先看看度娘给出的定义吧:
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。这一类问题近几年来反复出现在信息学的国际国内赛题中。其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受;即使在空间上勉强通过,运行的时间复杂度也极高,根本就不可能在比赛规定的运行时间(1~3秒)内计算出试题需要的结果,只能用并查集来描述。
总结一下:
如果我们有大量的元素集合,我们需要频繁的调用以下两个操作:
- 将两个元素区间合并
- 判断两个元素是否在一个集合
如果我们没有并查集,那在面对大量数据下,执行这两个操作的时间复杂度将会很高
而如果我们使用并查集这个结构,虽然单次操作的时间复杂度可能为O(n),但如果我们频繁地调用这两个函数,平均下来的时间复杂度可达到O(1)
这个结论我们不证明,(毕竟大佬都证明了20多年才证出来,我咋可能在这么短的时间证出来(小声))
咳咳,总言而之,大家把上面的结论记住就行了
并查集这种结构可以很好的解决一些需要统计集合个数的题目
目录
- 并查集的实现
- 并查集应用
- 力扣547,省份数量
- 力扣200,岛屿数量
并查集的实现
先给出一个定义:
指针指向自己的结点,我们把它叫做这个集合的代表结点,它是作为标识集合的最顶点(父结点)存在的
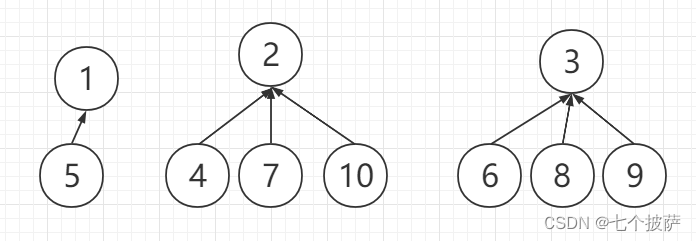
假如我们有一个整数数组,我们需要实现成并查集

我们在初始化的时候,我们先把每个元素都看做一个单独的集合
也就是出一个指针,指向自己

这样就完成了我们的初始化,也就是每个元素的代表结点都是它本身
所以,我们判断元素是否来自同一个集合就很简单了,直接判断它们的代表结点是否相同即可
合并的操作如下:
现在这种情况,假如我们要合并1,2这两个元素所在的集合,我们可以把其中某个元素集合的父节点挂在另外一个父结点就行了
我们不妨把2挂在1上面

这样我们就完成了一次元素合并
假如我们这次要把2和3合并在一起,怎么做?
同样的,把其中一个集合的父节点挂在另外一个元素的父节点就行了
但这种情况,需要注意,为了加快效率,我们通常把小集合的父节点挂在大集合的父节点上
就像这样

但这个过程中,我们还需要一些操作
比如怎么找到某个元素所在集合的代表节点?怎么实现快速查找代表结点?在下面的代码实现中详细介绍
我们需要以下结构来实现:
一个记录元素关键结点下标位置的数组,一个记录当前元素所在集合的大小,还需要记录当前集合的个数
vector<int>parent;//记录此位置的关键结点,比如:parent[i]=a,代表i下标的元素在a处
vector<int>size;//记录关键结点所在集合的大小,只对关键结点有效,非关键结点设为0
vector<int>help;//辅助数组,后面做介绍
int sets;//记录当前并查集集合个数
初始化时,我们需要知道并查集初始有多少个元素,根据初始每个元素一个集合这个设定,可以快速写出以下初始化代码:
int n = nums.size();//我们的数组中有多少个元素,初始就开多少集合
parent.resize(n);
size.resize(n);
help.resize(n);
sets = n;for (int i = 0; i < n; i++)
{parent[i] = i;//关键结点为自己size[i] = 1;//集合大小为1
}
因为上面的操作中,需要频繁的查找关键结点的位置,所以还需要实现一个查找关键结点位置的函数
原理很简单:
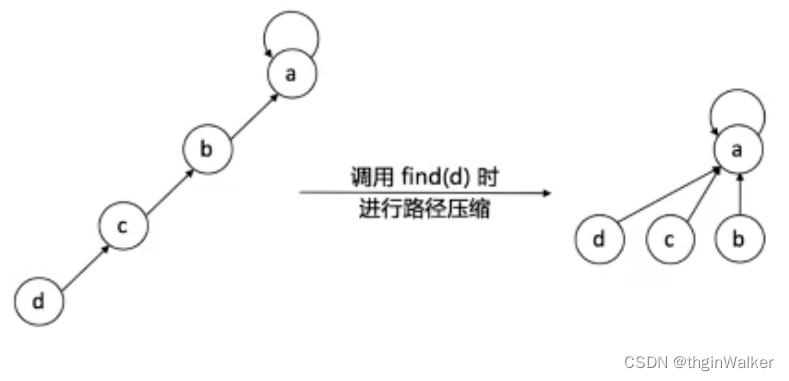
如果某个元素的parent[i]记录的下标不是元素本身的下标,就代表此结点不是代表结点,我们就通过parent数组记录的位置找到那个下标,不断迭代,直到找到关键结点为止
//这个函数最后返回当前下标中元素的代表结点下标int findfather(int i){while (i != parent[i]){i = parent[i];}return i;}
但在某种极端情况下,这样频繁的调用的话,每次调用的时间复杂度都为O(n)
比如:元素都在一条链上,组成了一个类似链表的结构,我们从最下面的元素查找

