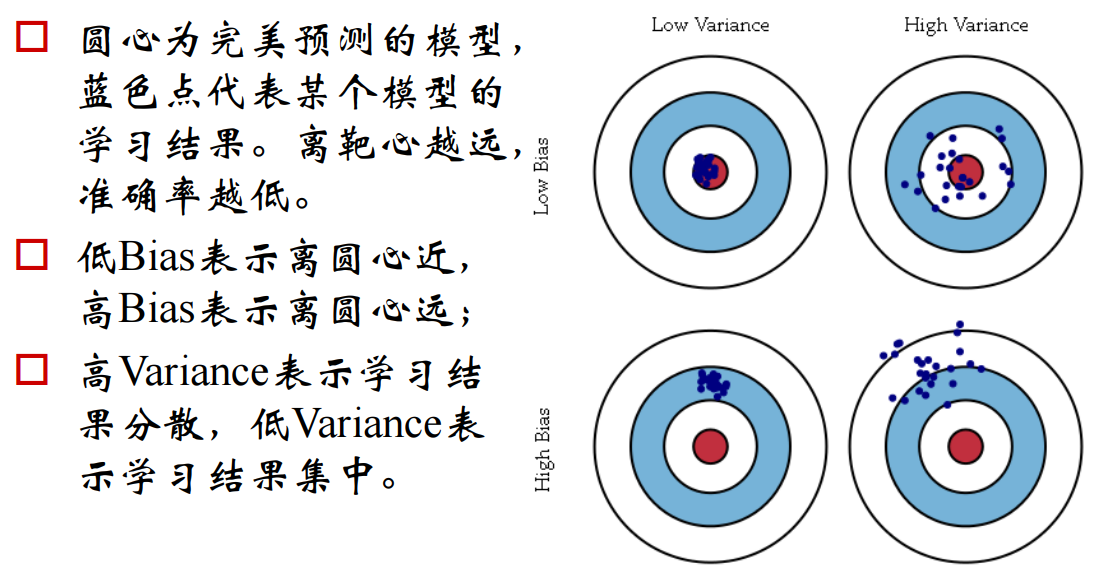
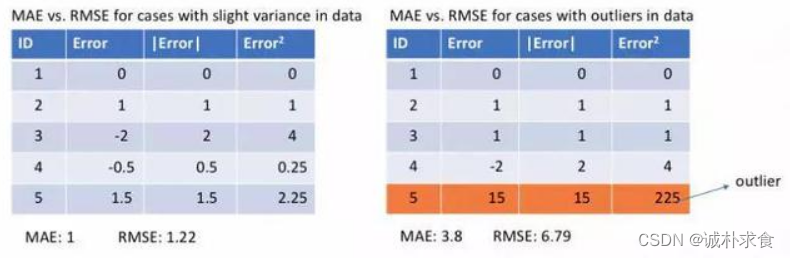
https://sklearn.apachecn.org/docs/master/30.html
学习预测函数的参数,并在相同数据集上进行测试是一种错误的做法: 一个仅给出测试用例标签的模型将会获得极高的分数,但对于尚未出现过的数据它则无法预测出任何有用的信息。 这种情况称为 overfitting(过拟合). 为了避免这种情况,在进行(监督)机器学习实验时,通常取出部分可利用数据作为 test set(测试数据集)
X_test, y_test。利用 scikit-learn 包中的
train_test_split辅助函数可以很快地将实验数据集划分为任何训练集(training sets)和测试集(test sets)。当评价估计器的不同设置(”hyperparameters(超参数)”)时,例如手动为 SVM 设置的
C参数, 由于在训练集上,通过调整参数设置使估计器的性能达到了最佳状态;但 在测试集上 可能会出现过拟合的情况。
- 测试集上的信息反馈足以颠覆训练好的模型,评估的指标不再有效反映出模型的泛化性能。 为了解决此类问题,还应该准备另一部分被称为 “validation set(验证集)” 的数据集,模型训练完成以后在验证集上对模型进行评估。 当验证集上的评估实验比较成功时,在测试集上进行最后的评估。
- 然而,通过将原始数据分为3个数据集合,我们就大大减少了可用于模型学习的样本数量, 并且得到的结果依赖于集合对(训练,验证)的随机选择。
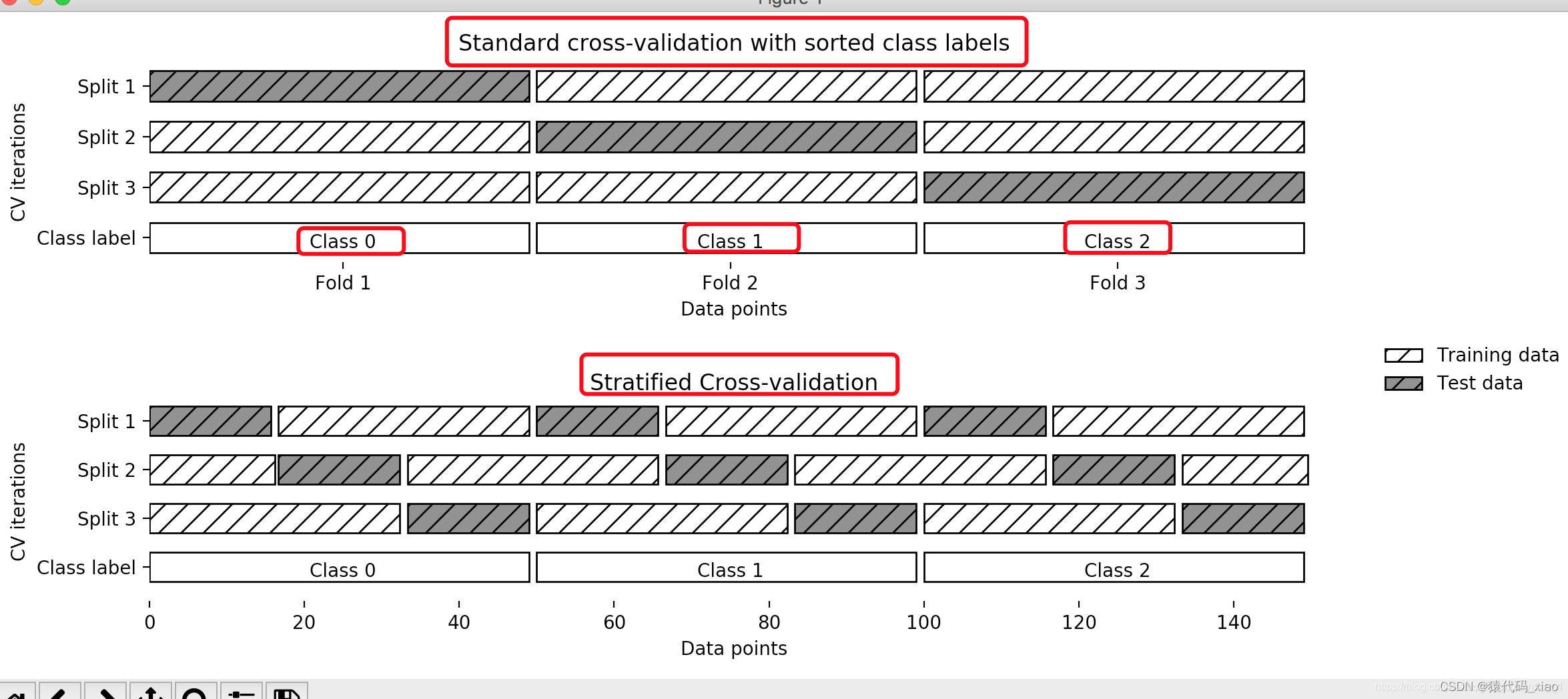
- 这个问题可以通过 交叉验证(CV ) 来解决。 交叉验证仍需要测试集做最后的模型评估,但不再需要验证集
最基本的方法被称之为,k-折交叉验证 。 k-折交叉验证将训练集划分为 k 个较小的集合(其他方法会在下面描述,主要原则基本相同)。 每一个 k 折都会遵循下面的过程:
