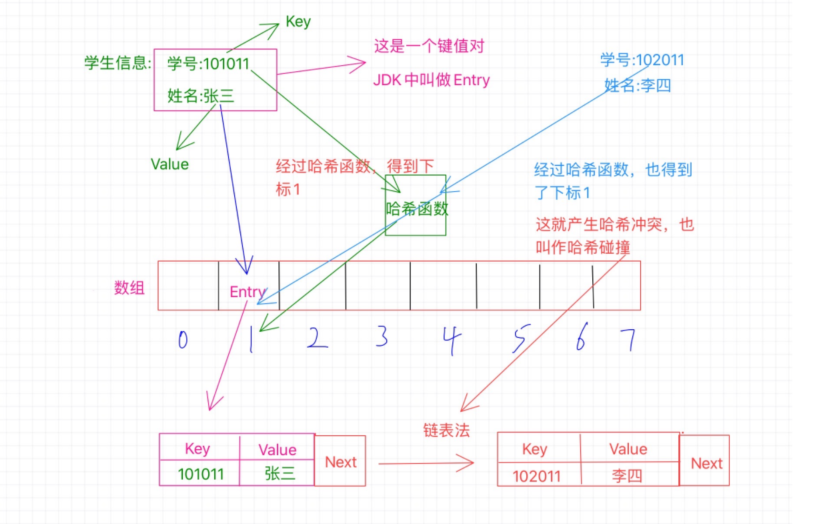
SMOTE全称是Synthetic Minority Oversampling Technique即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,具体如图2所示,算法流程如下。
- 对于少数类中每一个样本 x x x,以欧氏距离为标准计算它到少数类样本集 S m i n S_{min} Smin中所有样本的距离,得到其k近邻。
- 根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本 x x x,从其k近邻中随机选择若干个样本,假设选择的近邻为 x n xn xn。
- 对于每一个随机选出的近邻 x n xn xn,分别与原样本按照如下的公式构建新的样本
x n e w = x + r a n d ( 0 , 1 ) ∗ ∣ x − x n ∣ x_{new}=x+rand(0,1)*|x-xn| xnew=x+rand(0,1)∗∣x−xn∣

#SMOTE算法及其python实现
import random
from sklearn.neighbors import NearestNeighbors
import numpy as np
class Smote:def __init__(self,samples,N=10,k=5):self.n_samples,self.n_attrs=samples.shapeself.N=Nself.k=kself.samples=samplesself.newindex=0# self.synthetic=np.zeros((self.n_samples*N,self.n_attrs))def over_sampling(self):N=int(self.N/100)self.synthetic = np.zeros((self.n_samples * N, self.n_attrs))neighbors=NearestNeighbors(n_neighbors=self.k).fit(self.samples) print ('neighbors',neighbors)for i in range(len(self.samples)):print('samples',self.samples[i])nnarray=neighbors.kneighbors(self.samples[i].reshape((1,-1)),return_distance=False)[0] #Finds the K-neighbors of a point.print ('nna',nnarray)self._populate(N,i,nnarray)return self.synthetic# for each minority class sample i ,choose N of the k nearest neighbors and generate N synthetic samples.def _populate(self,N,i,nnarray):for j in range(N):print('j',j)nn=random.randint(0,self.k-1) #包括enddif=self.samples[nnarray[nn]]-self.samples[i]gap=random.random()self.synthetic[self.newindex]=self.samples[i]+gap*difself.newindex+=1print(self.newindex)
a=np.array([[1,2,3],[4,5,6],[2,3,1],[2,1,2],[2,3,4],[2,3,4]])
s=Smote(a,N=1000)
s.over_sampling()