如果我们不做任何优化的话,时间复杂度平均下来还是O(n)
我们可以做压缩路径的优化:
具体实现如下:
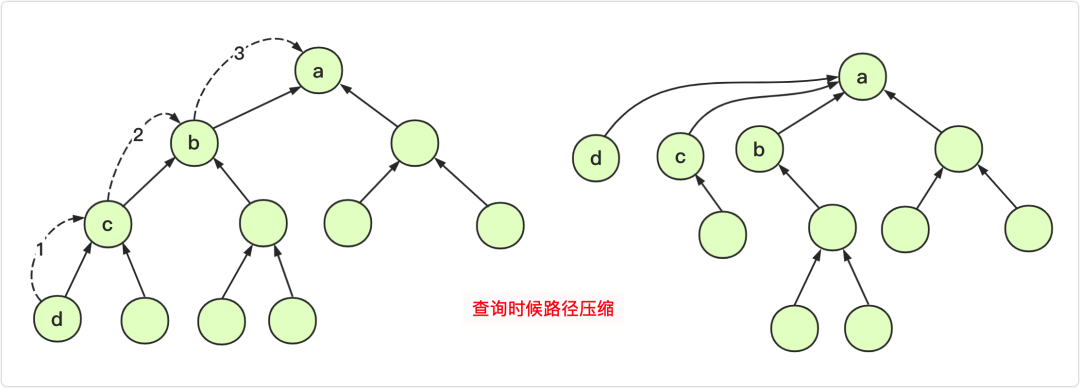
我们每次遍历时,把元素存在help数组中,就像下面

