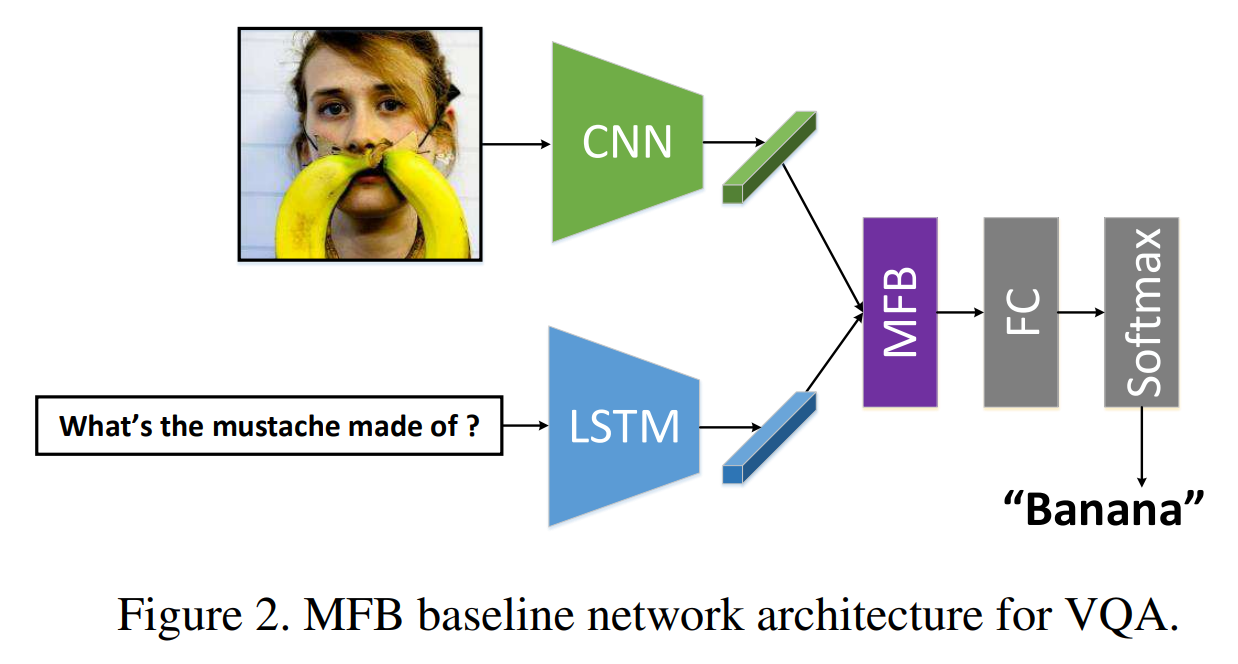
目录
- 0 前言
- 1 最小二乘法概述
- 2 最小二乘法求解多项式曲线系数向量的数学推导
- 2.1 代数法
- 2.2 矩阵法
- 3 代码实现
- 4 总结
- 参考
0 前言
自动驾驶开发中经常涉及到多项式曲线拟合,本文详细描述了使用最小二乘法进行多项式曲线拟合的数学原理,通过样本集构造范德蒙德矩阵,将一元 N 次多项式非线性回归问题转化为 N 元一次线性回归问题,并基于线性代数 C++ 模板库——Eigen 进行了实现,最后,比较了几种实现方法在求解速度与求解精度上的差异。
1 最小二乘法概述
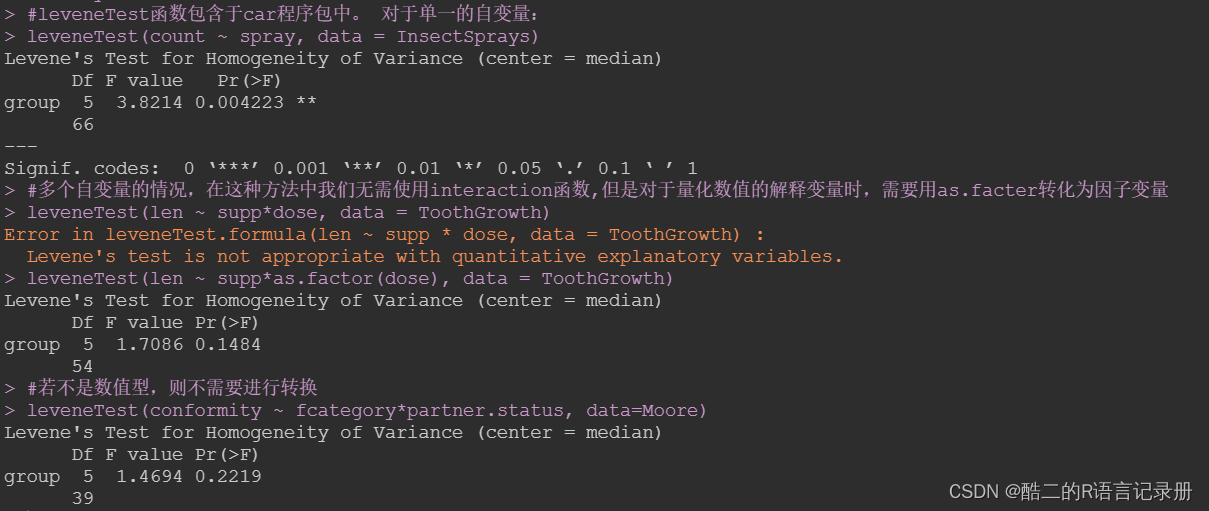
最小二乘法(Least Square Method,LSM)通过最小化误差(也叫残差)的平方和寻找数据的最优函数匹配。
假设给定一组样本数据集 P ( x , y ) P(x, y) P(x,y), P P P 内各数据点 P i ( x i , y i ) ( i = 1 , 2 , 3 , . . . , m ) P_i(x_i, y_i) (i=1, 2, 3, ..., m) Pi(xi,yi)(i=1,2,3,...,m) 来自于对多项式
f ( x i ) = θ 0 + θ 1 x i + θ 2 x i 2 + ⋅ ⋅ ⋅ + θ n x i n f(x_i)=θ_0+θ_1x_i+θ_2x_i^2+···+θ_nx_i^n f(xi)=θ0+θ1xi+θ2xi2+⋅⋅⋅+θnxin
的多次采样,其中:
- m m m 为样本维度
- n n n 为多项式阶数
- θ j ( j = 1 , 2 , 3 , . . . , n ) θ_j (j=1, 2, 3, ..., n) θj(j=1,2,3,...,n) 为多项式的各项系数
针对样本数据集 P P P 内各数据点的误差平方和为:
S = ∑ i = 1 m [ f ( x i ) − y i ] 2 S=\sum_{i=1}^m[f(x_i)-y_i]^2 S=i=1∑m[f(xi)−yi]2
最小二乘法认为,最优函数的各项系数 θ j ( j = 1 , 2 , 3 , . . . , n ) θ_j (j=1, 2, 3, ..., n) θj(j=1,2,3,...,n) 应使得误差平方和 S S S 取得极小值。最小二乘法与极大似然估计有着密切的联系,关于最小二乘法的数学本质可参考文章《如何理解最小二乘法?》。
2 最小二乘法求解多项式曲线系数向量的数学推导
2.1 代数法
由于最优函数的各项系数 θ j ( j = 1 , 2 , 3 , . . . , n ) θ_j (j=1, 2, 3, ..., n) θj(j=1,2,3,...,n) 使得误差平方和 S S S 取得极小值,因而,对于最优函数而言,其误差平方和 S S S 对各多项式系i数 θ j ( j = 1 , 2 , 3 , . . . , n ) θ_j (j=1, 2, 3, ..., n) θj(j=1,2,3,...,n) 的偏导数应满足:
∂ S ∂ θ j = ∑ i = 1 m [ 2 ( θ 0 + θ 1 x i + θ 2 x i 2 + ⋅ ⋅ ⋅ + θ n x i n − y i ) x i j ] = 0 \frac{\partial{S}}{\partial{θ_j}}=\sum_{i=1}^{m}[2(θ_0+θ_1x_i+θ_2x_i^2+···+θ_nx_i^n-y_i)x_i^j]=0 ∂θj∂S=i=1∑m[2(θ0+θ1xi+θ2xi2+⋅⋅⋅+θnxin−yi)xij]=0
