本文分为两个部分: (1)广义线性模型的分类及其运用场景; (2) 相关R代码。需要说明的是,参考资料是上课课件,根据本人理解整理,如果有不对的地方,欢迎探讨!
目录
引言
1. 广义线性模型
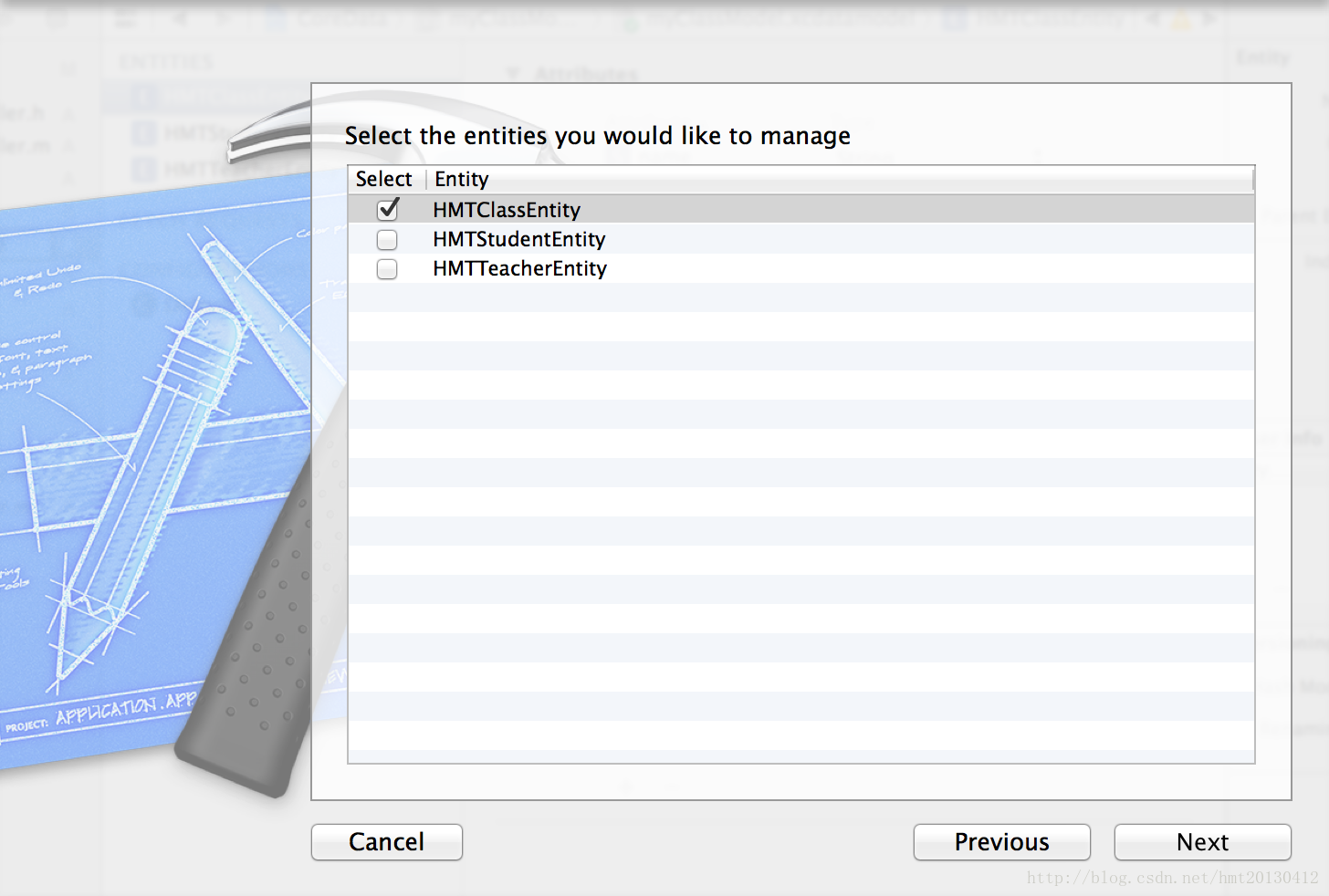
(1)二分变量
(2)类型变量
(3)计数型变量
①泊松对数线性模型
②零膨胀计数模型
2. 相关R代码
引言
在经典线性模型中,y是连续的,同时服从正态分布。但是很多情况下y是离散的,比如y表示是否贷款(0/1变量),或者优/良/差(类型变量),或者医院病人数(计数型变量)。所以引入了广义线性模型来进行回归拟合。
1. 广义线性模型

图1
(1)二分变量
当y为0/1二分变量的时候,可以用logistic模型进行回归拟合,模型设定如下:
设
服从参数为
的二项分布,则
,采用逻辑连接函数,即:
也可以用probit模型进行回归拟合,模型设定如下:
设
在得到回归结果 之后,两个模型的区别在于
logistic模型中
probit模型中
(2)类型变量
当y有多个类型,比如优/良/差的时候,可以用多项logit模型,模型设定如下:
假如对于第i个观测值,因变量
,则多项logit回归模型为
同时,
最终得到的结论是第 i 个样本为 的概率
(3)计数型变量
①泊松对数线性模型
当y服从泊松分布的时候,可以用此模型,模型设定如下:
设y服从参数为λ的泊松分布,则
采用对数连接函数,即
最终得到
为了更加方便解释y,上式可以变形为:
表示的意思是,每当 上升一个单位,就有
,则说明y变动了
②零膨胀计数模型
当y含有非常多0,分布右偏的时候,用泊松对数线性模型可能产生偏差,可以用零膨胀计数模型,模型设定如下:
设y服从参数为λ的泊松分布,则有
,但是
可能比较大,这种分布的数据叫做 “零膨胀数据”,需要用零膨胀计数模型进行拟合,模型可以分为两个部分:
(i) 零点处:用 logistic模型或者probit模型进行拟合
假设零点的点密度为
,那么此处logistic模型的设定为
或者此处的probit模型的设定为
(ii) 非零点处:用泊松分布模型进行拟合
则非零处的
综上,零膨胀密度为:
其中,
为(i)中的模型设定,
为(ii)中的模型设定;
进一步地,整个模型的均值为:
2. 相关R代码
# 数据介绍:被解释变量为y,解释变量为x1,x2,x3,
# 其中x1是连续数值变量;x2是0/1变量,x3是分类变量(即取值为1,2,3)#1 读入数据
setwd("C:/...")
