Learning Spatiotemporal Features with 3D Convolutional Networks
Abstract
摘要主要介绍在大规模有监督的视频数据集下训练出了一种简单且高效的三维卷积神经网络的方法来学习时空特征。且此发现具有三重的效果:
1)相比较于二维,三维卷积神经网络更适合于时空特征
2)在三维卷积神经网络中,333卷积内核是效果最好的
3)使用线性分类器学习到的特征,即C3D,在4个不同的基准测试中优于最先进的方法,并且与其它两个基准上的当前最先进的方法相当。
除此之外,特征很紧凑:仅仅使用10维就可在UCF101数据集上达到52.8%的精度,且由于ConvNets的快速推理能力,其也有很高的计算效率。最后,它也很简单且易于训练和使用。
1.Introduction
在这篇文章中,我们的主要贡献有三点:
1)通过实验表明,C3D是很好的特征提取器,不管是在外观或者运动信息上
2)实验表明,333的卷积内核是最好的架构
3)提出的具有简单线性模型的特征优于或接近4个不同任务和6个不同基准的最佳方法(见表1)。 它们也是紧凑和高效的计算

2.Related Work
这部分主要介绍了其他研究人员在视频处理方面取得的成果、卷积网络和3D卷积在图像以及视频方面的应用、对比之前的方法,介绍一下我们的方法的优点。C3D卷积网络将完整的视频帧作为输入,并不依赖于任何处理,可以轻松地扩展到大数据集。
3.Learning Feartures with 3D ConvNets
3.1 3D convolution and pooling
3D ConvNets 更适合学习时空特征,通过3D卷积和3D池化,可以对时间信息建模,而2D卷积只能在空间上学习特征。3D和2D的区别如下:

2D卷积网络输入图像会产生图像,输入视频输出的也是图像,3D卷积网络输入视频会输出另外一个视频,保留输入的时间信息。
我们在UCF101上进行实验,寻找最好的网络架构,在大数据库上进行验证。根据2D网络确定卷积核长宽是33的,然后变化temporal depth 寻找最好的卷积核。
Notations:
video clips size: clh*w 其中,c是通道数量,l是帧长度,h是帧高,w是帧宽
3D kernel size: dkk d是核时域深度,k是核空间尺寸
Common network settings:
输入:UCF101的视频片段 视频帧调整大小为128171 为原始视频分辨率的一半,视频分割为不重叠的16帧视频片段,作为网络输入,输入维度为316128171,训练时通过抖动,维度调整为316112*112。
通用的网络包括5个卷积层和5个池化层(一个卷积层后面跟着一个池化层),2个全连接层,1个softmax分类层来预测行为标签,卷积层的滤波器数量依次为:64、128、256、256、256。所有的卷积核的时域深度都是d,改变d来寻找最好的3D架构。池化核尺寸为222(除第一层),第一层为122,步长为1。两个全连接层有2048个输出,使用30个剪辑的迷你批次训练网络,初始的学习率为0.003,每4个epochs学习率除以10,训练16个epochs后停止。
Varying network architectures:
我们主要对如何通过深层网络来聚合时间信息。我们只改变卷积层的内核时间深度d,而保持所有其他常见设置不变如上所述。
实验了两种结构:1)均质时间深度:所有卷积层具有相同的核时间深度
2)变化的时间深度:内核的时间深度随着层的变化而变化。对于齐次设置,我们用4个网络进行实验,它们的核时间深度d分别为1、3、5和7。我们称这些网络为深度-d,其中d是它们的均匀时间深度。
注意,深度-1网络相当于在单独的帧上应用2D卷积。对于变化的时间深度设置,我们实验了两个时间深度增加的网络:3-3-5-5-7和从第一层到第五层分别减少的7-5-5-3-3。我们注意到,所有这些网络在最后的池化层具有相同大小的输出信号,因此它们对于完全连接层具有相同数量的参数。由于不同的核时间深度,它们在卷积层上的参数数是不同的。与全连接层中的数百万个参数相比,这些差异微不足道。例如,任意两个时间深度差为2的网,彼此之间只有17K个参数或少或多。参数数差异最大的是深度-1网和深度-7网,深度-7网多参数51K个,不足每个网络1750万个参数总数的0.3%。这表明网络的学习能力是可比较的,参数数量的差异不应该影响我们的架构搜索结果。
3.2 Exploring kernel temporal depth