整理上式, j j j 分别取 0 , 1 , 2 , . . . , n 0,1,2,...,n 0,1,2,...,n 时,有:
{ m θ 0 + ( ∑ i = 1 m x i ) θ 1 + ( ∑ i = 1 m x i 2 ) θ 2 + ⋯ + ( ∑ i = 1 m x i n ) θ n = ∑ i = 1 m y i ( ∑ i = 1 m x i ) θ 0 + ( ∑ i = 1 m x i 2 ) θ 1 + ( ∑ i = 1 m x i 3 ) θ 2 + ⋯ + ( ∑ i = 1 m x i n + 1 ) θ n = ∑ i = 1 m ( x i y i ) ( ∑ i = 1 m x i 2 ) θ 0 + ( ∑ i = 1 m x i 3 ) θ 1 + ( ∑ i = 1 m x i 4 ) θ 2 + ⋯ + ( ∑ i = 1 m x i n + 2 ) θ n = ∑ i = 1 m ( x i 2 y i ) ⋯ ⋯ ( ∑ i = 1 m x i n ) θ 0 + ( ∑ i = 1 m x i n + 1 ) θ 1 + ( ∑ i = 1 m x i n + 2 ) θ 2 + ⋯ + ( ∑ i = 1 m x i 2 n ) θ n = ∑ i = 1 m ( x i n y i ) \begin{cases} mθ_0+(\sum\limits_{i=1}^{m}x_i)θ_1+(\sum\limits_{i=1}^{m}x_i^2)θ_2+\cdots+(\sum\limits_{i=1}^{m}x_i^n)θ_n=\sum\limits_{i=1}^{m}y_i \\ (\sum\limits_{i=1}^{m}x_i)θ_0+(\sum\limits_{i=1}^{m}x_i^2)θ_1+(\sum\limits_{i=1}^{m}x_i^3)θ_2+\cdots+(\sum\limits_{i=1}^{m}x_i^{n+1})θ_n=\sum\limits_{i=1}^{m}(x_iy_i) \\ (\sum\limits_{i=1}^{m}x_i^2)θ_0+(\sum\limits_{i=1}^{m}x_i^3)θ_1+(\sum\limits_{i=1}^{m}x_i^4)θ_2+\cdots+(\sum\limits_{i=1}^{m}x_i^{n+2})θ_n=\sum\limits_{i=1}^{m}(x_i^2y_i) \\ \cdots\cdots \\ (\sum\limits_{i=1}^{m}x_i^n)θ_0+(\sum\limits_{i=1}^{m}x_i^{n+1})θ_1+(\sum\limits_{i=1}^{m}x_i^{n+2})θ_2+\cdots+(\sum\limits_{i=1}^{m}x_i^{2n})θ_n=\sum\limits_{i=1}^{m}(x_i^ny_i) \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧mθ0+(i=1∑mxi)θ1+(i=1∑mxi2)θ2+⋯+(i=1∑mxin)θn=i=1∑myi(i=1∑mxi)θ0+(i=1∑mxi2)θ1+(i=1∑mxi3)θ2+⋯+(i=1∑mxin+1)θn=i=1∑m(xiyi)(i=1∑mxi2)θ0+(i=1∑mxi3)θ1+(i=1∑mxi4)θ2+⋯+(i=1∑mxin+2)θn=i=1∑m(xi2yi)⋯⋯(i=1∑mxin)θ0+(i=1∑mxin+1)θ1+(i=1∑mxin+2)θ2+⋯+(i=1∑mxi2n)θn=i=1∑m(xinyi)
