文章目录
- B树最大高度推导
- 推导B树的最小高度
- 推导最大高度
- B+树:MySQL数据库索引是如何实现的?
- 1. 遇到问题
- 2. 尝试用学过的数据结构解决这个问题
- 3. 改造二叉查找树
- 4. 索引的弊端
B树最大高度推导
【声明几个重要概念】
B树的关键字就是要查找的东西
B树中的 阶:可理解为分支数. 三阶树也可理解三叉树
按照定义:
m阶B tree,每个节点最多有 m 个subnode,除根节点和叶子节点外,每个节点至少有ceil(m / 2)个子节点
根节点:
- 儿子节点个数**[2, m]**
- 关键字个数**[1, m-1]**
非根节点 :
- 儿子节点个数**[ceil(m/2), m]**
- 关键字个数**[ceil(m/2)-1, m-1]**
【注意】:儿子节点就是树本身的节点,关键字是要查询的节点
前提条件:n>=1,则对于任意一棵包含n个关键字、高度为h、阶数为m的B树
其中 : ceil()函数 代表向上取整):
推导B树的最小高度
让树变的很矮,就需要让每一层节点最多,让他充实起来
| 节点个数 | 层数 |
|---|---|
| 1 | 0 |
| m | 1 |
| m 2 m^2 m2 | 2 |
| m 3 m^3 m3 | 3 |
| … | |
| m h − 1 m^{h-1} mh−1 | h-1 (高度为h) |
对于高度为h,阶数为m的B树的总的节点个数就是每一层相加之和:
1 + m + m 2 + m 3 . . . . + m h − 1 = ( m h − 1 ) / ( m − 1 ) 1+ m +m^2+m^3 ....+m^{h-1} = (m^{h-1})/(m-1) 1+m+m2+m3....+mh−1=(mh−1)/(m−1)
$$
最大总关键字数 = 最大总节点数 \times 每个节点最大关键字数\
$$
s u m = ( m h − 1 ) / ( m − 1 ) ⋅ ( m − 1 ) = ( m h − 1 ) sum = (m^{h-1})/(m-1) \cdot (m-1) = (m^{h-1}) sum=(mh−1)/(m−1)⋅(m−1)=(mh−1)
n < = s u m n < = ( m h − 1 ) 即 : l o g m n + 1 < = h n<= sum\\ n<= (m^{h-1})\\ 即: log_m{n+1} < = h n<=sumn<=(mh−1)即:logmn+1<=h
所以对于关键字为n,高度为h,阶数为m的B数,最小高度为 l o g m n + 1 log_m{n+1} logmn+1
推导最大高度
最小高度易于理解,就是把每一层填满即可,那么反之,最大高度就是每个节点里面的关键字最少,让关键字分布的足够宽广,这样在容纳相同个数的关键字的B树中,其高度可以达到最大。
虽然这样类比,但最大高度我还是想了很久
最后一个很关键的定义点醒了我:
m阶B tree,每个节点最多有 m 个subnode,除根节点和叶子节点外,每个节点至少有ceil(m / 2)个子节点
我们量化定义
最小关键字:
- 根节点 : 1
- 非根节点:ceil(m/2)-1
最小关键字对应的最小子结点个数
- 根节点 : 1 +1 =2 (很关键)
- 非根节点:ceil(m/2)-1 +1 = ceil(m/2)(也就是定义强行背诵的)
我原来的困惑是,B树在求最大高度时,难道不能变成二叉树吗,这样就是最高了,而且好算,我没理清,m阶B树每一层最少也得ceil(m/2)个节点
以五阶B树为例画图:
根节点为2,每一层最多ceil(5/2) = 3

