机器学习基础
一、机器学习概述
- 机器学习直白来讲,是根据已有的数据,进行算法选择,并基于算法和数据构建模型,最终对未来进行预测;
- 输入一组数据X-Y,想要得到X-Y间的一个目标函数 f 。根据大量历史数据,根据逻辑推理得到一个与想要得到的目标函数 f 相近的假设函数 g ;
- 对于某给定的任务 T ,在合理的性能度量方案 P 的前提下,某计算机程序可以自主学习任务 T 的经验 E;随着提供合适、优质、大量的经验 E ,该程序对于任务 T 的性能逐步提高。即随着E积累,会导致以 P 度量的性能的提升;
- 选择的相关算法(数学公式)==> 基于数据和算法构建出模型 ==> 对模型进行评估 ==> 改进算法;
二、机器学习中的基本概念
- 拟合:构建的算法符合给定数据(学习数据、样本数据)的特征 ;
- x( i ):表示第 i 个样本的x向量;
- x i : x向量的第 i 维度的值;
- 鲁棒性(健壮性、稳健性、强健性):系统的健壮性。当存在异常数据(学习数据、样本数据)的时候,算法也会拟合数据;
- 过拟合:算法太符合样本数据的特征,对于实际生产中的数据特征无法拟合;
- 欠拟合:算法不太符合样本的数据特征。
- 数据分析、数据挖掘、机器学习
数据分析 :数据分析是指用适当的统计分析方法对收集的大量数据进行分析,并提取有用的信息,以及形成结论,从而对数据进行详细的研究和概括过程。在实际工作中,数据分析可帮助人们做出判断。数据分析一般而言可以分为统计分析、探索性数据分析和验证性数据分析三大类;
数据挖掘:一般指从大量的数据中通过算法搜索隐藏于其中的信息的过程。通常通过统计、检索、机器学习、模式匹配等诸多方法来实现这个过程;
机器学习:是数据分析和数据挖掘的一种比较常用、比较好的手段。
三、常见框架
- Sciket-learn;
- Mahout;
- Spark MLlib 。
四、机器学习分类
- 有监督学习
用已知某种或某些特性的样本(标签化训练数据集)作为训练集,以建立一个数学模型,再用已建立的模型来预测未知样本,此种方法被称为有监督学习,是最常用的一种机器学习方法。是从标签化训练数据集中推断出模型的机器学习任务。
(1) 判别式模型
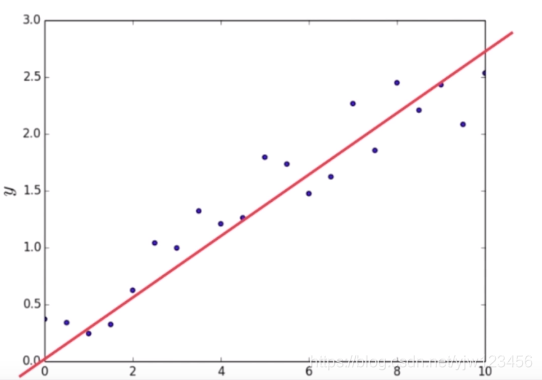
直接对条件概率 p(y|x) 进行建模,更直接,目标性更强。关注数据是如何产生的,寻找的是数据分布模型 。eg:线性回归、决策树、支持向量机SVM、k近邻、神经网络等;
(2) 生成式模型
对联合分布概率p(x,y)进行建模,更普适。关注的数据的差异性,寻找的是分类面。eg:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
联合分布概率的几何意义:如果将二维随机变量(X,Y)看成是平面上随机点的坐标,那么分布函数F(x,y)在(x,y)处的函数值就是随机点(X,Y)落在以点(x,y)为顶点而位于该点左下方的无穷矩形域内的概率。
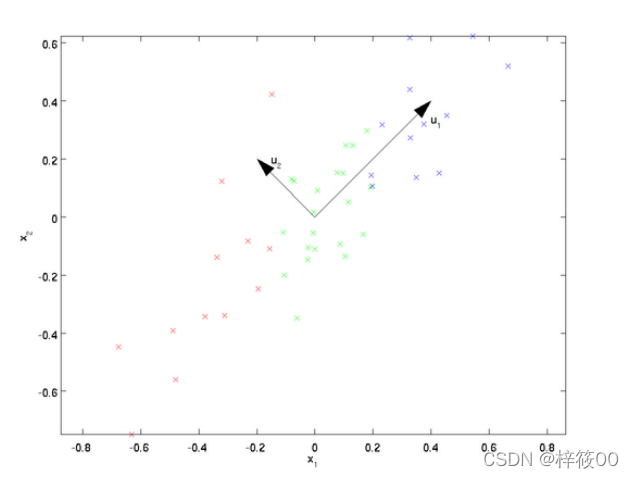
生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型。 - 无监督学习
无监督学习的训练集(普通数据、大众化数据)中没有人为的标注的结果,在非监督的学习过程中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。有监督学习为已知特征进行预测,无监督模型为不知特征找特征,故无监督学习可为监督学习提供前期处理。
(1) 目的
无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。
(2) 用途
无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出必要的标签信息。 - 半监督学习(SSL)
利用少量的标注样本和大量的未标注样本(混合样本数据)进行训练和分类的问题,是有监督学习和无监督学习的结合。又分纯半监督式学习和直推式学习。
(1) 意义
半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。
(2) 假设