转化为矩阵形式,令:
X = [ m ∑ i = 1 m x i ∑ i = 1 m x i 2 ⋯ ∑ i = 1 m x i n ∑ i = 1 m x i ∑ i = 1 m x i 2 ∑ i = 1 m x i 3 ⋯ ∑ i = 1 m x i n + 1 ∑ i = 1 m x i 2 ∑ i = 1 m x i 3 ∑ i = 1 m x i 4 ⋯ ∑ i = 1 m x i n + 2 ⋮ ⋮ ⋮ ⋱ ⋮ ∑ i = 1 m x i n ∑ i = 1 m x i n + 1 ∑ i = 1 m x i n + 2 ⋯ ∑ i = 1 m x i 2 n ] , θ = [ θ 0 θ 1 θ 2 ⋮ θ n ] , Y = [ ∑ i = 1 m y i ∑ i = 1 m ( x i y i ) ∑ i = 1 m ( x i 2 y i ) ⋮ ∑ i = 1 m ( x i n y i ) ] X=\begin{bmatrix} m & \sum\limits_{i=1}^{m}x_i & \sum\limits_{i=1}^{m}x_i^2 & \cdots & \sum\limits_{i=1}^{m}x_i^n \\ \sum\limits_{i=1}^{m}x_i & \sum\limits_{i=1}^{m}x_i^2 & \sum\limits_{i=1}^{m}x_i^3 & \cdots & \sum\limits_{i=1}^{m}x_i^{n+1} \\ \sum\limits_{i=1}^{m}x_i^2 & \sum\limits_{i=1}^{m}x_i^3 & \sum\limits_{i=1}^{m}x_i^4 & \cdots & \sum\limits_{i=1}^{m}x_i^{n+2} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ \sum\limits_{i=1}^{m}x_i^n & \sum\limits_{i=1}^{m}x_i^{n+1} & \sum\limits_{i=1}^{m}x_i^{n+2} & \cdots & \sum\limits_{i=1}^{m}x_i^{2n} \end{bmatrix}, \quad θ=\begin{bmatrix} θ_0 \\ θ_1 \\ θ_2 \\ \vdots \\ θ_n \\ \end{bmatrix}, \quad Y=\begin{bmatrix} \sum\limits_{i=1}^{m}y_i \\ \sum\limits_{i=1}^{m}(x_iy_i) \\ \sum\limits_{i=1}^{m}(x_i^2y_i) \\ \vdots \\ \sum\limits_{i=1}^{m}(x_i^ny_i) \end{bmatrix} X=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡mi=1∑mxii=1∑mxi2⋮i=1∑mxini=1∑mxii=1∑mxi2i=1∑mxi3⋮i=1∑mxin+1i=1∑mxi2i=1∑mxi3i=1∑mxi4⋮i=1∑mxin+2⋯⋯⋯⋱⋯i=1∑mxini=1∑mxin+1i=1∑mxin+2⋮i=1∑mxi2n⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤,θ=⎣⎢⎢⎢⎢⎢⎡θ0θ1θ2⋮θn⎦⎥⎥⎥⎥⎥⎤,Y=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡i=1∑myii=1∑m(xiyi)i=1∑m(xi2yi)⋮i=1∑m(xinyi)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
