文章转自微信公众号:【机器学习炼丹术】。有问题或者需要加入粉丝交流群可以私信作者~
文章目录
- 0 前言
- 1 R2D
- 2 C3D
- 2.1 R3D
- 3 P3D
- 4 MCx
- 5 R(2+1)D
【前前沿】:某一次和粉丝交流的时候,收获一句话:
人点亮技能书,不是一次性电量的。是反复折腾,反复批判,反复否定与肯定,加深了记忆轴。 —某位粉丝
0 前言
看到这篇论文是因为之前看到一篇Nature上的某一篇医疗影像的论文中用到了这几个算法,R3D,MC3和R2+1D的3D卷积的算法。因为对3D卷积的算法了解比较局限,所以开始补一补这方面的算法。
1 R2D
这个就完全是把一个视频当成一个图片来处理,一个视频假设有10帧,那么就把这个视频当成一个10通道的图片进行处理,如果是10帧的彩色图片,那么这个就是30通道的图片。
正常情况下,一个视频是有四个维度的:
c h a n n e l × t i m e × h × w channel \times time \times h \times w channel×time×h×w
假设有一个10帧的1080x960的彩色视频,那么是个视频转换成张量应该是:
3 × 10 × 960 × 1080 3\times 10 \times 960\times 1080 3×10×960×1080
但是对于R2D算法来说,这个视频的张量为:
30 × 960 × 1080 30 \times 960 \times 1080 30×960×1080
这样的话,就完全的放弃了时间的信息。当然,与这个R2D类似的算法,还有一个叫做f-R2D的算法,这个f-R2D是对每一帧进行2D的操作,然后在最后全局池化层去融合全部的信息,某种角度上也是牺牲了时间连续的信息。
- f-R2D是frame-based R2D的缩写。
2 C3D
这个就是使用了3D卷积的方法,对于3D卷积构建的网络,需要注意的就是池化层的时候需要注意stride的参数是3个,不仅有w和h的步长,还要考虑时间维度上的步长。
在C3D的论文中给出了这样的一个网络结构:

8个卷积层和2个全连接层,其中包含5个池化层(filter:2×2×2,stride: 2×2×2,除了第一个池化层的filter:1×2×2,stride: 1×2×2)
2.1 R3D
R2D和C3D我们都有所了解,那么什么是R3D呢?这个其实就是使用了Resnet网络的C3D罢了,由此可见,这个R3D的R的含义是Resnet网络的意思。
3 P3D
这个类似2D网络中的googleNet提出的inception中的概念,将7x7的卷积核拆分成1x7和7x1的两个。
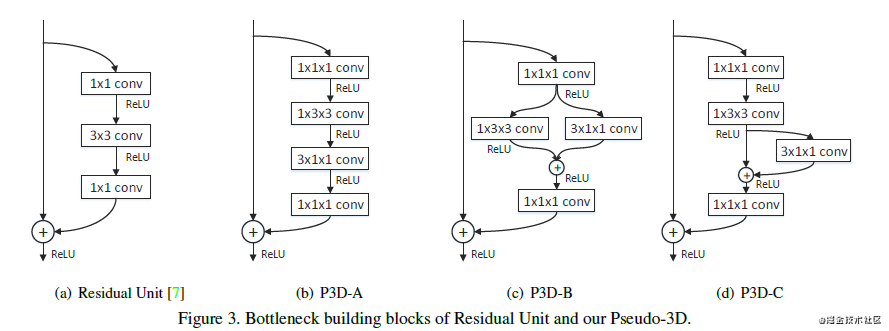
P3D是Pseudo-3D伪3D卷积的含义,把3x3x3的卷积核拆分成1x3x3的空间卷积和3x1x1的时间卷积。这样做的好处有:
- 减少计算量,这个是肯定的
- 可以使用2D图像经典的卷积模型的训练参数作为3D模型的空间卷积层参数的初始化
P3D网络提出了3个不用的block,讲道理我觉得这三个差别不大:
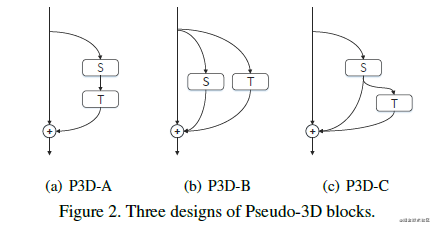
再多说两句好了,P3D卷积把3D卷积解耦成2D的空间卷积和1D的时间卷积,这样可以防止在resnet的残差模块中,实现迁移学习:
关于这P3D的ABC三个样式的效果论文中也给出了结果:
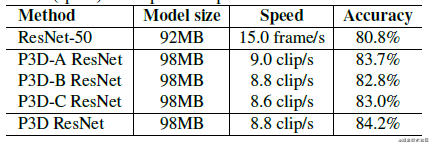
效果最好的是P3D Resnet,这个是对三个模块的混合,混合顺序是:
P3D-A->P3D-B->P3D-C
但是我还是觉得这个有些冗余,没有什么道理。
4 MCx
这个方法是结合了R2D和R3D(C3D)两种方法,MC是Mixed Convolution混合卷积的含义。我们先看一下网络结构对比图:
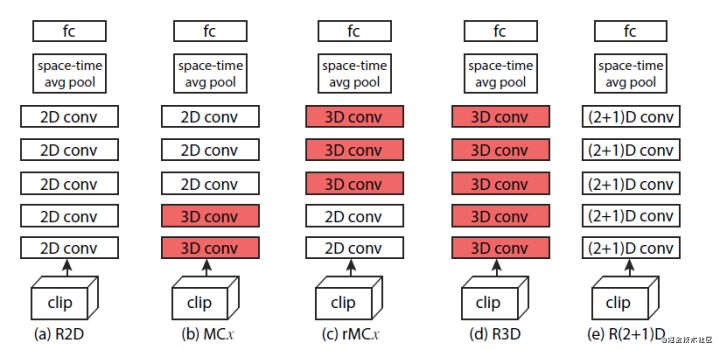
- 这个的MCx的结构是前面3层是2D卷积,之后跟上两个3D卷积,因为是有3层的2D卷积,之后才换成3D卷积的,所以这个叫做MC3;
- 后面的rMCx是和MCx相反的,是先3D卷积,然后再2D卷积,这里是rMC3;
先2D还是3D取决于:你认识时间的信息处理是依赖于浅层网络还是深层的网络。论文中给出的实验结果表明,时间信息应该更加依赖于深层的网络,MCx的效果更好一些。
5 R(2+1)D
这个和MCx同属于混合卷积,用2D卷积和1D卷积来逼近3D卷积。
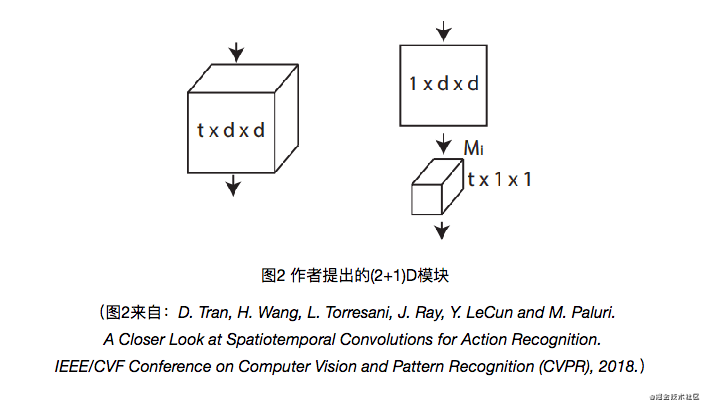
其实从图中来看,这个和P3D-A没什么区别,其实我也觉得没什么区别。硬要说的话:
- 就是P3D的第一层是2D卷积,之后才是P3D模块,而R(2+1)D的网络是从一开始都是这种模块的;
- R(2+1)D模块计算了超参数,通过增加通道数,来让分解之后的R(2+1)D模型和之前的3D模型的参数量相同。这里是控制哪里的通道数呢?是2D卷积之后,要输入到1D时间卷积的那个特征图的通道数,从上图中可以看到 M i M_i Mi这个参数。这个参数可以通过这样计算:
M i = f l o o r ( t d 2 N i − 1 N i d 2 N i − 1 + t N i ) M_i=floor(\frac{td^2N_{i-1}N_i}{d^2N_{i-1}+tN_i}) Mi=floor(d2Ni−1+tNitd2Ni−1Ni)
总之这个的好处,在论文中是跟C3D进行比较的(并没有和P3D进行比较):
- 第一就是两个子卷积之间多出来一个非线性操作,和原来同样参数量的3维卷积相比double了非线性操作,增强了网络的表达能力。
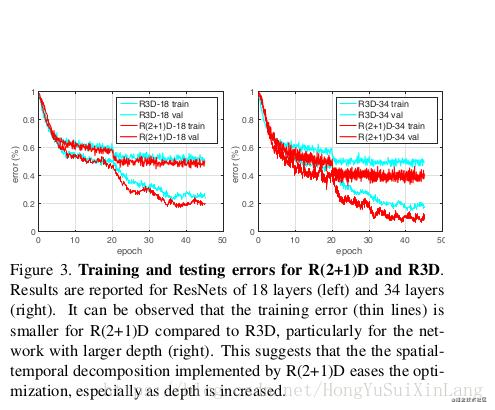
- 第二个好处就是时空分解让优化的过程也分解开来,事实上之前发现,3维时空卷积把空间信息和动态信息拧巴在一起,不容易优化。2+1维卷积更容易优化,loss更低。
上个图:
总结:总体来说3D卷积的论文是以实验为主,用实验结果来数结论。尽可能的利用2D预训练模型的参数。
参考论文:
- C3D:Learning Spatiotemporal Features with 3D Convolutional Networks
- P3D:Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
- R(2+1)D:A Closer Look at Spatiotemporal Convolutions for Action Recognition