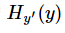C3D网络
论文链接
论文翻译
该论文发现:
1、3D ConvNets比2D ConvNets更适用于时空特征的学习;
2、对于3D ConvNet而言,在所有层使用3×3×3的小卷积核效果最好;
3、我们通过简单的线性分类器学到的特征名为C3D(Convolutional 3D),在4个不同的基准上优于现有的方法,并在其他2个基准上与目前最好的方法相当。
论文的主要贡献
-
我们的实验表明3D卷积深度网络是好的学习器,可以对外观和运动同时建模。
-
我们的经验发现,在有限的探究框架中,所有层使用3×3×3卷积核效果最好。
-
在4个任务和4个基准上,提出的特征通过简单的线性模型可以超过或接近目前最好的方法(见下表)。这些特征紧凑、计算高效。
该方法我们将整个视频作为输入。
3D卷积联和3D池化
与2D ConvNet相比,3DConvNet能够通过3D卷积和3D池化操作更好地建模时间信息。在3D ConvNets中,卷积和池化操作在时空上执行,而在2DConvNets中,它们仅在空间上完成。所以在第一次使用2D卷积和池化后,就失去其时间信息。下图为2D卷积和3D卷积的对比:
由经验和大量的实验发现3*3的卷积产生较好的效果,所以论文中都使用用3*3大小的卷积核,而后面对卷积核大小的研究主要集中在不同的深度上。
为了简单起见,从现在开始,我们将视频片段尺寸定义为c×l×h×w,其中c是通道数,l是帧数的长度,h和w分别是帧的高度和宽度。我们还将3D卷积和池化核大小指向d×k×k,其中d是核的时间深度,k是核的空间大小。
网络设置:将视频分割成非重叠的16帧作为网络的输入,将视频帧的大小调整为128×171,所以输入尺寸为:3×16×128×171。在训练期间用输入大小为3×16×112×112的随机裁剪来模拟抖动。网络具有5个卷积层和5个池化层(每个卷积层紧随其后的是池化层),2个完全连接的层和softmax损耗层以预测动作标签(ucf101数据集的101个类别)。对于5个卷积层,从1到5卷积层的滤波器数量分别为64,128,256,256,256。
所有卷积层都使用padding和步长为1,所以从卷积层的输入到输出特征图的大小没有改变。所有的池化层(除第一层)都是用2×2×2、步长为1的最大池化。。第一个池化核大小为1×2×2,其意图是不能太早地合并时间信号,并且也能够满足16帧的片段长度,两个全连接层有2048个输出。我们从头开始使用30个片段的小批量训练网络,初始学习率为0.003。学习率在每4个周期之后除以10。训练在16个周期之后停止。
为寻找一个好的3D卷积核,我们保持上面的通用策略,只改变卷积核的深度,我们尝试了两种策略:1)均匀时间深度:所有卷积核具有相同的时间深度;2)变化的时间深度:不同层的卷积核时间深度不同。对于均匀设置,我们试验了具有d=1,3,5,7的时间深度的4个网络。我们将这些网络命名为depth-d,其中d是其均匀时间深度。请注意,depth-1网络相当于在单独的帧上应用2D卷积。对于变化的时间深度设置,我们分别从第一到第五卷积层试验了两个网络,时间深度增加的:3-3-5-5-7和时间深度增加减少的:7-5-5-3-3。
下图为两种策略的实验结构:
可以看出在均匀的策略中Depth-3表现最好。将Depth-3与变换的策略对比发现还是Depth-3效果更好。我们把它应用于视频分类中效果也要好于二维卷积,我们还验证了3D ConvNet在大规模内部数据集(即I380K)上的性能优于2D ConvNet。