通过实验得出depth-3是最好的,卷积核最好的尺寸是333
3.3 Spatiotemporal feature learning

3D ConvNets 有8个卷积层,内核尺寸为333;5个池化层,第一个池化核尺寸为122,后面池化核尺寸为222;2个全连接层,每层有4096个输出单元;1个softmax输出层。
Dataset:
Sports-1M 数据集,共有1.1million视频,包括487个种类
Training:
每个视频中提取5个2秒的剪辑,调整大小为128171,训练中通过对剪辑进行时间和空间上的抖动,随机剪裁到16112*112大小,并以50%的概率水平翻转。最小的batch size为30,初始学习率为0.003,每迭代150k除以2,迭代1.9M停止优化。
Sports-1M classification results:

从scratch开始训练的C3D网络产生84.4%的精度,在I380K预训练模型上进行微调的C3D网络精度为85.5%,两种网络模型精度均超过DeepVideo,但C3D仍比[29]中的方法精度低5.6%。然而,这种方法在120帧的长片段上使用深度图像特征的卷积池化,因此它不能直接与在更短的片段上操作的C3D和DeepVideo相比较。
4.Action recognition
Dataset:
UCF101:13, 320 videos of 101 human action categories.
Classification model:
我们提取C3D特征,并将其输入到一个多类别线性支持向量机中,用于训练模型。实验中采取三种不同的网络:C3D trained on I380K,C3D trained on Sports-1M, and C3D trained on I380K and fine-tuned on Sports-1M.
Baselines:
目前最好的hand-crafted features, namely improved dense trajectories (iDT)等等…
Results:

简单总结:单项测试结果中等;作者认为有部分网络采取了long clip,因此不具备可比性;联合Imagenet仅有很小的提升;联合iDT结果最佳,C3D相比其他网络有简单的优点
C3D is compact:
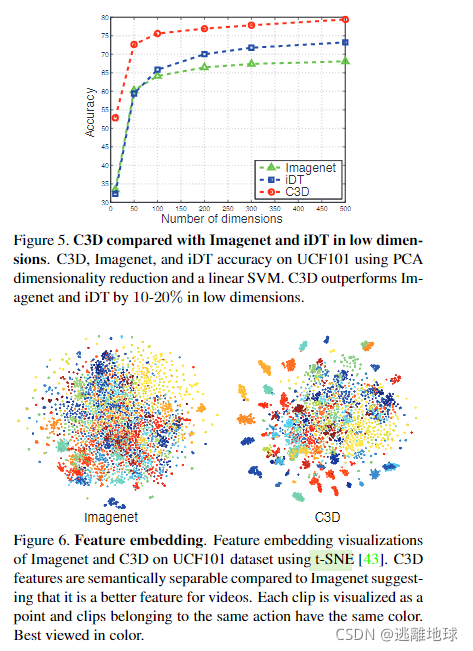
为了估计C3D特征的紧凑度,使用PCA将特征映射到低维空间,记录在UCF101数据集上映射特征的分类精度,实验得到了最佳效果,由此认为C3D特征是紧凑的并且容易区分。