则有:
X θ = Y ⇓ θ = X − 1 Y \begin{gathered} Xθ=Y \\ \Downarrow \\ θ=X^{-1}Y \end{gathered} Xθ=Y⇓θ=X−1Y
使用样本数据集构造出矩阵 X X X 和矩阵 Y Y Y 后,便可由上式解得最优函数的系数向量 θ θ θ。
2.2 矩阵法
在代数法中,构造矩阵 X X X 和矩阵 Y Y Y 较为繁琐且计算量大,我们尝试直接将误差平方和 S S S 拆解为矩阵形式。令:
X v = [ 1 x 1 x 1 2 ⋯ x 1 n 1 x 2 x 2 2 ⋯ x 2 n 1 x 3 x 3 2 ⋯ x 3 n ⋮ ⋮ ⋮ ⋱ ⋮ 1 x m x m 2 ⋯ x m n ] , θ = [ θ 0 θ 1 θ 2 ⋮ θ n ] , Y r = [ y 1 y 2 y 3 ⋮ y m ] X_v=\begin{bmatrix} 1 & x_1 & x_1^2 & \cdots & x_1^n \\ 1 & x_2 & x_2^2 & \cdots & x_2^n \\ 1 & x_3 & x_3^2 & \cdots & x_3^n \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x_m & x_m^2 & \cdots & x_m^n \\ \end{bmatrix}, \quad θ=\begin{bmatrix} θ_0 \\ θ_1 \\ θ_2 \\ \vdots \\ θ_n \\ \end{bmatrix}, \quad Y_r=\begin{bmatrix} y_1 \\ y_2 \\ y_3 \\ \vdots \\ y_m \\ \end{bmatrix} Xv=⎣⎢⎢⎢⎢⎢⎡111⋮1x1x2x3⋮xmx12x22x32⋮xm2⋯⋯⋯⋱⋯x1nx2nx3n⋮xmn⎦⎥⎥⎥⎥⎥⎤,θ=⎣⎢⎢⎢⎢⎢⎡θ0θ1θ2⋮θn⎦⎥⎥⎥⎥⎥⎤,Yr=⎣⎢⎢⎢⎢⎢⎡y1y2y3⋮ym⎦⎥⎥⎥⎥⎥⎤
则误差平方和 S S S 可写成:
S = ( X v θ − Y r ) T ( X v θ − Y r ) S=(X_vθ-Y_r)^T(X_vθ-Y_r) S=(Xvθ−Yr)T(Xvθ−Yr)
X v X_v Xv 是一个范德蒙矩阵(Vandermonde Matrix), θ θ θ 仍然是多项式系数构成的系数向量, Y r Y_r Yr 是样本数据集的输出向量。对于最优函数,应满足:
∂ S ∂ θ = ∂ [ ( X v θ − Y r ) T ( X v θ − Y r ) ] ∂ θ = X v T X v θ − X v T Y r = 0 \begin{aligned} \frac{\partial{S}}{\partial{θ}} & =\frac{\partial{[(X_vθ-Y_r)^T(X_vθ-Y_r)]}}{\partial{θ}} \\ & =X_v^TX_vθ-X_v^TY_r \\ & =0 \\ \end{aligned} ∂θ∂S=∂θ∂[(Xvθ−Yr)T(Xvθ−Yr)]=XvTXvθ−XvTYr=0
可求得最优函数的多项式系数向量 θ θ θ 为:
θ = ( X v T X v ) − 1 X v T Y r θ=(X_v^TX_v)^{-1}X_v^TY_r θ=(XvTXv)−1XvTYr
