以下文章内容摘自网络:说人话的统计学
原标题:广义线性模型到底是个什么鬼?
❉说人话的统计学❉
从逻辑回归模型开始,我们连续讲了好多集有些相似又特点各异的几种统计模型。它们有个统一的旗号,叫做「广义线性模型」(generalized linear model)。 许多在大学里学过一点统计的读者,可能对广义线性模型还是会感到比较陌生。为什么这些模型能被归为一个大类?它们的共同点在哪里?今天我们就和大家一块再来系统地认识一下,广义线性模型到底是何方神圣。
在耐着性子把这篇文章读完之前,大家肯定会想,为什么要学习广义线性模型呢?毕竟光是理解线性模型的各种用法就已经够头疼的了,再加个广义更绕不清楚了。
普通线性模型对数据有着诸多限制,真实数据并不总能满足。而广义线性模型正是克服了很多普通线性模型的限制。在笔者的心里,广义模型能解决的问题种类比普通线性模型多很多,用图来表示,大概就是这样的:
图一:定性对比广义线性模型和普通线性模型的能解决的问题多少
我们前面通过讨论逻辑回归、定序回归以及泊松回归模型,已经带着读者们在广义线性模型的世界里面转了一大圈。今天,我们将要回到广义线性模型的本质,从广义线性模型的三个要素——线性预测、随机性和联系函数入手,在理论层面系统深入地了解广义线性模型。
各路线性模型的共同点:线性预测
不管是普通线性模型,还是广义线性模型,既然打着「线性模型」旗号,总该是有个原因的吧?这里的「线性」指的是多个自变量的「线性组合」对模型预测产生贡献,也叫做线性预测,它具有类似于下面的形式:
这个形式读者们已经非常熟悉了,因为之前讲的所有模型使用的都是线性预测。
统计模型中的β0、β1、β2等是模型的参数,如果把模型看成是一个音箱,这些参数就像看是音箱上一个个控制声音的旋钮。为啥音箱得要怎么多旋钮呢?因为虽然拧每一个旋钮达到的效果不同,可能β0管的是低音炮部分,β1管的是中音区,β2管的是高音区,模型里面需要这么多参数也是为了控制各种自变量对因变量的影响的。
为什么各种常用的模型都选择线性预测呢?当我们调节某一个旋钮的时候,我们当然希望声音的效果与旋钮拧了多少成正比,如果拧了一圈声音跟蚊子叫一样,而拧了两圈声音突然震耳欲聋,这样的音箱用起来就得经过反反复复地调节才能找到最佳音量,非常的不方便。统计模型的在寻找最优参数的时候做得就是调节音量这件事,使用线性预测使得β0、β1、β2这些参数改变的值与预测的结果的改变值成正比,这样才能有效地找到最佳参数。
「随机性」— 统计模型的灵魂
我们之所以会建立统计模型,是想研究自变量(模型的输入)与因变量(模型的输出)之间的定量关系。通过模型计算出来的自变量的预测值与因变量的测量值越接近,就说明模型越准确。
虽然在建立模型时,我们希望统计模型能准确地抓住自变量与因变量之间的关系,但是当因变量能够100%被自变量决定时,这时候反而没有统计模型什么事了。典型的例子是中学时学习的物理定律,我们都知道,物体的加速度与它受的合力大小成正比,也就是说给定物体的质量和受力大小,加速度是一个固定的值,如果你答题的时候写,「有一定的概率是a,也有一定的概率是b」,物理老师肯定会气得晕过去。
统计模型的威力就在于帮助我们从混合着噪音的数据中找出规律。假设这个世界还没有人知道物体受的合力大小与加速度成正比,为了验证这一假说, 你仔细测了小滑块 在不同受力条件下的加速度,但由于手抖眼花尺子烂等等理由,哪怕是同样的受力,多次测量得到的加速度也会不一样,具有一定的随机性。也就是说,由于测量误差的存在,测量到的加速度(因变量y)与物体的受力大小(自变量x)之间不是严格的正比关系。
统计模型是怎样从具有随机性的数据中找到自变量和因变量之间的关系的呢?原因在于是随机误差也是有规律的。在测量不存在系统性的偏差的情况下,测量到的加速度会以理论值为平均值呈正态分布,详情可回顾《正态分布到底是怎么来的?| 协和八》。抓住这一统计规律,统计模型就能帮我们可以透过随机性看到自变量与因变量之间的本质联系,找出加速度与受力大小的关系。
如果不对自变量的随机性加以限制,再好的统计模型也无可奈何。试想一下,假如测量到的加速度值是不认真做实验的某个同学随手编的数值,那就不能保证它的平均值与实际值接近,自然也就无法正确地计算出加速度与受力大小的关系。
虽然在加速度的例子里面,因变量y的随机性来源于测量误差,但是实际应用中,y的随机性远不止测量误差,也有可能是影响y值变化的一些变量没有包含在模型中。比如一个公司的薪水由工龄,工作岗位和每月工时三个因素决定,但是在用模型预测薪水的时候,只用了工龄和工作岗位两个因素,这时模型就会把由工时不同导致的薪水不同看做是随机误差。
其实,统计模型并不在意y的随机性是由什么产生的:统计模型把因变量y中不能被模型解释的变化都算在误差项里面,并且通过对误差作出合理的假设,帮助我们找到自变量与因变量之间内在的关系。如何对随机性作出合理的假设,得根据具体情况具体分析,这也就演化出了各种各样的统计模型。
各路统计模型如何对付「随机性」?
在统计模型中,当自变量取特定值,因变量y的随机性由y的概率分布来决定。无论是普通线性模型还是广义线性模型,预测的都是自变量x取特定值时因变量y的平均值。因变量y的实际取值与其平均值之差被称为误差项,而误差的分布很大程度上决定了使用什么模型。我们下面就来回顾一下在不同的模型里面误差项得满足什么样的分布。
普通线性模型的基本假设之一是误差符合方差固定的正态分布(高斯分布)。只有一个因变量的普通线性模型具有下面的形式:
模型的输出β0+β1*x预测的是y的平均值,而误差项ε描述了y的随机性,普通线性模型中的方差不随自变量x取值的变化而变化。想深入回顾普通线性回归模型的读者,可以戳《如果只能学习一种统计方法,我选择线性回归 | 协和八》。
当误差项ε不再满足正太分布,或者误差项的方差会随着x的变化而变化的时候,普通线性模型就不够用了。由于正太分布描述的是一个连续变量的分布, 当因变量y是类别变量或是计数变量这样的非连续变量时 ,显然误差项就不能满足普通线性模型关于误差得是正态分布的要求,这时候就需要广义线性模型来救场了。
咱们先从最常用的逻辑回归模型说起。逻辑回归模型预测的是因变量y=1的概率P(y=1),它具有下面的形式:
对逻辑回归记不太清或者不熟悉的读者可以先不用纠结等式左边复杂的形式,我们一会儿再说。 与普通线性回归不同,逻辑回归的模型形式似乎并不能直接体现出y的误差项,毕竟等式的右边没有一个。 那么y的随机性是如何在逻辑回归中体现出来的?
在知道P(y=1)的情况下,y有可能取0也有可能取1,这是y随机性的来源。有趣的是,当我们用概率分布来描述y的随机性时,我们会发现,这不就是P(y=1)吗?由于y只能取两个值,知道取1的概率,自然就确定了y的概率分布,也就是说,y的随机性恰好被y的平均值刻画了,这与普通线性回归完全不一样。在普通线性回归里面,我们强调了,当y的预测值改变时,y实际值的方差是不变的,而在逻辑回归模型里面,模型的预测值同时也决定了方差。
下面再看看针对因变量是整数变量情形的泊松回归,泊松回归具有下面的形式
那泊松回归是如何处理y的随机性的呢? 泊松回归模型认为给定自变量的取值,因变量y满足泊松分布,模型的输出eβ0+β1*x1预测的是y的平均值,由于泊松分布只有一个参数,知道了分布的平均值整个分布也就确定了,于是泊松分布中y的误差的分布也就由y的平均值决定了,这一点倒是和逻辑回归模型异曲同工。
对比普通线性模型,逻辑回归模型,以及泊松回归模型,我们可以发现这几个模型除了等式左边形式不同,当因变量取特定值时,这些模型所假设的y的随机分布形式也不一样,如下图:
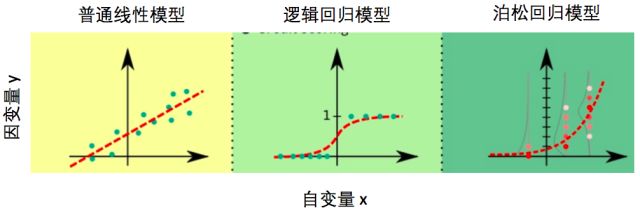
图二:普通线性模型,逻辑回归模型,以及泊松回归模型的对比。图中红色虚线代表模型预测的因变量y的平均值,图中的点代表了实际数据值,泊松回归模型中的灰色细线代表了特定自变量取值下因变量y的分布。
广义线性模型绕不开的联系函数(link function)
说完了随机性,下面再来看看广义线性模型的最后一个要素:联系函数。联系函数是啥?它是一个关于因变量y的函数,它把前面说到的线性预测的结果与因变量y的值之间建立一座桥梁。在学习统计的人看来,它就是广义线性模型中那个最匪夷所思最麻烦的一项:
它是逻辑回归中的
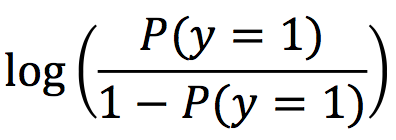
它是定序回归中的
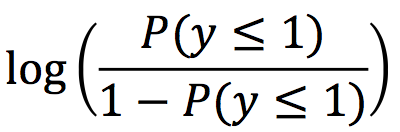
它是泊松回归中的
在我们最熟悉的普通线性回归中,它就是y本身,是最朴实的联系函数。从这个角度,普通线性模型也被包含在里广义线性模型的框架底下,只是使用的联系函数以及对于y的随机性假设与其它广义线性模型不同。
联系函数为什么会在各个模型中具有不同的形式?首先,是为了把y的取值范围变换成负无穷到正无穷,这样就与模型中等式右边的线性预测项的取值范围一致了。当然,对于任意类型的因变量y,符合上面这个条件的变换都可以有无数个,那为什么我们会取上面这些特定的形式呢? 在理论层面上,当y是二项分布时,使用逻辑函数作为联系函数,能够使得模型有一些有效的解法;当y是泊松分布的情况下,使用对数函数作为联系函数,也有同样的效果。在实际应用中,上面提到的联系函数形式也常常能有效地拟合数据,这些原因综合导致了它们是最常用的联系函数形式。
上面罗列的理由只能说明这些常见的联系函数使用起来比较方便,但并非是说它们是唯一合法的联系函数。在以后读者们在接触到更多的广义线性模型的时候,看到新的联系函数不要被吓到,虽然形式可能很复杂,但是功能不外乎是让y的取值范围与预测值范围一致,以及让模型比较好地拟合当下的数据。
一个实用的广义线性模型总结
最后,我们用一张表格来总结各种不同的线性模型。在表中,我们把普通线性模型看做是广义线性模型的一个特例。
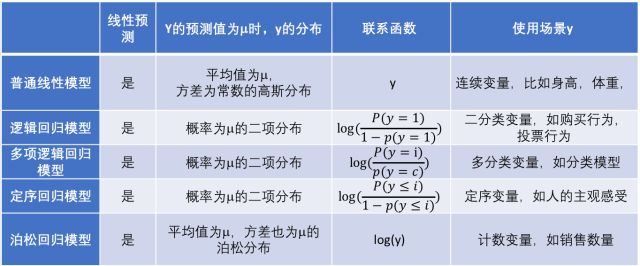
图三:常用线性模型小结
一个吃货的线性模型总结
最后,作为一个吃货,竟然觉得线性模型与火锅有一种神似,在这里和大家分享一下。总有一款线性模型适合你的数据,就像总有一种火锅能打动你。数据就像是火锅的食材,而选择哪款线性模型就像是选择汤底。我们都知道,汤底得按照食材的特性选择,才能释放出食材的全部美味。
对于新鲜又质量上层的肉片,清淡一点的汤底能更好得带出食材的香味,就像当因变量属于正常正态分布的数据时,选用普通线性模型就能得到良好的效果;对于本身味道比较重的食材,比如毛肚百叶等,经过麻辣的汤底的洗涤再放到嘴里简直爽到飞起,就像当因变量是二元变量或计数变量时,用逻辑回归模型或者泊松回归模型才能较好地拟合数据。
吃火锅时汤底是很关键,但蘸料的妙用也会锦上添花,极大地提高食物的美味程度。联系函数之于广义线性模型,就如蘸料之于火锅。蘸料一般选择基本款就可以了,就像根据因变量y的分布,联系函数的选择也有一些万能基本款,遇到特殊问题的时候,也可以灵活变通,选择使用「口味」更适合的联系函数。
相关文章