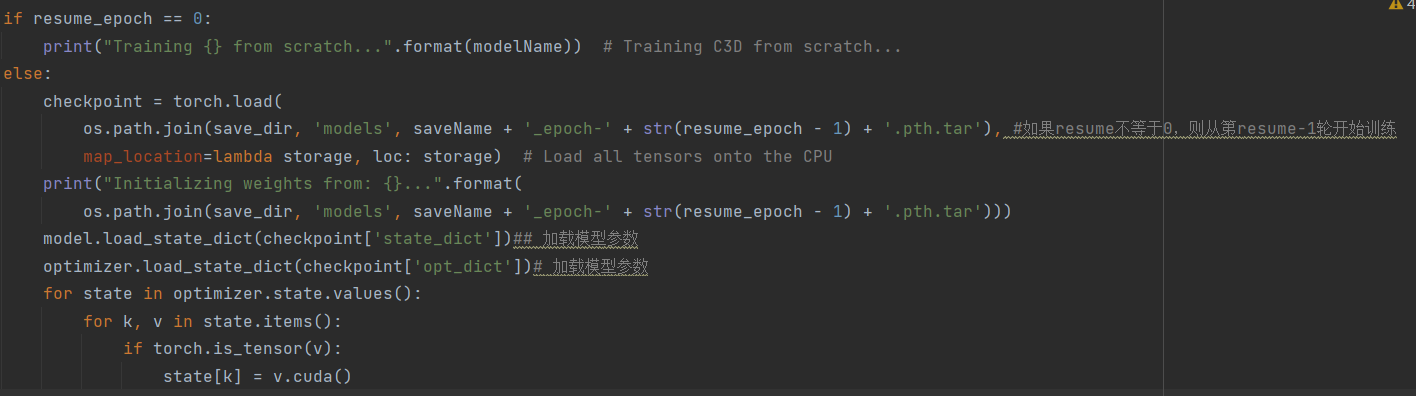
使用t-SNE将特征映射到2维空间,定性的观察得出C3D特征具备较好的泛化能力,C3D语义可分离,每个视频片段可以视为一个点,属于同一个动作的片段有相同的颜色。

5.Action Similarity Labeling
Dataset:
ASLAN:3, 631 videos,432 action classes.任务是验证给定的视频对是否相同
Features:
将一个视频划分为16帧剪辑且其中8帧是重叠的,提取每个片段C3D特征(pro3,fc7,fc6,pool5),平均每种类型特征得到视频特征,L2标准化
Classification model:
给定一个视频对,我们计算[21]中的12个不同距离。加上4个特征类别,获取48维特征向量
由于48个方向并非一一比较,我们分别将其标准化,得到零均值和单位方差
最终,训练一个线性SVM在48维特征向量上分出视频对相同与否

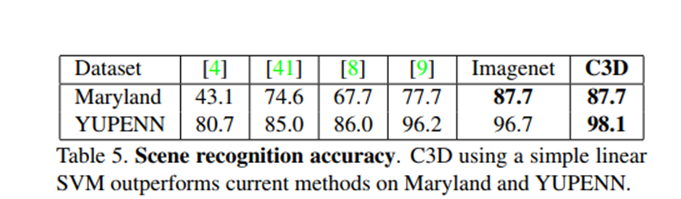
6.Scene and Object Recognition
Datasets:
YUPENN:420 videos of 14 scene categories
Maryland:130 videos of 13 scene categories
Classification model:
对于这两个数据集,我们使用相同的特性提取和线性支持向量机进行分类。
我们在所有视频中滑动16帧的窗口来提取C3D特征,选择clip中出现频率最高的label作为clip的ground truth label
如果最高频率的label出现次数少于8帧,则认为是negative label,在训练和测试期间均丢弃
用线性SVM来训练和测试C3D特征并记录物体识别率
Results:
取得了最佳表现,说明C3D泛化能力强
7.Runtime Analysis

8.Conclusion
在这个工作我们试图解决这一问题的学习视频时空特性使用c3d网训练的大规模视频数据集。我们进行了系统的研究,以找到最好的时间内核长度为c3d网。我们发现C3D可以同时模型外观和运动信息和优于2 d事先特性在各种视频分析的任务。我们证明了C3D特性与一个线性分类器可以超过或接近当前的最佳方法在不同的视频分析的基准。最后但并非最不重要,提出C3D特性是有效的,紧凑,简单易用。
实验部分
4.行为识别
数据集:我们在UCF101数据集[38]上评估C3D特征。数据集由13320个视频组成,包含101个人类动作类别。我们使用该数据集提供的三个分割设置。
分类模型:提取C3D特征并将其输入多类线性支持向量机进行训练。我们使用3种不同的网络对C3D描述符进行了实验:C3D训练在I380K上,C3D训练在Sports-1M上,C3D训练在I380K上和微调的Sports-1M上。在多个网络的设置中,我们将这些网的l2标准化的C3D描述符连接起来。
基线:我们将C3D特征与一些基线进行比较:当前最好的手工制作特征,即改进的稠密轨迹(iDT)[44]和流行使用的深度图像特征,即Imagenet[16],使用Caffe s Imagenet预训练模型。对于iDT,我们使用每个iDT特征通道的码本大小为5000的袋形表示,这些特征通道是轨迹、HOG、HOF、MBHx和MBHy。我们分别使用L1-norm对每个通道的直方图进行归一化,并将这些归一化的直方图串联起来,形成一个视频的25K的特征向量。对于Imagenet基线,类似于C3D,我们提取每帧Imagenet fc6特征,平均这些帧特征来制作视频描述符。多类线性支持向量机也用于这两个基线的公平比较。
结果:表3给出了C3D的动作识别精度,并与两种基线和当前的最佳方法进行了比较。上半部分显示了两个基线的结果。中间部分展示了只使用RGB帧作为输入的方法。下面的部分使用所有可能的特征组合(如光流,iDT)报告所有当前的最佳方法。