- 将K-1份训练集子集作为 training data (训练集)训练模型,
- 将剩余的 1 份训练集子集用于模型验证(也就是把它当做一个测试集来计算模型的性能指标,例如准确率)。
k-折交叉验证得出的性能指标是循环计算中每个值的平均值。 该方法虽然计算代价很高,但是它不会浪费太多的数据(如固定任意测试集的情况一样), 在处理样本数据集较少的问题(例如,逆向推理)时比较有优势。
使用交叉验证最简单的方法是在估计器和数据集上调用cross_val_score辅助函数。例如:
随机排列交叉验证 a.k.a. Shuffle & Split
ShuffleSplit
ShuffleSplit迭代器 将会生成一个用户给定数量的独立的训练/测试数据划分。样例首先被打散然后划分为一对训练测试集合。可以通过设定明确的
random_state,使得伪随机生成器的结果可以重复。这是一个使用的小示例:
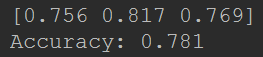
>>> from sklearn.model_selection import ShuffleSplit>>> X = np.arange(5)>>> ss = ShuffleSplit(n_splits=3, test_size=0.25,... random_state=0)>>> for train_index, test_index in ss.split(X):... print("%s %s" % (train_index, test_index))...[1 3 4] [2 0][1 4 3] [0 2][4 0 2] [1 3]下面是交叉验证行为的可视化。注意ShuffleSplit不受分类的影响。
我们不能使用测试集(X_test)来进行参数和模型调优。容易“过拟合”。总之,“测试集”(X_test)只能在最后一次模型评价中使用!那么,就有了下面的“交叉验证”!
