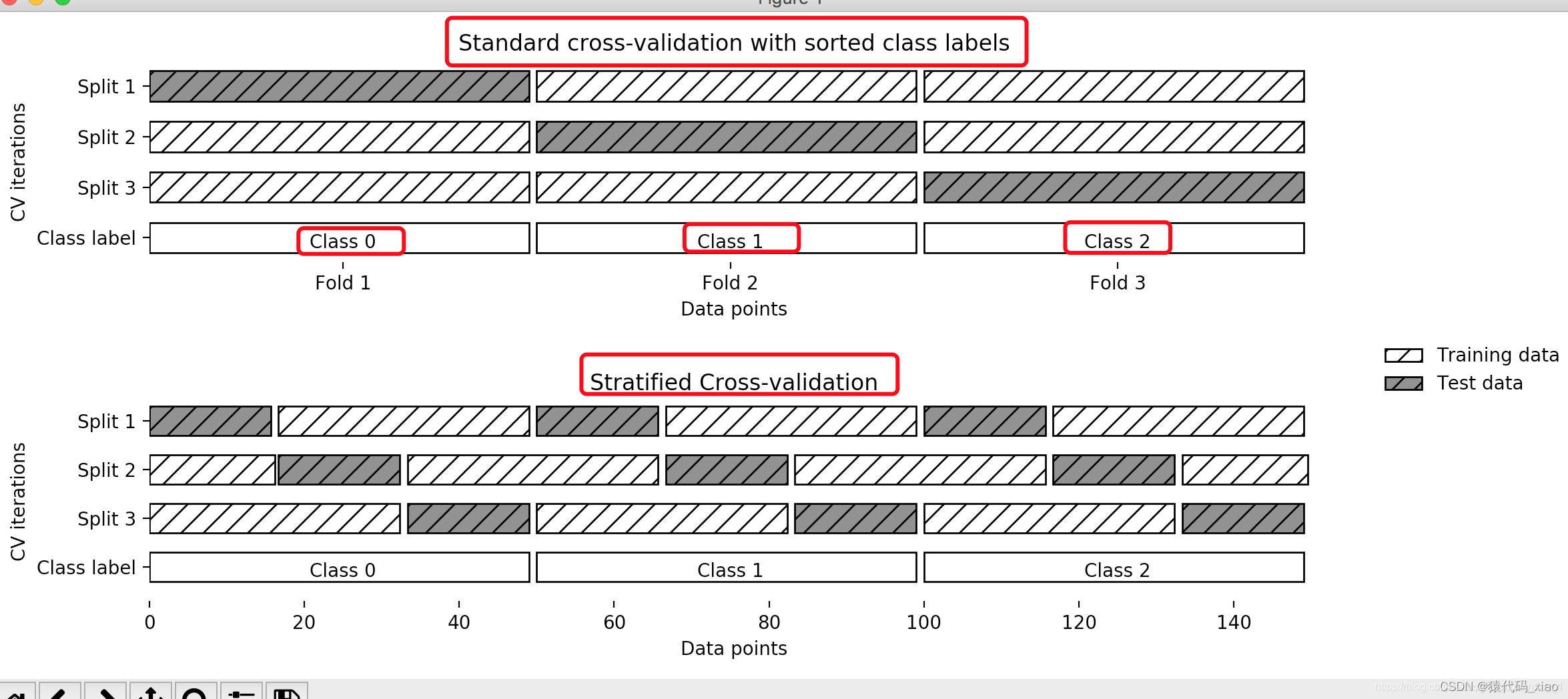
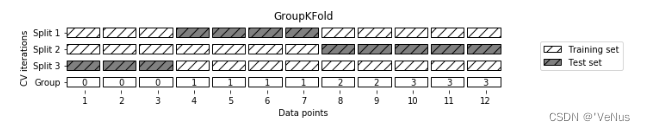
交叉验证
另一种常用的模型选择方法是交叉验证( cross validation)。
如果给定的样本数据充足,进行模型选择的一种简单方法是随机地将数据集切分成三部分,分别为训练集(training set)、验证集(validation set)和测试集(testset)。训练集用来训练模型,验证集用于模型的选择,而测试集用于最终对学习方法的评估。在学习到的不同复杂度的模型中,选择对验证集有最小预测误差的模型。由于验证集有足够多的数据,用它对模型进行选择也是有效的。
但是,在许多实际应用中数据是不充足的。为了选择好的模型,可以采用交叉验证方法。交叉验证的基本想法是重复地使用数据;把给定的数据进行切分,将切分的数据集组合为训练集与测试集,在此基础上反复地进行训练、测试以及模型选择。
1.简单交叉验证
简单交叉验证方法是:首先随机地将已给数据分为两部分,一部分作为训练集,另一部分作为测试集(例如,70%的数据为训练集,30%的数据为测试集);然后用训练集在各种条件下(例如,不同的参数个数)训练模型,从而得到不同的模型
在测试
集上评价各个模型的测试误差,选出测试误差最小的模型。
2.S折交叉验证
应用最多的是S折交叉验证(S-fold cross validation),方法如下:首先随机地将已给数据切分为S个互不相交、大小相同的子集;然后利用S-1个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的S种选择重复进行;最后选出S次评测中平均测试误差最小的模型。
3.留一交叉验证
S折交叉验证的特殊情形是S =N,称为留一交叉验证(leave-one
out crOss
validation),往往在数据缺乏的情况下使用。这里,N是给定数据集的容量
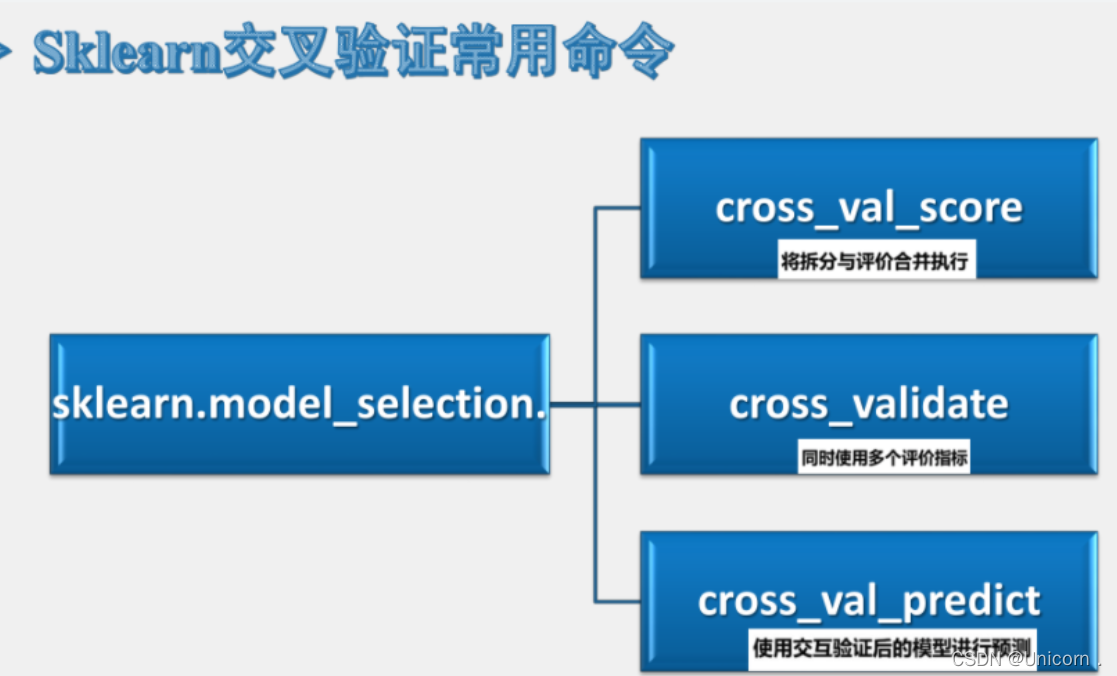
1.将拆分和评估合并执行
from sklearn import model_selection
from sklearn.datasets import load_boston
boston=load_boston()
from sklearn.linear_model import LinearRegression
reg=LinearRegression()
from sklearn.model_selection import cross_val_score
scores=cross_val_score(reg,boston.data,boston.target,cv=10)#boston.data,boston.target,x和y ,cv拆分几次
scores
array([ 0.73376082, 0.4730725 , -1.00631454, 0.64113984, 0.54766046,0.73640292, 0.37828386, -0.12922703, -0.76843243, 0.4189435 ])
scores.mean(),scores.std()
(0.20252899006056194, 0.5952960169512286)
