地理加权回归分析完成之后,与OLS不同的是会默认生成一张可视化图,像下面这张一样的:

这种图里面数值和颜色,主要是系数的标准误差。主要用来衡量每个系数估计值的可靠性。标准误差与实际系数值相比较小时,这些估计值的可信度会更高。较大标准误差可能表示局部多重共线性存在问题。根据官方的说法,需要检查超过2.5倍标准差的地方……这些地方可能会有问题。
虽然在软件里面,默认只显示这样一张图,但是整个GWR分析完成之后,会生成大量的数据,今天我们就来看看ArcGIS的GWR工具的结果生成的哪些结果代表了什么东西。
首先,工具运行完成之后,会生成一张辅助表 (以_supp为后缀的) ,里面会有如下信息:

下面简单对这些指标进行一下解释:
Bandwidth 或 Neighbors:
模型中,用于各个局部估计的带宽或相邻点数目的值(看你选择的是可变还是固定,如果是可变,就是带宽,固定,就是相邻点的数目),以前一而再再而三的强调过,核估计中,核函数对结果的影响很小,但是带宽对结果影响很大,所以这个参数是“地理加权回归”的最重要参数。它控制模型中的平滑程度。
这里用山东省的数据,采用AICc模型估计的带宽,因为数据用的投影坐标系,单位是米,所以这里的160536表示160公里左右。那么我们来看看,160公里的带宽,在以山东为研究区域的范围内,覆盖多大的范围:
以淄博市沂源县的中心点,进行160公里的估算,结果如下:

差不多能够包括三分之一个山东省吧,当然,我这里的这个距离是通过AICc方法估算出来的,代表了在某种最优的带宽。关于AICc或者CV模型的原理,可以参考以前的文章:
白话空间统计二十四:地理加权回归(五)
这里需要注意的时候,当你选择不同的方法的时候,得出来的所谓“最优”距离都是不一样的。
当然,如果你在设置分析参数的时候,也可以选择固定距离或者固定临近点的数目,这里就会出现你参数里面设置的值了。
ResidualSquares
指模型中的残差平方和(残差为观测所得 y 值与 GWR 模型所返回的 y 值估计值之间的差值)。此测量值越小,GWR 模型越拟合观测数据。此值还在其他多个诊断测量值中使用。
EffectiveNumber
这个值与带宽的选择有关。是拟合值的方差与系数估计值的偏差之间的折衷表示。好吧,这个说法有些拗口。下面简单来解释一下这个东东是干嘛的。
首先,地理加权回归很倚赖于带宽(或者说,依赖于临近要素),那么如果我的带宽无穷大的时候,整个分析区域里面的要素都变成了我的临近要素,这样地理加权就没有意义了,变成了全局回归也就是OLS……这样,每个系数的估计值就变成OLS的估计值。
那么对于大的带宽来说,所有的要素都被包含进回归方程里面,那么回归方程系数的有效数量接近实际的数量(地理加权的权重都是1)。而对于局部来说,它的估计值就具有相对较小的方差(局部和全局差不多,值散布范围很小),但是偏差就大了(异质性何在……)

但是如果我的带宽无限接近0的时候,除要素本身以外,旁边所有的临近要素的权重都是0,这样回归方程的有效系数就变成了回归点本身(只有观测点一个有效系数)。那么局部系数估计值将具有较大方差但偏差较低。(所有的观察点,都有独立的表现,所有要素都具有独立性,完全体现异质性)。

