 6 ) (2,1,7,6) (2,1,7,6),由此得到的两个新样本点为: x n e w 1 = ( 2 , 3 , 10 , 7 ) + 0.3 ∗ ( ( 1 , 1 , 5 , 8 ) − ( 2 , 3 , 10 , 7 ) ) = ( 1.7 , 2.4 , 8.5 , 7.3 ) x_{new1}=(2,3,10,7)+0.3*((1,1,5,8)-(2,3,10,7))=(1.7,2.4,8.5,7.3) xnew1=(2,3,10,7)+0.3∗((1,1,5,8)−(2,3,10,7))=(1.7,2.4,8.5,7.3) x n e w 2 = ( 2 , 3 , 10 , 7 ) + 0.26 ∗ ( ( 2 , 1 , 7 , 6 ) − ( 2 , 3 , 10 , 7 ) ) = ( 2.2 , 48 , 9.22 , 6.74 ) x_{new_2}=(2,3,10,7)+0.26*((2,1,7,6)-(2,3,10,7))=(2.2,48,9.22,6.74) xnew2=(2,3,10,7)+0.26∗((2,1,7,6)−(2,3,10,7))=(2.2,48,9.22,6.74)
-
重复步骤(1)、(2)和(3),通过迭代少数类别中的每一个样本 x i x_i xi,最终将原始的少数类别样本扩大为理想的比例。
3、SMOTE模块的使用
通过SMOTE算法实现过采样技术并不是太难,我们可以根据上面的步骤自定义一个抽样函数。当然也可以借助imblearn模块,并利用其子模块over_sampling中的SMOTE“类”实现新样本的生成。有关该类的语法和参数的含义如下:
SMOTE(ratio='auto',random_state=None,k_neighbors=5,m_neighbors=10,out_step=0.5,kind='regular',svm_eatimator=None,n_jobs=1)
- ratio:用于指定重抽样的比例,如果指定字符型的值,可以是’minority’(表示对少数类别的样本进行抽样),‘majority’(表示对多数类别的样本进行抽样)、‘not minority’(表示采用欠采样方法),‘all’(表示采用过采样的方法),默认为’auto’,等同于’all’和’not minority’。如果指定自典型的值,其中键为各个类别标签,值为类别下的样本量。
- random_state:用于指定随机数生成器的种子,默认为None,表示使用默认的随机数生成器;
- k_neighbors:指定近邻个数,默认为5个;
- m_neighbors:指定从近邻样本中随机挑选的样本个数,默认为10个;
- kind:用于指定SMOTE算法在生成新样本时所使用的选项,默认为’regular’,表示对少数类别的样本进行随机采样;
- svm_estimator:用于指定SVM分类器,默认为sklearn.svm.SVC,该参数的目的是利用支持向量机生成支持向量,然后生成新的少数类别的样本;
- n_jobs:用于指定SMOTE在过采样中所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能;


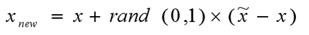




![[12]机器学习_smote算法](https://img-blog.csdnimg.cn/83d6c9cccbce4f6fa9e690046559280f.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pep5bed5qmZ,size_20,color_FFFFFF,t_70,g_se,x_16)