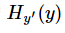前几天一直在看Faster-Rcnn源码和YOLOv3(C语言)源码,感觉时间浪费了不少,但是一个都没有看懂,总结出一句话就是:这TM写的是个啥?我为啥一个都看不懂,原理理解是一回事,看懂代码是一回事,至于自己上手敲更是另外一回事了,后来想想,我没看懂也是有道理的,因为我没有花那么多的时间去看,只看了两三天,有些代码真的不懂,也没有去深究,所有以至于整个都没有看懂,问了一个看完Faster-Rcnn的学长是怎么看完的,他说他花了将近一个月的时候。也难怪,只要花时间查,应该是能看懂的,但是我现在好像没有这么多时间去从一个比较难的网络开始,我还是从一个比较简单而又实用的网络开始我的课题吧-C3D网络。
Let's Open this paper
****************************************************************************************************************
花了一晚上加一上午看了C3D网络的paper,说实话这个网络现在对于行为识别已经有点过时了,只是里面的3D卷积成为了经典,没有花里胡哨的连接,只有传统网络的一条路,卷积,池化,分类。我用这个网络的主要目的是用来3D医学图像分类的。
论文地址:http://vlg.cs.dartmouth.edu/c3d/c3d_video.pdf
常用数据库
行为识别的数据库比较多,这里主要介绍两个最常用的数据库,也是近年这个方向的论文必做的数据库。
- UCF101:来源为YouTube视频,共计101类动作,13320段视频。共有5个大类的动作:1)人-物交互;2)肢体运动;3)人-人交互;4)弹奏乐器;5)运动。数据库主页
- HMDB51:来源为YouTube视频,共计51类动作,约7000段视频。数据库主页
在Actioin Recognition中,实际上还有一类骨架数据库,比如MSR Action 3D,HDM05,SBU Kinect Interaction Dataset等。这些数据库已经提取了每帧视频中人的骨架信息,基于骨架信息判断运动类型。不做详细介绍
1.基本介绍
本文网络设计主要是用来Action Recognition,之前有用2D-CNN网络来识别的,但是2D的不能很好的提取时间特性,所以效果也不是很好,现在我们看一下3D-CNN和2D-CNN的区别:

首先简要介绍一下2D与3D卷积之间的区别。a)和b)分别为2D卷积用于单通道图像和多通道图像的情况(此处多通道图像可以指同一张图片的3个颜色通道,也指多张堆叠在一起的图片,即一小段视频),对于一个滤波器,输出为一张二维的特征图,多通道的信息被完全压缩了。而c)中的3D卷积的输出仍然为3D的特征图。
如果输入一段视频,其大小是


2.网络结构
网络结构也特别的简单:

8个卷几层,5个池化层,2个全连接层,然后是一个softmax(我习惯叫它"软max",怎么样,是不是很形象),这里值得注意的是作者通过大量实验证明,作者多次用到了“empirically”这个词,证明卷积大小统一是3*3*3的时候性能是最牛*的,然后给出了几个说服观众的图(好吧,我信!):

还有一个要注意的点就是池化层,作者说,池化层除了第一个是1*2*2,其余的都是2*2*2,为什么呢?我解释一下,池化层的第一个数是时间深度,如果设置成1的话,也就是在单独的每帧上面进行池化,如果大于1的话,那么就是在时间轴上,也就是多帧之间进行池化,前者是有利于在初始阶段保留时间特征,作者也用了一句话解释:


然后,后面的全连接层用了4096个输出单元。
其他信息:卷积核步长是1,输入尺寸是:
- 数据准备:
- 提取片段:对于每一个训练视频,我们随机提取5个时长为2s的视频片段。
- resized: 调整大小为128×171128×171
- 训练阶段:
- 裁切(crop):将输入视频片段随机剪切为16×112×11216×112×112
- 水平翻转:50%的概率
- SGD with mini-batch size = 30;
- 初始学习速率为0.003,每150K次迭代除以2.
- 最优化过程在1.9M次 (13个周期)
- 除了用C3D网络从头开始训练,我们同样使用在I380K上预训练的模型进行微调。
3.结果
通过一系列操作之后,作者得到结论:


在UCF101上行为识别达到85.2%,据说能达到目前已经达到96.4%
动作相似度标注-Action Similarity Labeling

动作相似度标注问题的任务是判断给出的两段视频是否属于相同的动作。文章中使用的数据库为ASLAN。C3D的效果超过了当时的state of the art 不少。
场景识别-Scene Recognition

场景识别问题主要使用了Maryland和YUPENN,也都达到了不错的效果。
运行时间分析
下表中是C3D与其他一些算法的速度比较。其中iDT是行为识别领域的非深度学习方法中效果最好的方法,Brox指Brox提出的光流计算方法[3].

其中光流计算(GPU版本)现在的速度可以达到20-25fps,表中C3D的速度应该是在视频帧无重叠的情况下获得的。将一段16帧的视频作为一个输入,则C3D一秒可以处理约42个输入(显卡为1080, batch size选为50),换算成无重叠情况下的fps为672。可见C3D的速度还是非常快的。
4.结论
主要的研究有3点:
- 3D卷积网络相对于3D卷积神经网络更加适合学习时域空域(spatiotemporal)特征学习。
- 所有层采用3×3×33×3×3卷积核大小的网络结构能够获得最好的表现。
3D网络学习到的特征输入到简单的线性分类器(多分类线性SVM)相对于其它方法能够获得比较好的表现。
其中我认为最好的还是他的快,以及简洁的网络,很适合做成特征提取网络,对于我的3维图像的分类有很大帮助。
谢谢大家!
参考文献:
1.微信公众号