线性模型(一)--广义线性模型(GLM)简介

广义线性模型(GLM)初级教程
广义线性模型(Generalized Linear Model)之二:Logistic回归
广义线性模型(GLM)及其应用

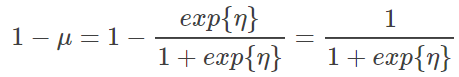
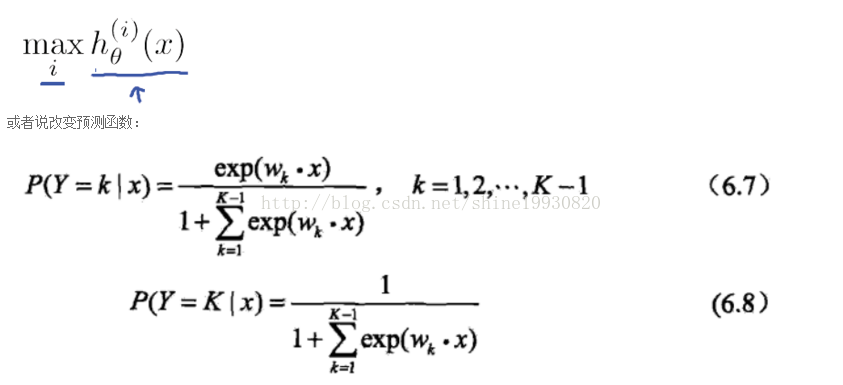
广义线性模型--Generalized Linear Models
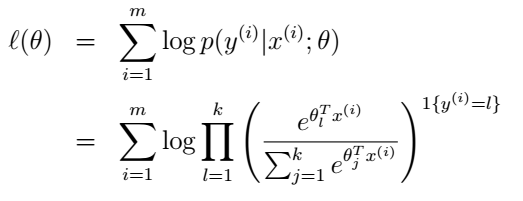
广义线性模型(Generalized Linear Models, GLM)

广义线性模型(Generalized Linear Model)——机器学习

广义线性模型和线性回归

机器学习之广义线性模型



第5章 广义与一般线性模型