相比代数法求解中的矩阵 X X X 和矩阵 Y Y Y,矩阵法中的矩阵 X v X_v Xv 和矩阵 Y r Y_r Yr 构造起来更加简单。仔细观察,可以发现:
{ X = X v T X v Y = X v T Y r \begin{cases} X=X_v^TX_v \\ Y=X_v^TY_r \end{cases} {X=XvTXvY=XvTYr
说明两个解法是相通的。
3 代码实现
通过C++ Eigen库实现了矩阵法中的求解方式,Eigen版本为v3.3.7,运行环境为Windows10,Eigen库安装路径为 D:\eigen-3.3.7。
函数声明
#ifndef LEAST_SQUARE_METHOD_H
#define LEAST_SQUARE_METHOD_H#include <D:\eigen-3.3.7\Eigen\Dense>
#include <vector>using namespace std;/*** @brief Fit polynomial using Least Square Method.* * @param X X-axis coordinate vector of sample data.* @param Y Y-axis coordinate vector of sample data.* @param orders Fitting order which should be larger than zero. * @return Eigen::VectorXf Coefficients vector of fitted polynomial.*/
Eigen::VectorXf FitterLeastSquareMethod(vector<float> &X, vector<float> &Y, uint8_t orders);#endif
函数实现
#include "LeastSquareMethod.h"/*** @brief Fit polynomial using Least Square Method.* * @param X X-axis coordinate vector of sample data.* @param Y Y-axis coordinate vector of sample data.* @param orders Fitting order which should be larger than zero. * @return Eigen::VectorXf Coefficients vector of fitted polynomial.*/
Eigen::VectorXf FitterLeastSquareMethod(vector<float> &X, vector<float> &Y, uint8_t orders)
{// abnormal input verificationif (X.size() < 2 || Y.size() < 2 || X.size() != Y.size() || orders < 1)exit(EXIT_FAILURE);// map sample data from STL vector to eigen vectorEigen::Map<Eigen::VectorXf> sampleX(X.data(), X.size());Eigen::Map<Eigen::VectorXf> sampleY(Y.data(), Y.size());Eigen::MatrixXf mtxVandermonde(X.size(), orders + 1); // Vandermonde matrix of X-axis coordinate vector of sample dataEigen::VectorXf colVandermonde = sampleX; // Vandermonde column// construct Vandermonde matrix column by columnfor (size_t i = 0; i < orders + 1; ++i){if (0 == i){mtxVandermonde.col(0) = Eigen::VectorXf::Constant(X.size(), 1, 1);continue;}if (1 == i){mtxVandermonde.col(1) = colVandermonde;continue;}colVandermonde = colVandermonde.array()*sampleX.array();mtxVandermonde.col(i) = colVandermonde;}// calculate coefficients vector of fitted polynomialEigen::VectorXf result = (mtxVandermonde.transpose()*mtxVandermonde).inverse()*(mtxVandermonde.transpose())*sampleY;return result;
}
在函数实现中使用了一些Eigen的小技巧:
- 使用
Eigen::Map直接将样本数据由std::vector映射到Eigen::VectorXf参与运算,避免了循环数据读入 - 通过
array()方法累乘样本数据的X向量,逐列构造范德蒙矩阵,同样避免了大量的循环数据处理
拟合测试
#include <iostream>
#include "LeastSquareMethod.h"using namespace std;int main()
{float x[5] = {1, 2, 3, 4, 5};float y[5] = {7, 35, 103, 229, 431};vector<float> X(x, x + sizeof(x) / sizeof(float));vector<float> Y(y, y + sizeof(y) / sizeof(float));Eigen::VectorXf result(FitterLeastSquareMethod(X, Y, 3));cout << "\nThe coefficients vector is: \n" << endl;for (size_t i = 0; i < result.size(); ++i)cout << "theta_" << i << ": " << result[i] << endl;return 0;
}
运行编译后的可执行程序,得到如下结果:
$ ./LSM.exeThe coefficients vector is: theta_0: 1.30698
theta_1: 0.924561
theta_2: 2.0032
theta_3: 2.99976
点击这里下载完整的工程 Demo,工程使用了 cmake 编译链,你也可以下载工程后使用其中的程序文件创建符合自己开发习惯的工程。
4 总结
本文中的矩阵法本质在于,通过样本集构造范德蒙德矩阵,将一元 N 次多项式非线性回归问题转化为 N 元一次线性回归问题(即多元线性回归)。对于线性回归问题的求解,Eigen 库中有多种实现:
- LU 分解
