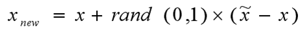SMOTE: Synthetic Minority Over-sampling Technique
论文地址:https://www.jair.org/index.php/jair/article/download/10302/24590
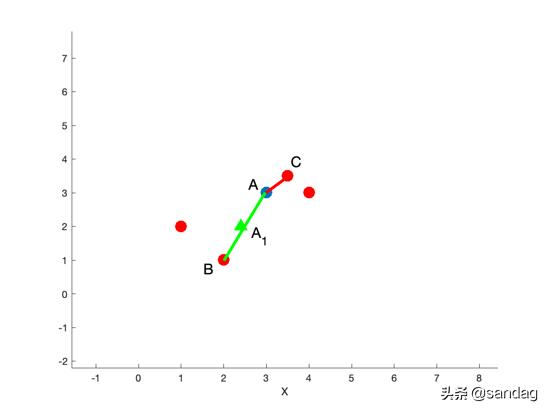
SMOTE的算法思路是:
- 使用K近邻,在附近(最少选附近5个点)随便找一个同一类别的点,然后连线
- 在线段上随便找一个点,就是新的样本点(论文里说的很学术:
新样本点 = 原始点+random(0,1) * 新旧差异)
详细代码可以参考:https://zhuanlan.zhihu.com/p/44055312

代码示例
安装方法:pip install imbalanced-learn
https://imbalanced-learn.org/stable/over_sampling.html
过采样的文档地址:https://imbalanced-learn.org/stable/over_sampling.html
import pandas as pd
from imblearn.over_sampling import SMOTEdef get_dataset():from sklearn.datasets import make_classificationdata_x, data_y = make_classification(n_samples=1000, n_classes=2, n_features=6, n_informative=4,random_state=0) # 2个特征# data_df = pd.DataFrame(data_x).merge(pd.Series(data_y, name="y_label"), left_index=True, right_index=True)data_x = pd.DataFrame(data_x)data_x.columns = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6']data_y = pd.Series(data_y)# 删除部分数据:删除100个label为0的数据drop_index = data_y[data_y == 0].sample(100).indexdata_y = data_y.drop(drop_index)data_x = data_x.drop(drop_index)return data_x, data_yif __name__ == '__main__':x_data, y_data = get_dataset() # 获取数据源# 使用smote生成数据smote_data = SMOTE().fit_resample(x_data, y_data.values)new_x_data = smote_data[0] # 新的xnew_y_data = smote_data[1] # 新的y
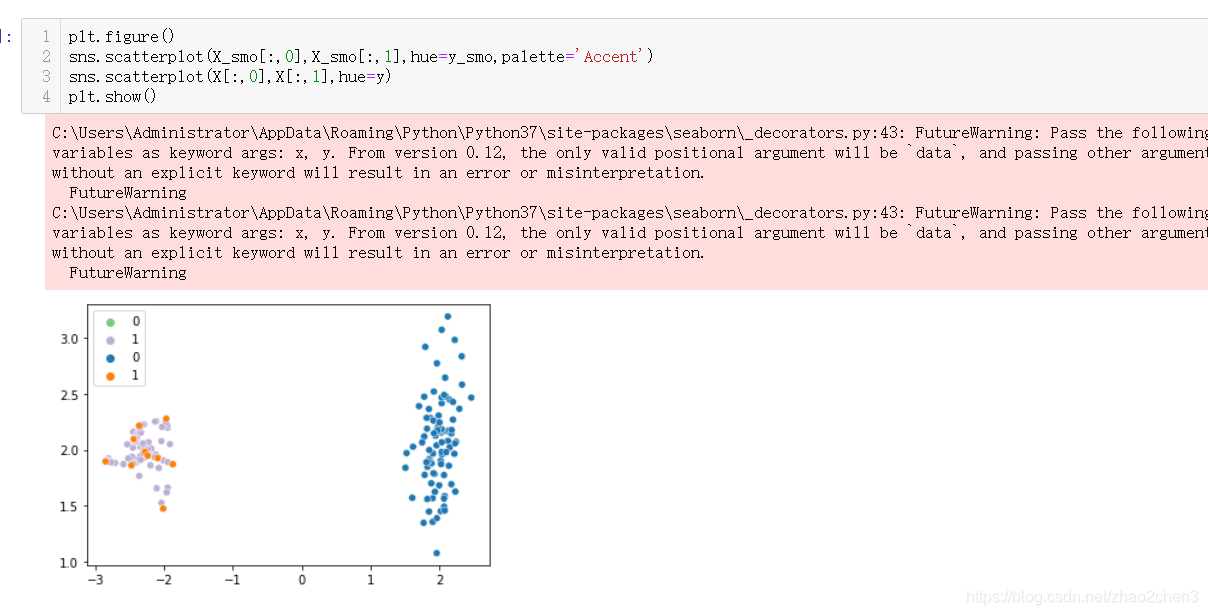
在工具中,如果有多个类别,会默认将拥有最多数据量的类对应的数据量,作为目标量,将其他所有类别的数据量都生成到这个量
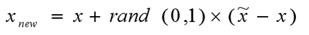




![[12]机器学习_smote算法](https://img-blog.csdnimg.cn/83d6c9cccbce4f6fa9e690046559280f.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5pep5bed5qmZ,size_20,color_FFFFFF,t_70,g_se,x_16)