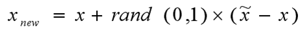💖作者简介:大家好,我是车神哥,府学路18号的车神🥇
⚡About—>车神:从寝室到实验室最快3分钟,最慢3分半(那半分钟其实是等红绿灯)
📝个人主页:应无所住而生其心的博客_府学路18号车神_CSDN博客
🥇 官方认证:人工智能领域新星创作者
🎉点赞➕评论➕收藏 == 养成习惯(一键三连)😋⚡希望大家多多支持🤗~一起加油 😁
专栏
《Golang · 过关斩将》
《Neural Network》
《微信小程序开发》
《LeetCode天梯》
《Algorithm》
《Python》
《web》
Borderline-SMOTE算法
- 🎉Borderline-SMOTE算法介绍
- 🤗源代码
最近写毕业课题论文,用到了Borderline-SMOTE算法,做故障诊断,其实实际工况中包含了很多的数据,而且监测周期极其不均匀,有的检测时间是按照月来采样,有的则是按照年,还有日度,实时等等。在很多地方是不平衡的数据,由此我们需要产生更多相似的数据。一般的虚拟样本生成技术有很多:蒙特卡洛法、整体趋势扩散技术、SMOTE、DNN、Bootstrap等等很多很多。由于最近用Borderline-SMOTE比较多,下面介绍一下!~
文末Python源代码自取!!!
🎉Borderline-SMOTE算法介绍
Borderline SMOTE是在SMOTE基础上改进的过采样算法,该算法仅使用边界上的少数类样本来合成新样本,从而改善样本的类别分布。
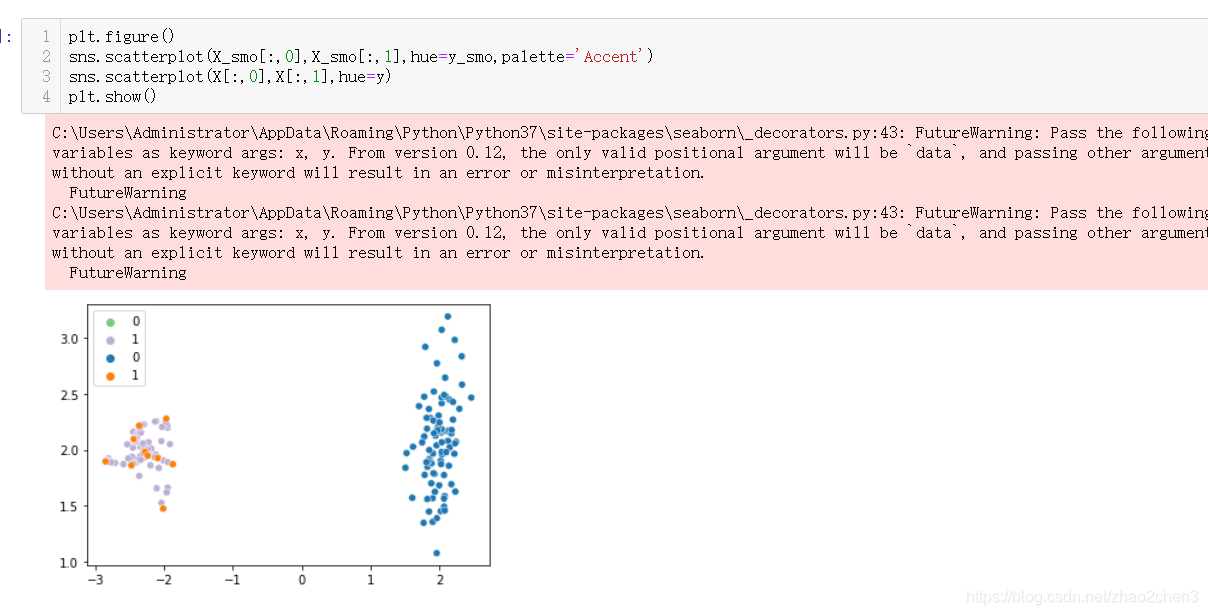
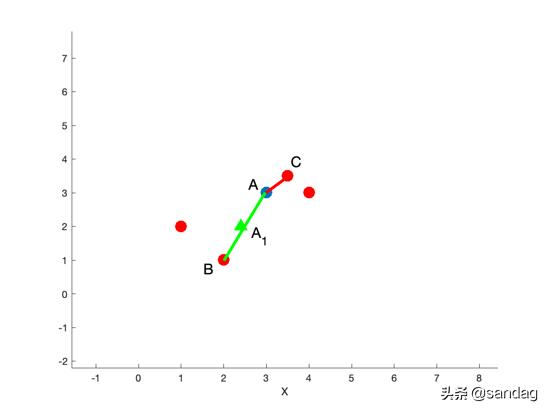
Smote 算法仍属于是建立在相距较近的少类样本之间样本的假设基础之上,还没有充分考虑邻近样本 的分布特点,会造成类间发生重复性的可能性较大,而 采用识别少类种子样本的 Borderline-Somte 算法可以 避免这种重复性的发生。基于边界上样本的合成样本原理如下图所示。
Borderline SMOTE采样过程是将少数类样本分为3类,分别为Safe、Danger和Noise。最后,仅对表为Danger的少数类样本过采样。
Borderline-SMOTE又可分为Borderline-SMOTE1和Borderline-SMOTE2,Borderline-SMOTE1在对Danger点生成新样本时,在K近邻随机选择少数类样本(与SMOTE相同),Borderline-SMOTE2则是在k近邻中的任意一个样本(不关注样本类别)

假设 S S S为样本集, S m i n S_{min} Smin 为少类样本集, S m a x j S_{maxj} Smaxj的多数样本集,m 为邻近样本个数, x i x_i xi 属性, x i j x_{ij} xij为邻近样本全部属性, x n x_n xn 为近邻样本, R i j R_{ij} Rij 取值0.5或1,合成算法步骤如下。
- Step1:假设每一个 x i ∈ S m i n x_i \in S_{min} xi∈Smin,确定与其最邻近的样本集,其数据集为 S N N S_{NN} SNN,且 S N N ∈ S S_{NN} \in S SNN∈S.
- Step:对每一个样本 x i x_i xi,判断最近邻属于多数样本集的个数,即 ∣ S N N ∩ S m a x j ∣ < m | S_{NN} \cap S_{maxj}| < m ∣SNN∩Smaxj∣<m;合成少数类的样本。即 x i x_i xi与近邻得出 x n x_n xn对应属性 j j j中的差值记为 d i j = x i − x i j d_{ij}=x_{i}-x_{ij} dij=xi−xij。得出合成新的少数类样本 h i j = x i + d i j × r a n d ( 0 , R i j ) h_{ij}=x_i+d_{ij} \times rand(0, R_{ij}) hij=xi+dij×rand(0,Rij)。
与 SMOTE 方法相比,Borderline-SMOTE 方法只针对边界样本进行近邻线性插值,使得合成后的少数 类样本分布更为合理.
哇,好久没有在Markdown手敲公式了,都有点手生了,哈哈哈。
🤗源代码
Python代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/28 10:49
# @Author : 府学路18号车神
# @Email :yurz_control@163.com
# @File : Borderline-SMOTE_imblearn.pyfrom collections import Counterimport numpy as np
import pandas as pd
from icecream import ic
from sklearn.datasets import make_classification
from imblearn.over_sampling import BorderlineSMOTE
import random
from sklearn.neighbors import NearestNeighbors# 读取数据