平滑假设、聚类假设、流行假设;其中流行假设更具有普片性。(假设是SSL成立的基础)
对未标记数据进行假设,使之可以被利用,目的是为了得到假设所有数据(无论是否有标记)都是由同一个潜在的模型“生成”的,或说所有数据训练后将形成相同的模型。
(3) 算法
半监督分类、半监督回归、半监督聚类、半监督降维。
(4) 缺点
抗干扰能力弱,其现实意义还没有体现出来;未来的发展主要是聚焦于新模型假设的产生(过于依赖模型假设)。 - 其他分类方法
(1) 分类
通过分类模型,将样本数据集中的样本映射到某个给定的类别中
(2) 聚类
通过聚类模型,将样本数据集中的样本分为几个类别,属于同一类别的样本相似性比较大
(3) 回归
反映了样本数据集中样本的属性值的特性,通过函数表达样本映射的关系来发现属性值之间的依赖关系
(4) 关联规则
获取隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现频率。
五、机器学习算法 Top 10
| 算法名称 | 算法概述 |
|---|---|
| C4.5 | 分类决策树算法,决策树的核心算法,ID3算法的改进算法 |
| CART | 分类与回归树(Classification and Regression Trees) |
| KNN | K近邻分类算法;如果一个样本在特征空间中的k个最相似的样本中大多数属于某一个类别,那么该样本也属于该类别 |
| NaiveBayes | 贝叶斯分类模型;该模型比较适合属性相关性比较小的时候,如果属性相关性比较大的 时候,决策树模型比贝叶斯分类模型效果好(原因:贝叶斯模型假设属性之间是互不影响的) |
| SVM | 支持向量机,一种有监督学习的统计学习方法,广泛应用于统计分类和回归分析中 |
| EM | 最大期望算法,常用于机器学习和计算机视觉中的数据集聚领域 |
| Apriori | 关联规则挖掘算法 |
| K-Means | 聚类算法,功能是将n个对象根据属性特征分为k个分割(k<n),属于无监督学习(有接触) |
| PageRank | Google搜索重要算法之一 |
| AdaBoost | 迭代算法,利用多个分类器进行数据分类 |
六、机器学习开发流程
-
数据收集 ==> 数据预处理(清理与转换) ==> 特征提取 ==> 模型构建(数据建模) ==> 模型训练 ==> 模型测试 ==> 模型评估 ==>投入使用(模型部署与整合) ==> 迭代优化(利用模型反馈数据) ==> 数据收集 ==> …
-
详细流程
-
数据来源
用户访问行为数据
业务数据
外部第三方数据 -
数据存储
需要存储的数据:原始数据、预处理后数据、模型结果
存储设施:MySQL、HDFS、HBase、Solr、Elasticsearch、Kafka、Redis等 -
数据收集方式
Flume:日志收集系统。提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统),支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力
Kafka:开源流处理平台、分布式高吞吐量发布订阅消息系统。 -
数据清洗和转换 ⭐️
实际生产环境中机器学习比较耗时的一部分,大部分的机器学习模型所处理的都是特征,特征通常是输入变量所对应的可用于模型的数值表示。大部分情况下 ,收集得到的数据需要经过预处理后才能够为算法所使用,预处理的操作主要包括以下几个部分:
(1) 数据过滤
(2) 处理数据缺失
(3) 处理可能的异常、错误或者异常值
(4) 合并多个数据源数据
(5) 数据汇总
(6) 对数据进行初步的预处理,需要将其转换为一种适合机器学习模型的表示形式,对许多模型类型来说,这种表示就是包含数值数据的向量或者矩阵 :
(7) 将类别数据编码成为对应的数值表示(一般使用1-of-k方法)-dumy
功能:将非数值型的特征值转换为数值型的数据