C3D微调网在前面描述的三种C3D网中表现最好。然而,这三种蚊帐之间的性能差距很小(1%)。从现在起,除非另有说明,我们将微调后的网络称为C3D。使用一个只有4,096个维度的网络C3D的准确率为82.3%。3网C3D将精度提高到85.2%,尺寸增加到12288。C3D与iDT联合时,准确率进一步提高到90.4%,与Imagenet联合时,仅提高了0.6%。
这说明C3D可以很好地捕捉到外观和运动信息,因此与基于外观特征的深度特征Imagenet结合是没有好处的。另一方面,C3D与iDT的结合是有益的,因为它们之间具有很强的互补性。事实上,iDT是基于光流跟踪和低水平梯度直方图的手工制作的特征,而C3D捕捉高层次的抽象/语义信息
与iDT和Imagenet基线相比,使用3网的C3D准确率达到了85.2%,分别提高了9%和16.4%。在唯一的RGB输入设置上,与基于cnn的方法相比,我们的C3D在[36]中的深度网络和[18]空间流网络的性能分别高出19.8%和12.6%。在[36]中,深度网络[18]和空间流网络都使用了AlexNet架构。而在[18]中,网络的微调来自于他们在Sports-1M上的预训练模型,而在[36]中,空间流网络的微调来自于Imagenet的预训练模型。


5.动作相似标记
数据集:ASLAN数据集由来自432个动作类的3631个视频组成。
任务是预测给定的一对视频是否属于相同或不同的动作。
我们使用指定的10倍交叉验证和数据集提供的分割。这个问题与动作识别不同,因为任务的重点是预测动作相似性,而不是实际的动作标签。这个任务非常具有挑战性,因为测试集包含了以前从未见过的动作的视频
特征:我们把视频分成16帧,8帧重叠的片段。我们提取C3D特征:prob, fc7, fc6, pool5为每个剪辑。视频的特征是通过对每种类型的特征分别求片段特征的平均值,然后进行L2归一化来计算的
分类模型:我们遵循[21]中使用的相同设置。给定一对视频,我们计算[21]提供的12个不同的距离。通过4类特征,我们得到每个视频对的48维(12×4 = 48)特征向量。由于这48个距离彼此不具有可比性,我们对它们进行独立的归一化处理,使得每个维度的均值和单位方差均为零。最后,训练线性支持向量机对这些48-dim特征向量的视频对进行相同或不同的分类。除了与当前的方法进行比较外,我们还使用基于深度图像的功能将C3D与强基线进行了比较。基线具有与我们的C3D相同的设置,我们使用Imagenet功能替换C3D特征。
结果:我们报告了C3D的结果,并与表4中最先进的方法进行了比较。虽然目前大多数方法使用多种手工制作的特征,强大的编码方法(VLAD, Fisher向量),和复杂的学习模型,我们的方法使用简单的平均C3D特征的视频和线性支持向量机。C3D在准确性上比最先进的[45]方法高出9.6%,在ROC曲线下面积(area under ROC curve, AUC)上高出11.1%。Imagenet基线表现相当好,仅比最先进的方法[45]低1.2%,但由于缺乏运动建模,比C3D差10.8%。图7为C3D与现有方法和人类表现对比的ROC曲线。
C3D已经取得了显著的进步,从目前最先进的方法到人类性能的一半(98.9%)