这两种情况,正好是两个极端,都不是我们希望的,那么,我们就需要在中间找到一个平衡点。EffectiveNumber这个值,就是用于衡量这个平衡点的数值。这个数值主要用于诊断不同的模型中使用。
Sigma
西格玛值为标准化剩余平方和(剩余平方和除以残差的有效自由度)的平方根。它是残差的估计标准差。此统计值越小越好。主要用于 AICc 计算。
AICc(关于赤则的信息,查看上面给出的白话空间统计二十四:地理加权回归(五))
AICc是模型性能的一种度量,有助于比较不同的回归模型。考虑到模型复杂性,具有较低 AICc 值的模型将更好地拟合观测数据。AICc不是拟合度的绝对度量,但对于比较适用于同一因变量且具有不同解释变量的模型非常有用。
如果两个模型的AICc值相差大于3,具有较低AICc值的模型将被视为更佳的模型。
在很多论文里面,将GWR的AICc值与OLS的AICc值进行比较,然后根据AICc的值,得出局部回归模型(GWR)比全局模型(OLS)具有更大的优势。(而不是单纯的通过比较拟合度或者性能)。
R2:R 平方是拟合度的一种度量。其值在 0.0 到 1.0 范围内变化,值越大越好。此值可解释为回归模型所涵盖的因变量方差的比例。R2 计算的分母为因变量值平方和。所以增加一个解释变量的时候,分母不变,但是分子发生改变,这就有可能出现拟合度上升的情况(大部分都是假象),所以这个值仅作为参考,更准确的度量,大多数用下面的校正R平方。
R2Adjusted:由于上述 R2 值问题,校正的 R 平方值的计算将按分子和分母的自由度对它们进行正规化。这具有对模型中变量数进行补偿的效果,因此校正的 R2 值通常小于 R2 值。但是,执行此校正时,无法将该值的解释作为所解释方差的比例。
在 GWR中,自由度的有效值是带宽的函数,因此与像OLS之类的全局模型相比,校正程度可能非常明显。因此,AICc是对模型进行比较的首选方式。
然后后面就是你的因变量和自变量了……这个不用解释。
待续未完。
这种图里面数值和颜色,主要是系数的标准误差。主要用来衡量每个系数估计值的可靠性。标准误差与实际系数值相比较小时,这些估计值的可信度会更高。较大标准误差可能表示局部多重共线性存在问题。根据官方的说法,需要检查超过2.5倍标准差的地方……这些地方可能会有问题。
虽然在软件里面,默认只显示这样一张图,但是整个GWR分析完成之后,会生成大量的数据,今天我们就来看看ArcGIS的GWR工具的结果生成的哪些结果代表了什么东西。
首先,工具运行完成之后,会生成一张辅助表 (以_supp为后缀的) ,里面会有如下信息:
下面简单对这些指标进行一下解释:
Bandwidth 或 Neighbors:
模型中,用于各个局部估计的带宽或相邻点数目的值(看你选择的是可变还是固定,如果是可变,就是带宽,固定,就是相邻点的数目),以前一而再再而三的强调过,核估计中,核函数对结果的影响很小,但是带宽对结果影响很大,所以这个参数是“地理加权回归”的最重要参数。它控制模型中的平滑程度。
这里用山东省的数据,采用AICc模型估计的带宽,因为数据用的投影坐标系,单位是米,所以这里的160536表示160公里左右。那么我们来看看,160公里的带宽,在以山东为研究区域的范围内,覆盖多大的范围:
以淄博市沂源县的中心点,进行160公里的估算,结果如下:
差不多能够包括三分之一个山东省吧,当然,我这里的这个距离是通过AICc方法估算出来的,代表了在某种最优的带宽。关于AICc或者CV模型的原理,可以参考以前的文章:
白话空间统计二十四:地理加权回归(五)
这里需要注意的时候,当你选择不同的方法的时候,得出来的所谓“最优”距离都是不一样的。
当然,如果你在设置分析参数的时候,也可以选择固定距离或者固定临近点的数目,这里就会出现你参数里面设置的值了。