def loaddata(filename):df = pd.read_excel(io=filename)# ic(df)return np.array(df)# 均匀的100个数据
def gene_data(Lb, Ub):# 生成LB# 循环取值获得Lb和Ub的值m = Lb.shape[0]gene_box = []for i in range(m):gene_sample = np.linspace(Lb[i], Ub[i], 100)# ic(gene_sample)gene_box.append(gene_sample)return gene_boxclass Smote:def __init__(self,samples,N=10,k=5):self.n_samples,self.n_attrs=samples.shapeself.N=Nself.k=kself.samples=samplesself.newindex=0# self.synthetic=np.zeros((self.n_samples*N,self.n_attrs))def over_sampling(self):N=int(self.N/100)self.synthetic = np.zeros((self.n_samples * N, self.n_attrs))neighbors=NearestNeighbors(n_neighbors=self.k).fit(self.samples)print('neighbors',neighbors)for i in range(len(self.samples)):nnarray=neighbors.kneighbors(self.samples[i].reshape(1,-1),return_distance=False)[0]#print nnarrayself._populate(N,i,nnarray)return self.synthetic# for each minority class samples,choose N of the k nearest neighbors and generate N synthetic samples.def _populate(self,N,i,nnarray):for j in range(N):nn=random.randint(0,self.k-1)dif=self.samples[nnarray[nn]]-self.samples[i]gap=random.random()self.synthetic[self.newindex]=self.samples[i]+gap*difself.newindex+=1if __name__ == '__main__':# 读取数据datafile = "LbUbCL边界.xlsx"df = loaddata(datafile)df_LB = df[:, 2]df_UB = df[:, 3]# ic(df_LB, df_UB)# ic(df_LB.shape, df_UB.shape)# 在LB和UB区间内生成均匀的100个数据,然后再用borderline-SMOTE进行虚拟样本生成Initial_dt = np.array(gene_data(df_LB, df_UB))X = Initial_dt.Tic((Initial_dt.T).shape) # success# 相应的标签yy = np.array([1]*100)# y = np.ones((16, 100))# ic(y)# print('Original dataset shape %s' % Counter(y))# 对生成的100个样本使用borderline-SMOTE生成虚拟样本# sm = BorderlineSMOTE(random_state=42, kind="borderline-1")# X_res, y_res = sm.fit_resample(X, y)# print('Resampled dataset shape %s' % Counter(y_res))# ic(X_res, y_res)ss = Smote(X, N=100)res = ss.over_sampling()pd.DataFrame(res).to_excel("Borderline-SMOTE_result.xlsx")print(res)"""-----------------------------------------------------------"""# print('Original dataset shape %s' % Counter(y))# sm = BorderlineSMOTE(random_state=42, kind="borderline-1")# X_res, y_res = sm.fit_resample(X, y)# print('Resampled dataset shape %s' % Counter(y_res))# icecream.ic(X_res, y_res.shape)# X1, y1 = make_classification(n_classes=2, class_sep=2,# weights=[0.1, 0.9], n_informative=2, n_redundant=0, flip_y=0,# n_features=2, n_clusters_per_class=1, n_samples=100, random_state=9)# ic(X1, y1)