通过上图就很清晰的理解了下面的推导
| 节点个数 | 层数 |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 2 * ceil(m/2) | 2 |
| 2 * ceil(m/2) | 3 |
| … | |
| 2 ∗ c e i l ( m / 2 ) h − 2 2 * ceil(m/2)^ {h-2} 2∗ceil(m/2)h−2 | h-1 (高度为h) |
| 2 ∗ c e i l ( m / 2 ) h − 1 2 * ceil(m/2)^ {h-1} 2∗ceil(m/2)h−1 | 叶子节点 |
在B树中查找失败的节点个数 为n+1,而查找失败的节点就是叶子节点,叶子节点为n+1
h层对应的节点个数就是叶子节点的个数
2 ∗ c e i l ( m / 2 ) h − 1 < = n + 1 得 : h < = l o g ( c e i l ( m / 2 ) ) ( n + 1 ) / 2 + 1 2 * ceil(m/2)^ {h-1} <= n+1 \\ 得:\\ h<= log_{(ceil(m/2))}{(n+1)/2+1} 2∗ceil(m/2)h−1<=n+1得:h<=log(ceil(m/2))(n+1)/2+1
B+树:MySQL数据库索引是如何实现的?
1. 遇到问题
我们假设一个要解决的问题,其中包含这样两个常用的需求:
- 根据某个值查找数据,比如 select * from user where id=1234;
- 根据区间值来查找某些数据,比如 select * from user where id > 1234 and id < 2345。
对于非功能性需求,我们着重考虑性能方面的需求。性能方面的需求,我们主要考察时间和空间两方面,也就是执行效率和存储空间。
在执行效率方面,我们希望通过索引,查询数据的效率尽可能的高;在存储空间方面,我们希望索引不要消耗太多的内存空间。
2. 尝试用学过的数据结构解决这个问题
有哪些算法可以帮助我们解决呢?
- 散列表:时间复杂度为O(1),但是不能支持按照区间快速查询数据
- 平衡二叉查找树:时间复杂度O(logn)。而且,对树进行中序遍历,我们还可以得到一个从小到大有序的数据序列,但这仍然不足以支持按照区间快速查找数据。
- 跳表。跳表是在链表之上加上多层索引构成的,对应的时间复杂度是 O(logn)。并且,跳表也支持按照区间快速地查找数据
- 跳表是可以解决这个问题。实际上,数据库索引所用到的数据结构跟跳表非常相似,叫作 B+ 树。不过,它是通过二叉查找树演化过来的,而非跳表
3. 改造二叉查找树
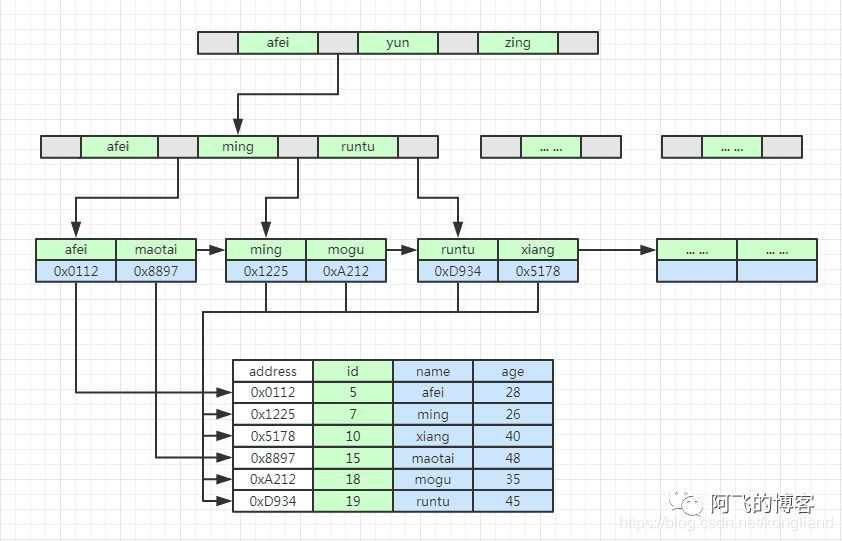
为了让二叉查找树支持按照区间来查找数据,我们可以对它进行这样的改造:树中的节点并不存储数据本身,而是只是作为索引。除此之外,我们把每个叶子节点串在一条链表上,链表中的数据是从小到大有序的。经过改造之后的二叉树,就像图中这样,看起来是不是很像跳表呢?
B+树的叶子节点上存放数据,其余节点不存放数据只作为索引

改造之后,如果我们要求某个区间的数据。我们只需要拿区间的起始值,在树中进行查找,当查找到某个叶子节点之后,我们再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止。所有遍历到的数据,就是符合区间值的所有数据。

1字节(Byte)= 8位(bit)
但是如果,我们给一亿个数据构建二叉查找树索引,那索引中会包含大约 1 亿个节点,每个节点假设占用 16 个字节,16亿字节
而1G = 2 30 2^{30} 230 = 10亿
大约是1.5G的内存空间,如果我们要给 10 张表建立索引,那对内存的需求是无法满足的。如何解决这个索引占用太多内存的问题呢?
经典思路:拿时间换空间
把索引存储在硬盘中,而非内存中。
这就带来了另一个问题:磁盘读取数据很慢,花费的时间是内存读取的上万倍,甚至几十万倍,查询效率太低了
但我们之前学习树的时候了解到树的高度就等于每次查询数据时磁盘 IO 操作的次数。
所有只要我们想办法降低树的高度就可以减少IO操作,进而提高查询速度
问题变为了:怎么降低树的高度
现在是二叉树,但如果这个叉多一点是不是就矮下来了,相同的数据,对比下面两棵树