- 基于 Householder 变换的 QR 分解
- 完全正交分解(Complete Orthogonal Decomposition,COD)
- 标准 Cholesky 分解(LLT)
- 改进型 Cholesky 分解(LDLT)
- SVD 分解
不同方法在对矩阵 A A A 的需求、求解速度、求解精度上有所差异,Eigen 官网对几种方法进行了对比总结,查看原文请移步 Linear algebra and decompositions 。
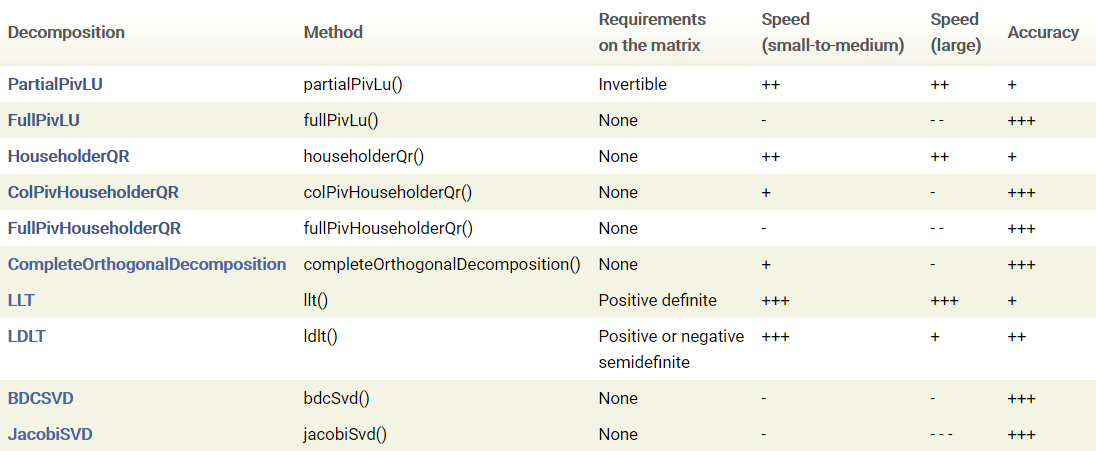
Eigen 官网在 Solving linear least squares systems 章节中讨论了 SVD 分解、QR 分解和正规方程(即使用 LDLT 解法)三种方法在求解线性最小二乘问题上的差异,并指出:SVD 分解通常精度最高但速度最慢,正规方程速度最快但精度最差,QR 分解性能介于两种方法之间。相比 SVD 分解和 QR 分解,当矩阵 A A A 病态时,正规方程解法所得结果将损失两倍精度。
利用上文所述的工程 Demo 中的小样本(三次多项式 f ( x ) = 1 + x + 2 x 2 + 3 x 3 f(x) = 1 + x + 2x^2 + 3x^3 f(x)=1+x+2x2+3x3 附近的 5 个点)构造出范德蒙德矩阵(即矩阵 A A A)后,对矩阵法(文中方法)、正规方程、householderQr 分解和 bdcSvd 分解进行了拟合实验对比:
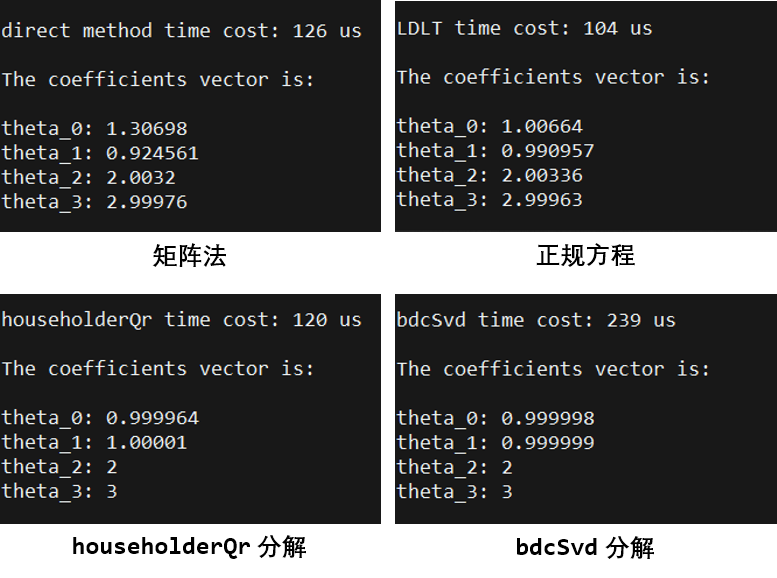
从结果可以看出,在求解速度方面:
正规方程 > householderQr分解 > 矩阵法 > bdcSvd分解 \text{正规方程}>\text{householderQr分解}>\text{矩阵法}>\text{bdcSvd分解} 正规方程>householderQr分解>矩阵法>bdcSvd分解
在求解精度方面:
bdcSvd分解 > householderQr分解 > 正规方程 > 矩阵法 \text{bdcSvd分解}>\text{householderQr分解}>\text{正规方程}>\text{矩阵法} bdcSvd分解>householderQr分解>正规方程>矩阵法
householderQr 分解综合性能较优,矩阵法综合性能较差,且有 A T A A^TA ATA 可逆的要求。
对于线性回归问题,还可通过梯度下降法进行求解,梯度下降法具体使用中还会涉及一些工程细节,例如数据的特征缩放(归一化)、步长 α \alpha α(学习率)的选择、迭代次数的设置等,具体不再展开,后面会另开一篇文章。
参考
- 如何理解最小二乘法?
- 最小二乘法拟合多项式原理以及c++实现
- 最小二乘法多项式曲线拟合原理与实现
- 最小二乘法多项式曲线拟合原理与实现(数学公式详细推导,代码方面详细注释)
- c++ 曲线拟合的最小二乘法 公式 二次多项式和三次多项式
- 最小二乘法
- 最小二乘法(least sqaure method)
- Linear algebra and decompositions
- Solving linear least squares systems
- 机器学习:用梯度下降法实现线性回归
- 机器学习:最小二乘法、最大似然估计、梯度下降法
- 最小二乘法和梯度下降法有哪些区别?
- 最小二乘法与梯度下降的区别
- 最小二乘法与梯度下降法的区别?
- 从线性回归到最小二乘法和梯度下降法
- 如何直观形象的理解方向导数与梯度以及它们之间的关系?
- 使用最小二乘法和梯度下降法进行线性回归分析