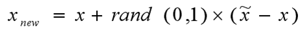1、smote原理介绍
在两个点连线中间取点
2、smote算法实现
import random
from sklearn.neighbors import NearestNeighbors
import numpy as np
import matplotlib.pyplot as pltclass Smote(object):def __init__(self, N=50, k=5, r=2):# 初始化self.N, self.k, self.r, self.newindexself.N = Nself.k = k# self.r是距离决定因子self.r = r# self.newindex用于记录SMOTE算法已合成的样本个数self.newindex = 0# 构建训练函数def fit(self, samples):# 初始化self.samples, self.T, self.numattrsself.samples = samples# self.T是少数类样本个数,self.numattrs是少数类样本的特征个数self.T, self.numattrs = self.samples.shape# 查看N%是否小于100%if (self.N < 100):# 如果是,随机抽取N*T/100个样本,作为新的少数类样本np.random.shuffle(self.samples)self.T = int(self.N * self.T / 100)self.samples = self.samples[0:self.T, :]# N%变成100%self.N = 100# 查看从T是否不大于近邻数kif (self.T <= self.k):# 若是,k更新为T-1self.k = self.T - 1# 令N是100的倍数N = int(self.N / 100)# 创建保存合成样本的数组self.synthetic = np.zeros((self.T * N, self.numattrs))# 调用并设置k近邻函数neighbors = NearestNeighbors(n_neighbors=self.k + 1,algorithm='ball_tree',p=self.r).fit(self.samples)# 对所有输入样本做循环for i in range(len(self.samples)):# 调用kneighbors方法搜索k近邻nnarray = neighbors.kneighbors(self.samples[i].reshape((1, -1)),return_distance=False)[0][1:]# 把N,i,nnarray输入样本合成函数self.__populateself.__populate(N, i, nnarray)# 最后返回合成样本self.syntheticreturn self.synthetic# 构建合成样本函数def __populate(self, N, i, nnarray):# 按照倍数N做循环for j in range(N):# attrs用于保存合成样本的特征attrs = []# 随机抽取1~k之间的一个整数,即选择k近邻中的一个样本用于合成数据nn = random.randint(0, self.k - 1)# 计算差值diff = self.samples[nnarray[nn]] - self.samples[i]# 随机生成一个0~1之间的数gap = random.uniform(0, 1)# 合成的新样本放入数组self.syntheticself.synthetic[self.newindex] = self.samples[i] + gap * diff# self.newindex加1, 表示已合成的样本又多了1个self.newindex += 1samples = np.array([[3,1,2], [4,3,3], [1,3,4],[3,3,2], [2,2,1], [1,4,3]])smote = Smote(N=500,k=10)
synthetic_points = smote.fit(samples)
print(synthetic_points.shape)print(random.uniform(0,13))plt.scatter(samples[:,0], samples[:,1])
plt.scatter(synthetic_points[:,0], synthetic_points[:,1])
plt.legend(["minority samples", "synthetic samples"])
plt.show()或者直接调用SMOTE包
c l a s s i m b l e a r n . o v e r _ s a m p l i n g . S M O T E ( ∗ , s a m p l i n g _ s t r a t e g y = ′ a u t o ′ , r a n d o m _ s t a t e = N o n e , k _ n e i g h b o r s = 5 , n _ j o b s = N o n e ) [ s o u r c e ] class imblearn.over\_sampling.SMOTE(*, sampling\_strategy='auto', random\_state=None, k\_neighbors=5, n\_jobs=None)[source] classimblearn.over_sampling.SMOTE(∗,sampling_strategy=′auto′,random_state=None,k_neighbors=5,n_jobs=None)[source]
from imblearn.over_sampling import SMOTE
#sampling_strategy参数就是说将
smo = SMOTE(sampling_strategy=0.6, random_state=2021)
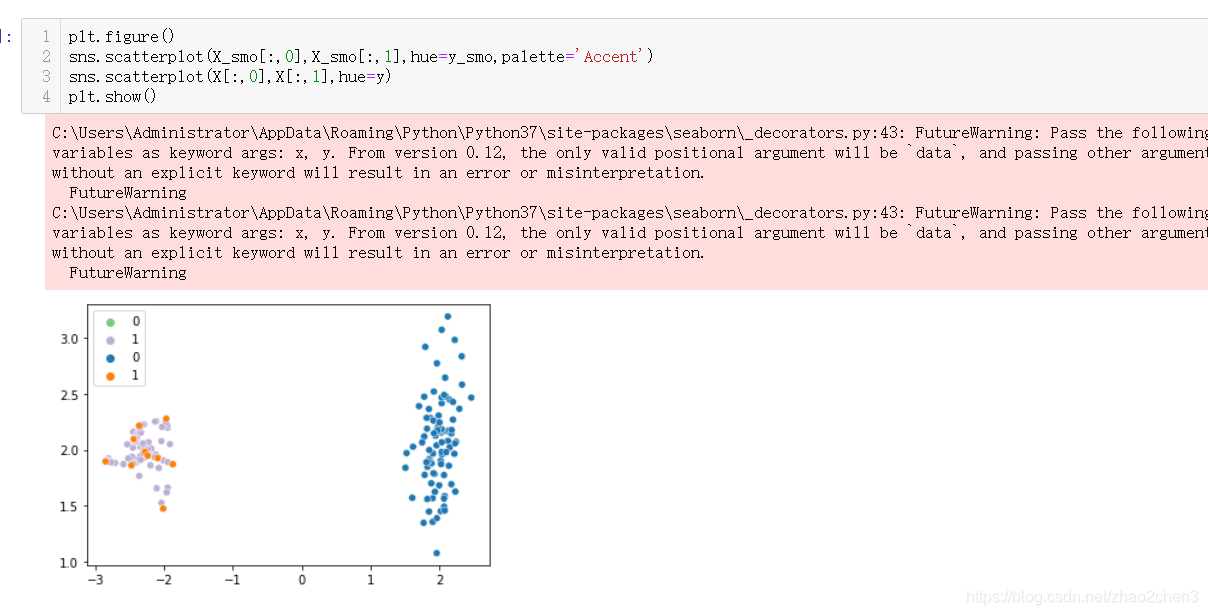
X_smo,y_smo = smo.fit_resample(X,y)
print(Counter(y_smo))使用smote算法之前1865:99,使用smote算法扩充以后,1865:1119

要注意strategy_sampling参数的使用,float只对于而分类有效。

#3、参考资料
https://blog.csdn.net/u014611178/article/details/109251961
https://imbalanced-learn.org/stable/references/generated/imblearn.over_sampling.SMOTE.html