然后进行路径压缩,我们把依次弹出help中的每个元素,然后把每个元素的代表结点都设为当前返回值

这样每个元素就全部指向唯一的代表结点了
总结:
前面提到的help数组在这里当做栈来使用
虽然单次查找的时间复杂度可能是O(n),但经过了我们的路径压缩后,以后如果重复查找这个集合中的元素的话,时间复杂度就为O(1)
因为我们的前提是大量重复操作,所以平均下面,时间复杂度还是O(1)
完整的查找代表结点代码:
int findfather(int i){int hi = 0;while (i != parent[i]){help[hi++] = i;i = parent[i];}for (hi--; hi >= 0; hi--)//记住先--{parent[help[hi]] = i;//路径压缩操作help[hi] = 0;}return i;}
接下来我们来实现文章开头提到的两个方法
注意:我们使用这两个方法时,参数传原数组中的下标
查找是否为相同元素就很简单了,直接判断相等即可
bool isSameFather(int i, int j){return findfather(i) == findfather(j);}
合并时的操作如下
先分别找出元素所在集合的代表结点
int A = findfather(i);
int B = findfather(j);
这时判断一下,如果A=B,代表两个元素来自同一集合,就不需要进行合并操作,直接函数退出即可
因为我们是将小集合挂在大集合上,所以我们需要判断一下A,B中哪个是大集合
int big = size[A] >= size[B] ? A : B;
int small = big == A ? B : A;
然后执行合并操作:改变代表结点位置,改变size值,改变集合个数等
parent[small] = big;
size[big] += size[small];
size[small] = 0;
sets--;//合并一个就代表并查集中集合少了一个
大多数情况下,我们可能还需要返回并查集中元素的个数
int getSets(){return sets;}
完整代码如下
class Union2
{
public:Union2(vector<int>& nums){int n = nums.size();parent.resize(n);size.resize(n);help.resize(n);sets = n;for (int i = 0; i < n; i++){parent[i] = i;size[i] = 1;}}bool isSameFather(int i, int j){return findfather(i) == findfather(j);}int getSets(){return sets;}void together(int i, int j)//传的是下标{int A = findfather(i);int B = findfather(j);if (A != B){int big = size[A] >= size[B] ? A : B;int small = big == A ? B : A;parent[small] = big;size[big] += size[small];size[small] = 0;sets--;}}
private:vector<int>parent;//记录此位置的关键结点vector<int>size;//记录关键结点的位置vector<int>help;//做栈int sets;//记录集合个数int findfather(int i){int hi = 0;while (i != parent[i]){help[hi++] = i;i = parent[i];}for (hi--; hi >= 0; hi--)//记住先--{parent[help[hi]] = i;help[hi] = 0;}return i;}
};
另外再补充一下哈希表的实现,把哈希把当做指针结点来进行保存即可,其它无异
class Node
{
public:Node(int x):val(x){}private:int val;
};class Union
{private:unordered_map<int, Node*>node;//值和值对应的结点unordered_map<Node*, Node*>parent;//结点和其代表结点unordered_map<Node*, int>size;//代表结点和对应其集合大小Node* findfather(Node* n){stack<Node*>path;Node* cur = n;while (parent[cur] != cur){cur = parent[cur];path.push(cur);}if (!path.empty()){Node* now = path.top();parent[now] = cur;path.pop();}return cur;}public:Union(vector<int>& nums){for (auto i:nums){Node* n = new Node(i);node[i] = n;parent[n] = n;size[n] = 1;}}bool isSameUnion(int a, int b){return findfather(node[a]) == findfather(node[b]);}int setsize(){return size.size();}void together(int a, int b){Node* A = findfather(node[a]);Node* B = findfather(node[b]);if (A != B){Node* big = size[A] >= size[B] ? A : B;Node* small = A == big ? B : A;parent[small] = big;size[big] += size[small];size.erase(small);}}
};
并查集应用
力扣547,省份数量
原题链接
题目描述:
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
例如:输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]]
输出:2(因为1,2城市有联系,那么1,2其中一个就不是首都)
思路求解:
这道题是一个典型的并查集返回集合个数的问题
如果有0,1,2这三个城市,设0,1,2分别代表数组中的横纵坐标,如果它们之间有道路,则把它们在数组中的交点设为1,反之为0
我们可以得出数组的以下性质:对角线上元素恒为1,因为自己跟自己肯定有联系
此数组一定是一个对称矩阵,如果(1,2)之间有联系,那么(2,1)也必然有联系
所以我们在遍历时,只需要遍历数组对角线上面的元素即可
因为初始有行数个城市,所以我们初始化并查集时,只需传进行数大小即可,初始每个城市都是首都,也就是每个结点都是代表结点
如果遍历到有联系,合并这两个城市即可
代码如下:
class Union//并查集集合
{