如果我们将 m 叉树实现 B+ 树索引,用代码实现出来,就是下面这个样子(假设我们给 int 类型的数据库字段添加索引,所以代码中的 keywords 是 int 类型的):
/*** 这是 B+ 树非叶子节点的定义。** 假设 keywords=[3, 5, 8, 10]* 4 个键值将数据分为 5 个区间:(-INF,3), [3,5), [5,8), [8,10), [10,INF)* 5 个区间分别对应:children[0]...children[4]** m 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:* PAGE_SIZE = (m-1)*4[keywordss 大小]+m*8[children 大小]*/
public class BPlusTreeNode {public static int m = 5; // 5 叉树public int[] keywords = new int[m-1]; // 键值,用来划分数据区间public BPlusTreeNode[] children = new BPlusTreeNode[m];// 保存子节点指针
}/*** 这是 B+ 树中叶子节点的定义。** B+ 树中的叶子节点跟内部结点是不一样的,* 叶子节点存储的是值,而非区间。* 这个定义里,每个叶子节点存储 3 个数据行的键值及地址信息。** k 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:* PAGE_SIZE = k*4[keyw.. 大小]+k*8[dataAd.. 大小]+8[prev 大小]+8[next 大小]*/
public class BPlusTreeLeafNode {public static int k = 3;public int[] keywords = new int[k]; // 数据的键值public long[] dataAddress = new long[k]; // 数据地址public BPlusTreeLeafNode prev; // 这个结点在链表中的前驱结点public BPlusTreeLeafNode next; // 这个结点在链表中的后继结点
}
按照之前分析的思路:
对于一亿 的数据,需要一亿个叶子节点,对二叉树 大概是27层高,需要操作27次
但是如果 m 叉树中的 m 是 100,那对一亿个数据构建索引,树的高度也只是 3,(根节点在内存)最多只要 3 次磁盘 IO 就能获取到数据。
是不是m越大越好呢?
不管是内存中的数据,还是磁盘中的数据,操作系统都是按页(一页大小通常是 4KB,这个值可以通过 getconfig PAGE_SIZE 命令查看)来读取的,一次会读一页的数据。**如果要读取的数据量超过一页的大小,就会触发多次 IO 操作。**所以,我们在选择 m 大小的时候,要尽量让每个节点的大小等于一个页的大小。读取一个节点,只需要一次磁盘 IO 操作
//m 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:PAGE_SIZE = (m-1)*4[keywordss 大小]+m*8[children 大小]
4. 索引的弊端
索引有利也有弊,它也会让写入数据的效率下降。这是为什么呢?
数据的写入过程,会涉及索引的更新,这是索引导致写入变慢的主要原因。
对于一个 B+ 树来说,m 值是根据页的大小事先计算好的,也就是说,每个节点最多只能有 m 个子节点。在往数据库中写入数据的过程中,这样就有可能使索引中某些节点的子节点个数超过 m,这个节点的大小超过了一个页的大小,读取这样一个节点,就会导致多次磁盘 IO 操作。我们该如何解决这个问题呢?
实际上,处理思路并不复杂。我们只需要将这个节点分裂成两个节点。但是,节点分裂之后,其上层父节点的子节点个数就有可能超过 m 个。不过这也没关系,我们可以用同样的方法,将父节点也分裂成两个节点。这种级联反应会从下往上,一直影响到根节点。这个分裂过程,你可以结合着下面这个图一块看,会更容易理解(图中的 B+ 树是一个三叉树。我们限定叶子节点中,数据的个数超过 2 个就分裂节点;非叶子节点中,子节点的个数超过 3 个就分裂节点)。
增加会导致节点数变多超过承载,需要“分裂”
同理:删除 会导致 节点数变少,远没有到一页的承载数,需要“合并”
正是因为要时刻保证 B+ 树索引是一个 m 叉树,所以,索引的存在会导致数据库写入的速度降低。实际上,不光写入数据会变慢,删除数据也会变慢。这是为什么呢?
我们在删除某个数据的时候,也要对应的更新索引节点。这个处理思路有点类似跳表中删除数据的处理思路。频繁的数据删除,就会导致某些结点中,子节点的个数变得非常少,长此以往,如果每个节点的子节点都比较少,势必会影响索引的效率。
**我们可以设置一个阈值。在 B+ 树中,这个阈值等于 m/2。**如果某个节点的子节点个数小于 m/2,我们就将它跟相邻的兄弟节点合并。不过,合并之后结点的子节点个数有可能会超过 m。针对这种情况,我们可以借助插入数据时候的处理方法,再分裂节点。

总结一下 B+ 树的特点:
- 每个节点中子节点的个数不能超过 m,也不能小于 m/2;
- 根节点的子节点个数可以不超过 m/2,这是一个例外;
- m 叉树只存储索引,并不真正存储数据,这个有点儿类似跳表;
- 通过链表将叶子节点串联在一起,这样可以方便按区间查找;
- 一般情况,根节点会被存储在内存中,其他节点存储在磁盘中。
除了 B+ 树,你可能还听说过 B 树、B- 树,我这里简单提一下。实际上,B- 树就是 B 树,英文翻译都是 B-Tree,这里的“-”并不是相对 B+ 树中的“+”,而只是一个连接符。这个很容易误解,所以我强调下。
而 B 树实际上是低级版的 B+ 树,或者说 B+ 树是 B 树的改进版。B 树跟 B+ 树的不同点主要集中在这几个地方:
- B+ 树中的节点不存储数据,只是索引,而 B 树中的节点存储数据;
- B 树中的叶子节点并不需要链表来串联。
也就是说,B 树只是一个每个节点的子节点个数不能小于 m/2 的 m 叉树。
参考:
乐行僧丶: 推导B树的最大高度和最小高度得出B树的高度范围
极客时间: B+树:MySQL数据库索引是如何实现的?