时空特征学习
上一节的发现表明,3×3×3卷积核的均匀设置是3DConvNets的最佳选择,所以我们设计了C3D网络,他具有8个卷积层、5个池化层、两个全连接层,以及一个softmax输出层。所有3D卷积滤波器均为3×3×3,步长为1×1×1。为了保持早期的时间信息设置pool1核大小为1×2×2、步长1×2×2,其余所有3D池化层均为2×2×2,步长为2×2×2。每个全连接层有4096个输出单元。其结构图为:
数据集:在Sports-1M数据集上训练C3D,学习时空特征。
训练:在Sports-1M训练集上进行训练。由于Sports-1M有许多长视频,我们从每个训练视频中随机提取出2秒长的五个片段。片段调整帧大小为128×171。在训练中,我们随机将输入片段裁剪成16×112×112片段,对于空间和时间抖动。 我们也以50%的概率水平翻转它们。训练由SGD完成,batch size为30。初始学习率为0.003,每150K次迭代除以2。优化在1.9M迭代(约13epochs)停止。除了从头开始训练C3D外,我们还从在I380K上预先训练的模型中对C3D网进行了微调。
分类结果:下图是C3D与DeepVideo和Convolutiopooling的比较结果。我们每个片段只使用一个中心裁剪,然后放入网络进行片段预测。整个视频的预测,由对视频中随机提取的10个片段的预测进行平均得到。DeepVideo和C3D使用短片段,而Convolution pooling使用更长的片段。
C3D描述符:将输入视频分成若干16帧的片段,相邻片段之间由8帧重叠,将这些片段输入到训练好的网络中,将得到的若干组fc6层的输出平均形成4096维视频描述符。
动作识别
分类模型:我们使用3个不同网络的C3D描述符进行试验:在I380K上训练的C3D,在Sports-1M上训练的C3D,以及在I380K上训练并在Sports-1M上进行微调的C3D。,然后将3个网络得到的描述符分别放入SVM中。
基准:我们将我们网络的描述符和IDT和imagenet网络得到的描述符分别放入SVM中比较各自效果。下图显示了与两个基准相比较的C3D的动作识别准确度和当前最佳方法。上面部分显示了两个基准的结果。中间部分显示了仅使用RGB帧作为输入的方法。而下面部分报告了使用所有可能的特征组合(例如光流,iDT)的所有当前最佳方法。
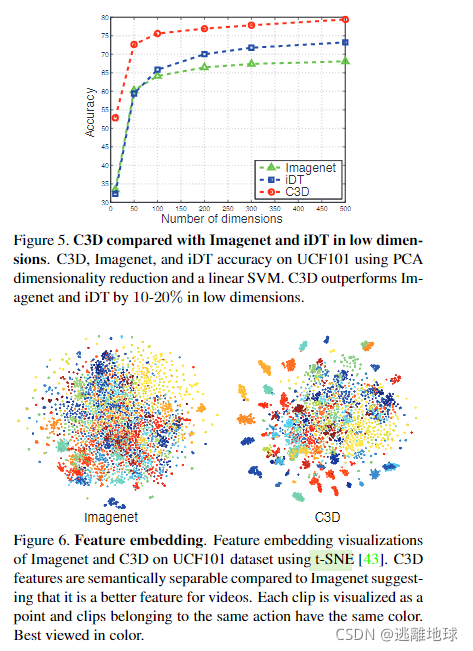
C3D提取的特征是紧凑的 :我们将imageenet、idt、c3d网络提取的特征用pca进行降维,然后将这些特征放入svm进行识别,分别得到各个维度的识别精度,如下图所示,可以看出,C3D是紧凑的。
、
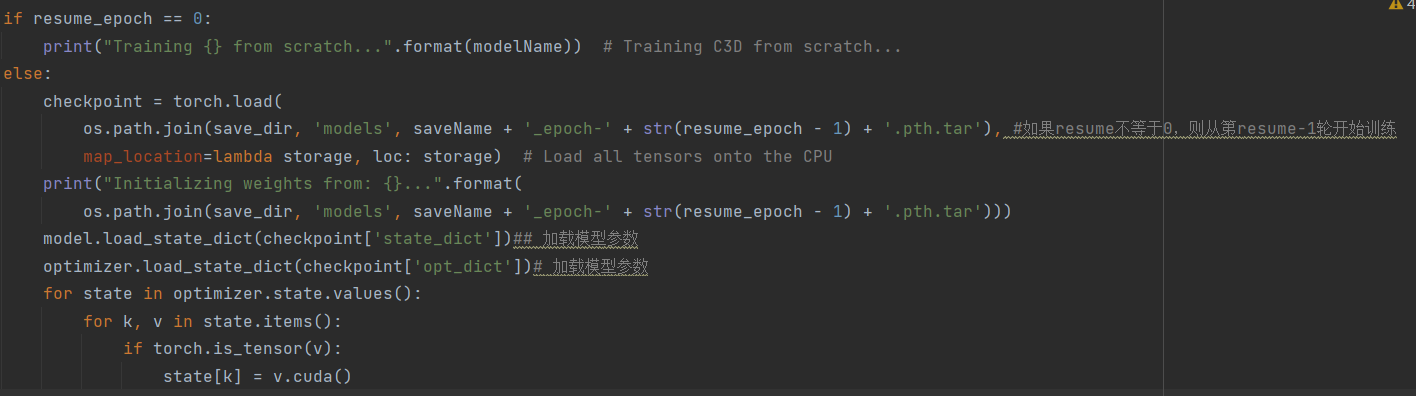
下图为从UCF101随机选择100K个片段,然后分别通过imagenet和C3D的特征来提取这些片段的fc6特征,然后通过t-SNE将特征投影到二维空间的图片,而且我们并没对这两个网络进行微调,以此来看他们的跨数据集的泛化能力。
运动时间分析
我们比较C3D和iDT和时间流网络的运行时间,如下图所示。
结论
论文进行了系统的研究,以找到3DConvNets的最佳时间核长度。展示了C3D可以同时对外观和运动信息进行建模,在各种视频分析任务上优于2DConvNet特征。展示了具有线性分类器的C3D特征可以在不同的视频分析基准上胜过或接近现行的最佳方法。最后,提出的C3D特征是高效的、紧凑的、使用非常简单的。