scores=cross_val_score(reg,boston.data,boston.target,scoring='explained_variance',cv=10)
scores
array([ 0.74784412, 0.5381936 , -0.80757662, 0.66844779, 0.5586898 ,0.74128804, 0.41981565, -0.11666214, -0.44561819, 0.42197365])
scores.mean(),scores.std()
(0.27263956979413645, 0.5131020457665374)
2.保证案例顺序的随机性

#对数据进行随机重排,保证拆分的均匀性
import numpy as np
X,y=boston.data,boston.target
indices=np.arange(y.shape[0])
np.random.shuffle(indices)
X,y=X[indices],y[indices]
from sklearn.linear_model import LinearRegression
reg=LinearRegression()
from sklearn.model_selection import cross_val_score
scores=cross_val_score(reg,X,y,cv=10)
scores
array([0.66242457, 0.74213001, 0.73590188, 0.79634624, 0.56973987,0.69967033, 0.69324636, 0.57360763, 0.70584966, 0.8325531 ])
scores.mean(),scores.std()
(0.7011469635197446, 0.08021111886104514)
3.同时使用多个评价指标

from sklearn.model_selection import cross_validate
scoring=["r2",'explained_variance']
scores=cross_validate(reg,X,y,cv=10,scoring=scoring,return_train_score=False)
scores
{'fit_time': array([0.00225925, 0.00149512, 0.00085235, 0.00100565, 0. ,0.00107932, 0.00061202, 0.00142884, 0. , 0. ]),'score_time': array([0.00052142, 0. , 0.00120974, 0.00099659, 0.00137043,0.00175881, 0. , 0. , 0.00099969, 0.00099397]),'test_r2': array([0.66242457, 0.74213001, 0.73590188, 0.79634624, 0.56973987,0.69967033, 0.69324636, 0.57360763, 0.70584966, 0.8325531 ]),'test_explained_variance': array([0.66401786, 0.75721853, 0.73863241, 0.79800809, 0.61098039,0.70935696, 0.71851602, 0.5946434 , 0.70776645, 0.83265924])}