描述:假设变量的取值有 k 个,如果对这些值用 1 到 k 编序,则可用维度为 k的向量来表示一个变量的值。在这样的向量里,该取值所对应的序号所在的元素为1,其他元素均为0。类似将之前的符号变为一个只有0-1两个选项的选题,在矩阵对应位置选择相应选项。如下例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zFegdAoC-1589527712488)(images/1568046670116.png)]](https://img-blog.csdnimg.cn/20200515155450133.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1N1YW5DYWl5dTE4MDY=,size_16,color_FFFFFF,t_70#pic_center)
(8) 从文本数据中提取有用的数据(一般使用词袋法或者TF-IDF)
词袋:将文本当作一个无序的数据集合,文本特征可以采用文本中的词条T进行体现,那么文本中出现的所有词条及其出现的次数就可以体现文档的特征
TF-IDF: 词条的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降;也就是说词条在文本中出现的次数越多,表示该词条对该文本的重要性越高,词条在所有文本中出现的次数越少,说明这个词条对该文本的重要性越高。TF(词频)指某个词条在文本中出现的次数,一般会将其进行归一化处理(该词条数量/该文档中所有词条数量,越大表示该词条在该文档中越重要);IDF(逆向文件频率)指一个词条重要性的度量,一般计算方式为总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到,越大表示该词条在该文档中越重要。TF-IDF实际上是:TF * IDF(暑假数学建模培训中有所涉及,难度不是很大)。
(9) 处理图像或者音频数据(像素、声波、音频、振幅等<傅里叶变换>)
(10) 数值数据转换为类别数据以减少变量的值,比如年龄分段
(11) 对数值数据进行转换,比如对数转换
(12) 对特征进行正则化、标准化,以保证同一模型的不同输入变量的值域相同
(13) 对现有变量进行组合或转换以生成新特征,比如平均数 (做虚拟变量)不断尝试 -
模型训练及测试
(1) 模型选择:对特定任务最优建模方法的选择或者对特定模型最佳参数的选择。
(2) 在训练数据集上运行模型并在测试数据集中测试效果,迭代进行数据模型的修改,这种方式被称为交叉验证(将数据分为训练集和测试集,使用训练集构建模型,并使用测试集评估模型提供修改建议)
(3) 模型的选择会尽可能多的选择算法进行执行,并比较执行结果(提高结果的可信度)。
(4) 模型的测试一般以下几个方面来进行比较,分别是准确率/召回率/精准率/F值:
准确率(Accuracy)=提取出的正确样本数/总样本数
召回率(Recall)=正确的正例样本数/样本中的正例样本数(覆盖率)
精准率(Precision)=正确的正例样本数/预测为正例的样本数
F值=Precision*Recall*2 / (Precision+Recall) (即F值为正确率和召回率的调和平均值)
与目的相关的就是正样本。eg:有一堆字母图片的数据集,你要识别哪个是含有A字母的图片,那么含有A字母的图片就是正样本,其他的都是负样本
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uJtqWKVz-1589527712493)(images/1568109509807.png)]](https://img-blog.csdnimg.cn/20200515155602548.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1N1YW5DYWl5dTE4MDY=,size_16,color_FFFFFF,t_70#pic_center)
混淆矩阵6.模型评估(前三点主要为分类算法)
(1) 准确率、召回率、精准率、F值
(2) ROC
描述的是分类混淆矩阵中FPR-TPR(↑具体见混淆矩阵↑)两个量之间的相对变化情况。ROC曲线的纵轴是TPR,横轴FPR。 如果二元分类器输出的是对正样本的一个分类概率值,当取不同阈值时会得到不同的混淆矩阵,对应于ROC曲线上的一个点。
