Python 交叉验证模型评估
1 声明
本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。
2 交叉验证模型评估简介
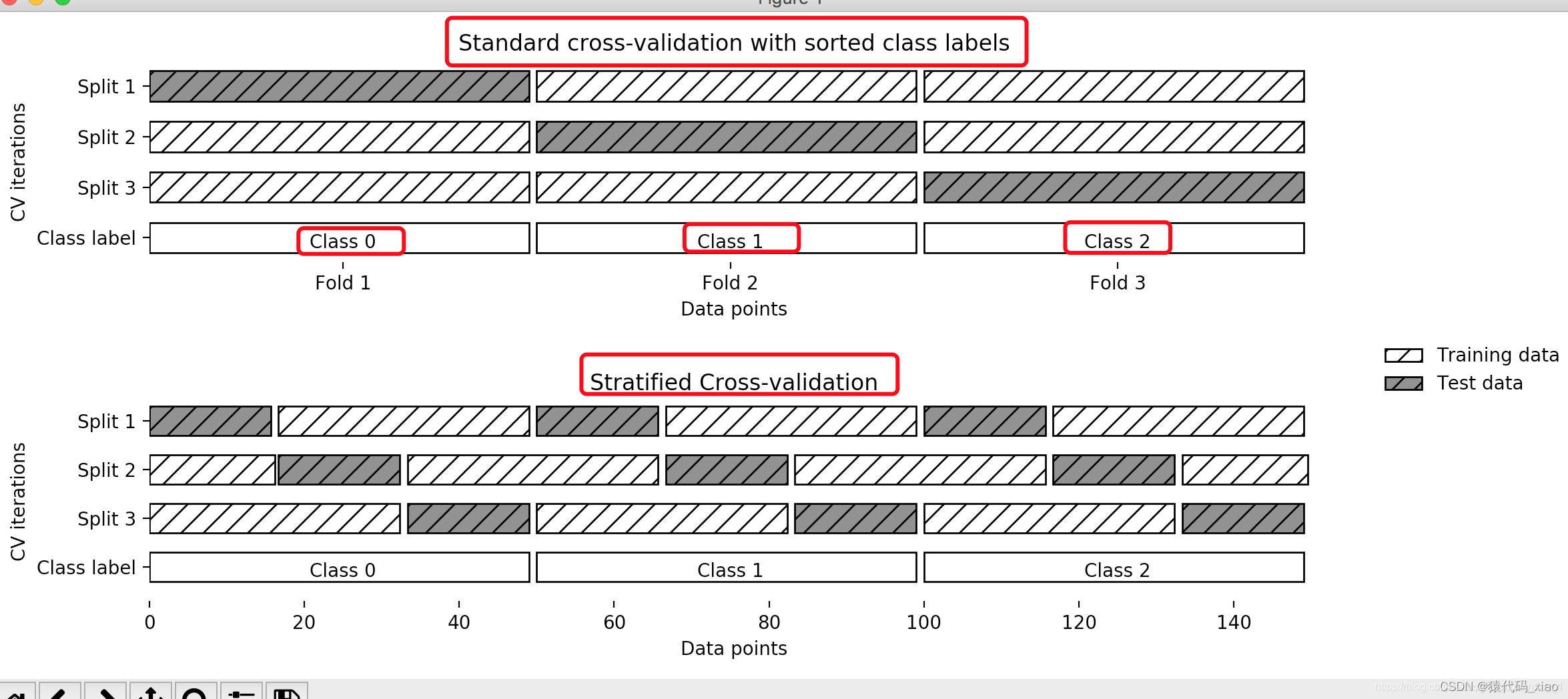
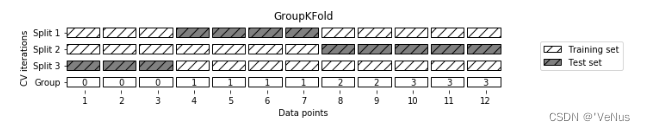
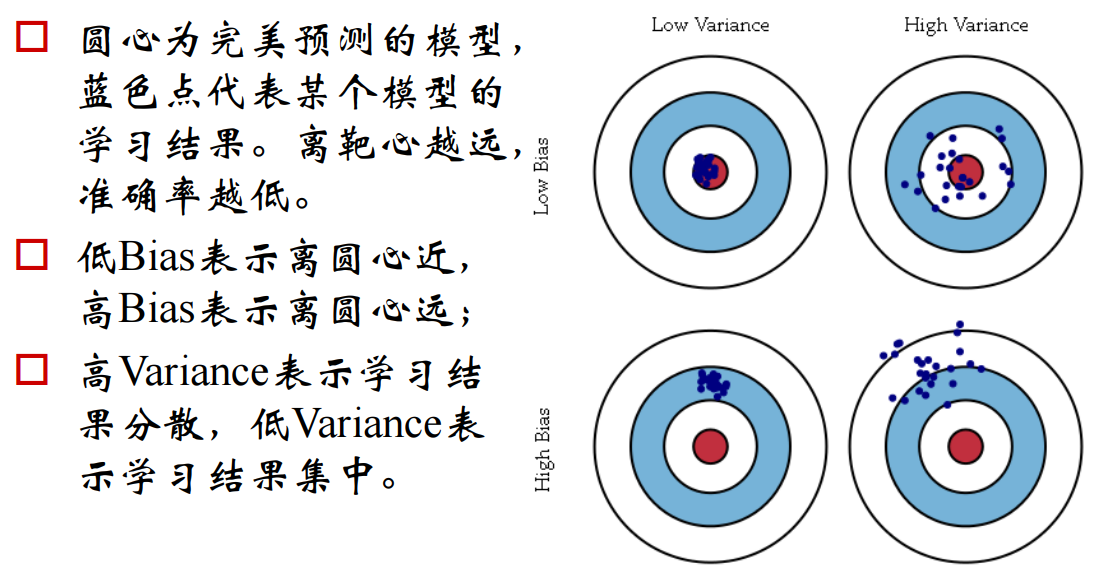
交叉验证(Cross Validation)是机器学习里模型评估的常见方法,它用于检查模型的泛化能力。计算过程是将数据分为n 组,每组数据都要作为一次验证集进行一次验证,而其余的 n-1 组数据作为训练集。这样一共要循环 n 次,得到 n 个模型。通过对这些模型的误差计算均值,得到交叉验证误差。
3 交叉验证模型评估代码示例
from numpy import nan
from pandas import read_csv
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
# 加载数据集
dataset = read_csv('../input/pima-indians-diabetes.csv', header=None)
# 用0替换空值
dataset[[1,2,3,4,5]] = dataset[[1,2,3,4,5]].replace(0, nan)
# 删除缺失值
dataset.dropna(inplace=True)
# 定义X和y
values = dataset.values
X = values[:,0:8]
y = values[:,8]
# 用LDA定义模型
model = LinearDiscriminantAnalysis()
# 定义模型评估的方法(n_splits即训练集被分的份数)
cv = KFold(n_splits=3, shuffle=True, random_state=1)
# 评估模型(按照accuracy排序)
result = cross_val_score(model, X, y, cv=cv, scoring='accuracy')
# 打印模型表现
print(result)
print('Accuracy: %.3f' % result.mean())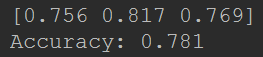
4 总结
无