from sklearn.model_selection import cross_validate
scoring=["r2",'explained_variance']
scores=cross_validate(reg,X,y,cv=10,scoring=scoring,return_train_score=True)
scores
{'fit_time': array([0.00160408, 0.00049663, 0.00055194, 0.00099707, 0.00105953,0.0012486 , 0. , 0.00099659, 0.00099707, 0.00099683]),'score_time': array([0.00094795, 0.0010004 , 0. , 0.00099659, 0.00122499,0.00109267, 0.00099659, 0.00099683, 0. , 0. ]),'test_r2': array([0.66242457, 0.74213001, 0.73590188, 0.79634624, 0.56973987,0.69967033, 0.69324636, 0.57360763, 0.70584966, 0.8325531 ]),'train_r2': array([0.74675463, 0.73829966, 0.7393989 , 0.7289949 , 0.76099556,0.74509271, 0.74245879, 0.74721245, 0.74307661, 0.72665402]),'test_explained_variance': array([0.66401786, 0.75721853, 0.73863241, 0.79800809, 0.61098039,0.70935696, 0.71851602, 0.5946434 , 0.70776645, 0.83265924]),'train_explained_variance': array([0.74675463, 0.73829966, 0.7393989 , 0.7289949 , 0.76099556,0.74509271, 0.74245879, 0.74721245, 0.74307661, 0.72665402])}
scores['test_r2'].mean()
0.7011469635197446
4.使用交叉验证的模型进行预测

from sklearn.model_selection import cross_val_predict
pred =cross_val_predict(reg,X,y,cv=10)
pred[:10]
array([18.3620206 , 12.14422565, 25.59073795, 20.73126557, 23.17191087,14.50564224, 20.58260498, 18.95012499, 36.99725954, 13.52825238])
from sklearn.metrics import r2_score
r2_score(y,pred)
0.7148847512596024