注意,由于我们的数据集是我的论文数据集,所以不能分析给大家啦!~
下面还有一个画图的代码也一起附上吧,仅供参考:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/12/28 21:35
# @Author : 府学路18号车神
# @Email :yurz_control@163.com
# @File : plot.pyimport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pylab import mpl, text
from matplotlib.font_manager import FontPropertiesroman = FontProperties(fname=r'C:\Windows\Fonts\Times New Roman.ttf', size=10) # Times new roman
mpl.rcParams['font.sans-serif'] = ['SimSun']
fontcn = {'family': 'SimSun','size': 10} # 1pt = 4/3px
fonten = {'family':'Times New Roman','size': 10}df = pd.read_excel("SMAPE_final.xlsx", sheet_name="Sheet2")
df2 = pd.read_excel("SMAPE_final.xlsx", sheet_name="Sheet4")
print(df)t1 = list(df2.iloc[0, 1:])
t2 = list(df2.iloc[1, 1:])
t3 = list(df2.iloc[2, 1:])
# X2 = ["MTD(%)", "MT-MTD(%)", "MD-MTDB(%)"]
X2 = ['10', '15', '20', '25', '&']plt.plot(X2, t1, linestyle="-.", marker="o", linewidth=2, label="MTD", markersize='8')
plt.plot(X2, t2, "-D", linewidth=2, label="MT-MTD", markersize='8')
plt.plot(X2, t3, "--v",linewidth=2, label="MD-MTDB", markersize='8')
plt.xlabel("Size of Sample", fontsize=15)
plt.ylabel("AveSMAPE(%)", fontsize=15)
plt.rcParams.update({'font.size':14})
plt.legend()
plt.show()y1 = list(df.iloc[0, 1:])
y2 = list(df.iloc[1, 1:])
y3 = list(df.iloc[2, 1:])
X = ['10', '15', '20', '25', '30']plt.plot(X, y1, '--o', linewidth=2, label='SMAPE no vitual samples', markersize='8')
plt.plot(X, y2, '-^', linewidth=2, label='SMAPE include vitual samples', markersize='8')
plt.xlabel("Size of Sample", fontsize=15)
plt.ylabel("AveSMAPE(%)", fontsize=15)
plt.rcParams.update({'font.size':14})
plt.legend()
plt.show()# plt.subplot(211)plt.bar(X, y3, width=0.8)
plt.xlabel("Size of Sample", fontsize=15)
plt.ylabel("AvePCR(%)", fontsize=15)
plt.show()

加油吧!~准备卷毕业课题第三章了,o(╥﹏╥)o

❤坚持读Paper,坚持做笔记,坚持学习,坚持刷力扣LeetCode❤!!!
坚持刷题!!!打天梯!!!
⚡To Be No.1⚡⚡哈哈哈哈
⚡创作不易⚡,过路能❤关注、收藏、点个赞❤三连就最好不过了
ღ( ´・ᴗ・` )
❤
『
万事开头难,然后中间难,最后结尾难。
』


![[12]机器学习_smote算法](https://img-blog.csdnimg.cn/83d6c9cccbce4f6fa9e690046559280f.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pep5bed5qmZ,size_20,color_FFFFFF,t_70,g_se,x_16)