ResidualSquares
指模型中的残差平方和(残差为观测所得 y 值与 GWR 模型所返回的 y 值估计值之间的差值)。此测量值越小,GWR 模型越拟合观测数据。此值还在其他多个诊断测量值中使用。
EffectiveNumber
这个值与带宽的选择有关。是拟合值的方差与系数估计值的偏差之间的折衷表示。好吧,这个说法有些拗口。下面简单来解释一下这个东东是干嘛的。
首先,地理加权回归很倚赖于带宽(或者说,依赖于临近要素),那么如果我的带宽无穷大的时候,整个分析区域里面的要素都变成了我的临近要素,这样地理加权就没有意义了,变成了全局回归也就是OLS……这样,每个系数的估计值就变成OLS的估计值。
那么对于大的带宽来说,所有的要素都被包含进回归方程里面,那么回归方程系数的有效数量接近实际的数量(地理加权的权重都是1)。而对于局部来说,它的估计值就具有相对较小的方差(局部和全局差不多,值散布范围很小),但是偏差就大了(异质性何在……)
但是如果我的带宽无限接近0的时候,除要素本身以外,旁边所有的临近要素的权重都是0,这样回归方程的有效系数就变成了回归点本身(只有观测点一个有效系数)。那么局部系数估计值将具有较大方差但偏差较低。(所有的观察点,都有独立的表现,所有要素都具有独立性,完全体现异质性)。
这两种情况,正好是两个极端,都不是我们希望的,那么,我们就需要在中间找到一个平衡点。EffectiveNumber这个值,就是用于衡量这个平衡点的数值。这个数值主要用于诊断不同的模型中使用。
Sigma
西格玛值为标准化剩余平方和(剩余平方和除以残差的有效自由度)的平方根。它是残差的估计标准差。此统计值越小越好。主要用于 AICc 计算。
AICc(关于赤则的信息,查看上面给出的白话空间统计二十四:地理加权回归(五))
AICc是模型性能的一种度量,有助于比较不同的回归模型。考虑到模型复杂性,具有较低 AICc 值的模型将更好地拟合观测数据。AICc不是拟合度的绝对度量,但对于比较适用于同一因变量且具有不同解释变量的模型非常有用。
如果两个模型的AICc值相差大于3,具有较低AICc值的模型将被视为更佳的模型。
在很多论文里面,将GWR的AICc值与OLS的AICc值进行比较,然后根据AICc的值,得出局部回归模型(GWR)比全局模型(OLS)具有更大的优势。(而不是单纯的通过比较拟合度或者性能)。
R2:R 平方是拟合度的一种度量。其值在 0.0 到 1.0 范围内变化,值越大越好。此值可解释为回归模型所涵盖的因变量方差的比例。R2 计算的分母为因变量值平方和。所以增加一个解释变量的时候,分母不变,但是分子发生改变,这就有可能出现拟合度上升的情况(大部分都是假象),所以这个值仅作为参考,更准确的度量,大多数用下面的校正R平方。
R2Adjusted:由于上述 R2 值问题,校正的 R 平方值的计算将按分子和分母的自由度对它们进行正规化。这具有对模型中变量数进行补偿的效果,因此校正的 R2 值通常小于 R2 值。但是,执行此校正时,无法将该值的解释作为所解释方差的比例。
在 GWR中,自由度的有效值是带宽的函数,因此与像OLS之类的全局模型相比,校正程度可能非常明显。因此,AICc是对模型进行比较的首选方式。
然后后面就是你的因变量和自变量了……这个不用解释。
待续未完。






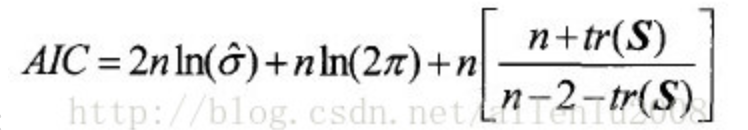


![[信息论与编码理论专题-2]:信息与熵](https://img-blog.csdnimg.cn/20210707000950378.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0hpV2FuZ1dlbkJpbmc=,size_16,color_FFFFFF,t_70)