ROC曲线就反映了FPR与TPR之间权衡的情况。在TPR随着FPR递增的情况下,TPR增长得越快,曲线越往上屈,AUC就越大 ,反映了模型的分类性能就越好。当正负样本不平衡时,这种模型评价方式比起一般的精确度评价方式的好处尤其显著。
(3) AUC(AUC的值越大表达模型越好)
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1(整个坐标系为横纵坐标为一的正方形)。又由于ROC曲线一般都处于 y=x 这条直线的上方,所以AUC的取值范围在 0.5 和 1 之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而AUC作为数值可以直观的评价分类器的好坏,值越大越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器;
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值;
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值;
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
(4) 回归算法结果度量指标
explained_varicance_score:可解释方差的回归评分函数
mean_absolute_error:平均绝对误差
mean_squared_error:平均平方误差
(5) 分类算法评估对应函数 & 回归算法评估对应函数
分类算法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z7QHbKs8-1589527712496)(images/1568118767305.png)]](https://img-blog.csdnimg.cn/20200515155639960.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1N1YW5DYWl5dTE4MDY=,size_16,color_FFFFFF,t_70#pic_center)
回归算法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wSMS7VBY-1589527712501)(images/1568119051049.png)]](https://img-blog.csdnimg.cn/20200515155654153.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1N1YW5DYWl5dTE4MDY=,size_16,color_FFFFFF,t_70#pic_center)
(6) 模型部署和整合
当模型构建好后,将训练好的模型存储到数据库中,方便其它使用模型的应用加载(构建好的模型一般为一个矩阵)
模型需要周期性(一个月、一周)
(7) 模型的监控与反馈
模型的效果监控是非常重要的,往往需要关注业务效果和用户体验,有时候会进行A/B测试
模型需要对用户的反馈进行响应操作,即进行模型修改,但是要注意异常反馈信息对模型的影响,故需要进行必要的数据预处理操作
七、数学基础回顾
- Taylor公式(曲线拟合、计算近似值)
- 贝叶斯公式
- 数学期望(连续性易遗忘)
- 协方差(衡量两个变量的总体误差)⭐️
- 大数定理、中心极限定律
- 最大似然估计(MLE)
写出似然函数 => 对似然函数取对数+整理 => 求导数 => 解似然方程 - QR分解
将矩阵分解为一个正交矩阵和上三角矩阵,一般用于解决线性最小二乘问题 - SVD分解(奇异值分解)⭐️
- 向量的导数、标量对向量的导数、标量对方阵的导数
- 梯度下降法 ✡️⭐️
八、Python 科学计算库
- NumPy-数学计算基础库:N维数组、线性代数计算、傅立叶变换、随机数等;
- SciPy-数值计算库:线性代数、拟合与优化、插值、数值积分、稀疏矩阵、图像处理、统计等;
- Pandas-数据分析库:数据导入、整理、处理、分析等;
- Matplotlib-绘图库:绘制二维图形和图表。
附录
- B站发现的李宏毅老师的移植视频,质量超赞!
- 最新版课程资料戳这里嗷~~
- 课件在这里