dat <- read.csv("file.csv", header = T)#2 数据检查 ##1) 检查一下响应变量分布情况
barplot(table(dat$y))##2) 解释变量是分类变量的时候,需要进行因子化
dat_x3 <- as.factor(dat$x3)#3 选择模型回归并查看结果##1) logistic模型
glm_logit <- glm(y~x1+x2+x3, family=binomial(link=logit), data=dat)
summary(glm_logit) #输出结果
y1<-predict(glm_logit, data.frame(x1=20,x2=1,x3=1))
p1<-exp(y1)/(1+exp(y1)) #估计x1=20,x2=1,x3=1时y=1的概率##2) probit模型
glm_probit<- glm(y~x1+x2+x3, family=binomial(link=probit), data=dat)
summary(glm_probit) #输出结果
#估计满足条件时y=1的概率y2 <- predict(glm_probit, data.frame(x1=20,x2=1,x3=1),type="response") ##3) 多项probit模型
mlog<-multinom(y~x1+x2+x3,data=dat) #建立模型
summary(mlog)
predict(mlog,data.frame(x1=20,x2=1,x3=1),type="p") #估计y=1,2,...,M的概率##4) 泊松对数线性模型
glm_ln<-glm(y~x1+x2+x3,family=poisson(link=log),data=dat)
summary(glm_ln)
exp(coef(glm_ln)) # 计算因变量为y而不是lny时变量的系数##5) 零膨胀计数模型
#[|]前是非零设定模型,后面是零值时设定的模型
glm_zero <- zeroinfl(y~x1+x2+x3|y~x1+x2+x3,data=dat)
summary(glm_zero )#备注:优化模型
#如果出现某个变量不太显著的问题,可以用逐步回归优化,假设之前回归结果为 fx1
fx1_step <- step(fx1)如果你看到这里了,可以给个赞吗,辛苦码字2小时耶!