交叉验证
一般,如果给定的样本数据充足,我们会随机的从“训练集”(X_train)中提取一部分数据来调优,这个数据集叫做“验证集”(X_validation)。
但是,如果数据不充足,我们往往采用“交叉验证”的方法——把给定的数据进行切分(例如分成5段),将切分的数据集分为“训练集”和“验证集”(假设其中4份为train,1份为validation),在此基础上循环选取(4份为train,1份为validation),进行训练和验证。从而选择其中最好的模型。
交叉验证:重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。交叉验证用在数据不是很充足的时候。
交叉验证的作用
- 交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合
- 可以从有限的数据中获取尽可能多的有效信息
交叉验证常见形式
- 简单交叉验证:随机将样本数据分为两部分(比如: 80%的训练集,20%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,我们再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
- K折交叉验证:K折交叉验证会把样本数据随机的分成K份,每次随机的选择K-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择K-1份来训练数据。若干轮(小于K)之后,选择损失函数评估最优的模型和参数。
- 留一交叉验证(leave-one-out cross validation):它是第二种情况的特例,此时K等于样本数N,这样对于N个样本,每次选择N-1个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况,比如对于普通适中问题,N小于50时,我一般采用留一交叉验证。
ps:实际运用中,因为交叉验证会耗费较多的计算资源(毕竟一直循环选取,然后训练,验证)。所以一般数据充足,直接随机选取一小部分作为“验证集”就行了。(tips:一定要随机,因为如果原来的数据集排列有一定的规律,例如前100全是A类,后100全是B类,那么你只是简单的用语句X_val = X[150:],得到的就只有B类了。当然,如果样本本来就是随机分布的,那就没关系。)
k折交叉验证
K折交叉验证中,不重复地随机将训练数据集划分为K个,其中k-1个用于模型的训练,剩余的1个用于测试。重复此过程k次,就得到了k个模型及对模型性能的评价。该种方法对数据划分的敏感性较低。
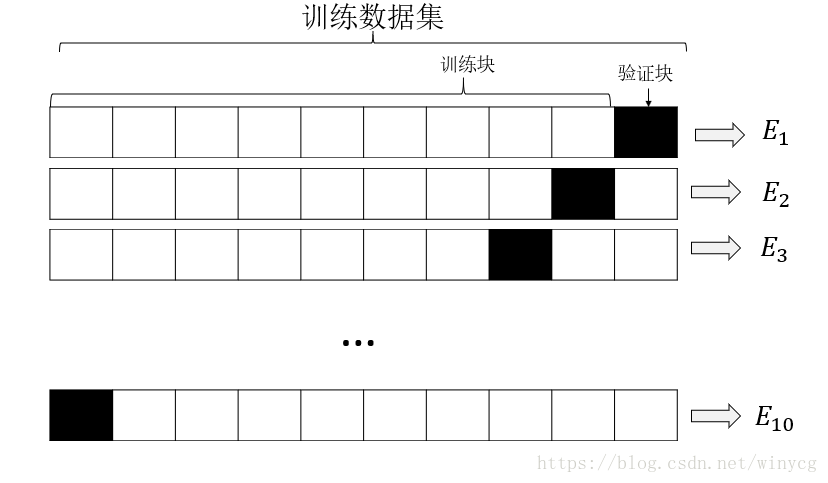
下图展示了k折交叉验证,k=10,训练数据集被划分为10块,在10次迭代中,每次迭代中都将9块用于训练,剩余的1块用于模型的评估。10块数据集作用于某一分类器,分类器得到的性能评价指标为Ei,i=1,2,⋯,10Ei,i=1,2,⋯,10,可用来计算模型的估计平均性能110∑10i=1Ei110∑i=110Ei
K折交叉验证中k的标准值为10,对大多数应用来说都时合理的。如果训练集相对较小,可以增大k值,这样将会有更多的数据用于进行训练,这样性能的评估结果也会得到较小的偏差。但是k值得增加会导致交叉验证算法的时间延长,并使得训练块高度相似,无法发挥交叉验证的效果。如果数据集较大,可以选择较小的k值,降低在不同数据块的重复计算成本,同时训练快比例小但是依然有大量的训练数据。
注:这次只是初步了解。