public:Union(int n)//有多少城市就传入多少,初始假设每个城市都是首都{parent.resize(n);size.resize(n);help.resize(n);set=n;for(int i=0;i<n;i++){parent[i]=i;//初始的父亲结点指向自己size[i]=1;//每个集合仅有一个元素}}bool isSameFather(int i,int j)//观察是否属于同一个元素{return findFather(i)==findFather(j);}void together(int i,int j)//将两个元素的集合合并{int A=findFather(i);int B=findFather(j);//先找到它们的代表结点if(A!=B)//不等才操作{//为了提高效率,将小集合挂在大集合下面int big=A>=B?A:B;int small=big==A?B:A;parent[small]=big;//将代表结点改变即可size[big]+=size[small];size[small]=0;set--;}}int getSet(){return set;}private:vector<int>parent;//表示某个下标位置的父亲在哪里vector<int>size;//表示代表结点的集合个数vector<int>help;//在压缩路径时当做栈使用int set;//记录集合个数int findFather(int i)//传入下标,把代表结点的下标返回{int hi=0;while(parent[i]!=i)//判断当然元素的父亲是不是自己,是就停止,不是就迭代{help[hi++]=i;i=parent[i];}//进行路径压缩for(hi--;hi>=0;hi--){parent[help[hi]]=i;help[hi]=0;}return i;}
};class Solution {
public:int findCircleNum(vector<vector<int>>& isConnected) {int n=isConnected.size();Union u(n);for(int i=0;i<n;i++){for(int j=i+1;j<n;j++)//只需要遍历右上角的元素{if(isConnected[i][j]==1){u.together(i,j);}}}return u.getSet();}
};
力扣200,岛屿数量
原题链接
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
例如:
输入:grid = [
[“1”,“1”,“0”,“0”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“1”,“0”,“0”],
[“0”,“0”,“0”,“1”,“1”]
]
输出:3
思路求解
这题其实有一个递归感染法,不过不是本章重点,所以我只贴出代码,不详细讲解
class Solution {
public:void infect(vector<vector<char>>& grid,int r,int c){//感染的时候为了防止死递归,将数字都改为2if(r<0||c<0||r>=grid.size()||c>=grid[0].size()||grid[r][c]!='1'){return;}grid[r][c]='2';infect(grid,r-1,c);infect(grid,r+1,c);infect(grid,r,c-1);infect(grid,r,c+1);}int numIslands(vector<vector<char>>& grid) {//递归感染法int ans=0;int r=grid.size();int c=grid[0].size();for(int i=0;i<r;i++){for(int j=0;j<c;j++){if(grid[i][j]=='1'){ans++;infect(grid,i,j);}}}return ans;}
};
我们重点讲解这题的并查集实现方法
首先,设地图有row行,有col列,那么我们在初始化时可以开一个row*col的数组
我们可以把二维坐标转化为一维数组,转化公式如下:
int index(int i,int j)
{return i*col+j;
}
初始时,我们先遍历整个地图,只要有岛,就将其对应坐标初始化,初始时每个1都看做一个独立的岛
为了防止漏数,所以在我们遍历的时候,观察当然位置的左上位置是否有岛,有就合并
int index(vector<vector<char>>& grid,int i,int j)
{return i*grid[0].size()+j;
}class Union2
{
public:Union2(vector<vector<char>>& grid){//特别注意这题并查集的构造//把并查集转成一维数组,在二维数组下标对应位置存储元素,其它不做处理,遍历在每个1时才对并查集对应位置做处理int n=grid.size()*grid[0].size();parent.resize(n);size.resize(n);help.resize(n);sets=0;for(int i=0;i<grid.size();i++){for(int j=0;j<grid[0].size();j++){if(grid[i][j]=='1'){int k=index(grid,i,j);parent[k]=k;size[k]++;sets++;//集合数动态增加}}}}bool isSameFather(int i, int j){return findfather(i) == findfather(j);}int getSets(){return sets;}void together(int i, int j)//传的是下标{int A = findfather(i);int B = findfather(j);if (A != B){int big = size[A] >= size[B] ? A : B;int small = big == A ? B : A;parent[small] = big;size[big] += size[small];size[small] = 0;sets--;}}
private:vector<int>parent;//记录此位置的关键结点vector<int>size;//记录关键结点的位置vector<int>help;//做栈int sets;//记录集合个数int findfather(int i){int hi = 0;while (i != parent[i]){help[hi++] = i;i = parent[i];}for (hi--; hi >= 0; hi--)//记住先--{parent[help[hi]] = i;help[hi] = 0;}return i;}
};class Solution {
public:int numIslands(vector<vector<char>>& grid) {Union2 u(grid);for(int j=1;j<grid[0].size();j++){if(grid[0][j-1]=='1'&&grid[0][j]=='1'){u.together(index(grid,0,j-1),index(grid,0,j));}}for(int i=1;i<grid.size();i++){if(grid[i-1][0]=='1'&&grid[i][0]=='1'){u.together(index(grid,i-1,0),index(grid,i,0));}}
//前面两个for循环是对边界的处理for(int i=1;i<grid.size();i++){for(int j=1;j<grid[0].size();j++){if(grid[i][j]=='1'){if(grid[i-1][j]=='1'){u.together(index(grid,i-1,j),index(grid,i,j));}if(grid[i][j-1]=='1'){u.together(index(grid,i,j),index(grid,i,j-1));}}}}return u.getSets();}
};