先来尝试编码一副扑克牌,首先考虑花色+rank的方式编码,如下图,即第一张牌是0,最后一张是51(一共52张牌)

在一个集合中,假设最大元素为M,那么我们对M编码需要的最小编码长度为log2M(用二进制表示这个数字),我们将这个数字称为最坏编码长度

常见的最坏编码长度:掷硬币:log2 = 1,掷骰子:log6=3,轮盘赌:log37 = 6
编码新思路:用的频繁的字符应该给更短的长度,这样会缩短总编码长度。
目标:使编码的平均长度的期望最小,即:最小化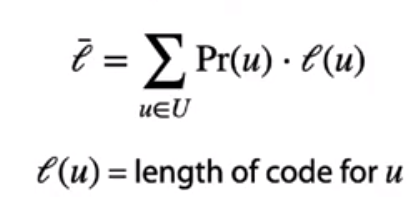

因此引入香农熵的定义,先对一个随机变量的熵进行定义
常见的香农熵:掷硬币:1,不公平硬币(0.9对0.1):0.47(熵小因为确定性提高),对这个不公平硬币编码会更容易,因为大部分时间我们都是对的
另,硬币变量叫做伯努利服从伯努利分布,两项,和为一
掷骰子:H = 2.58
可以发现,当随机变量等于所有值N的概率相等时,他的值为logN,即为最坏长度(最坏熵)

零阶经验熵:没有先验概率,通过给的例子来统计概率,然后计算熵
熵可以告诉我们,平均编码长度应该是多少,但无法告诉我们如何设计
- 对比熵公式和长度公式,或许1/pr就是我们要的长度
对于例子:1/2, 1/4, 1/8, 1/8
- 第一种:0, 10, 110, 111
aagc = 0011010,明显是可以解码的,因为这种编码保证每个编码没有相同前缀,导致无歧义
当有前缀相同,也可能是无歧义的,但需要的解码时间会变长,例:1,10,00
第一种编码方式也有相同前缀,但一定要保证下一位相同
或者说,特点是第一种编码是prefix-free的,即没有一个编码是另一个编码的前缀,我们称这种编码为前缀码(prefix code)
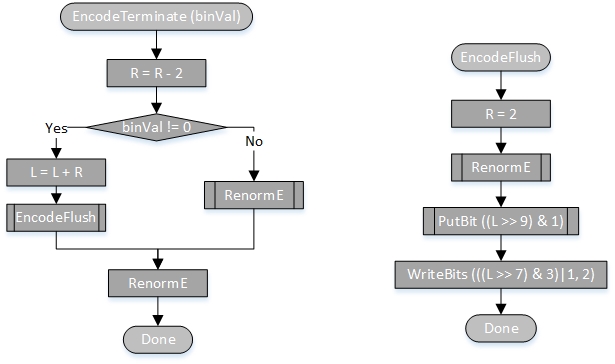
如何构建前缀码?Huffman tree

上图为构建过程,其中节点的值为在文本中出现的频次
给左边和右边赋值,即可得到各个子节点的值,注意:非叶子节点没有编码,这是关键

 此外,Huffman code更优秀之处在于,他最多只会比最佳零阶经验熵多一位(每个字符的编码)
此外,Huffman code更优秀之处在于,他最多只会比最佳零阶经验熵多一位(每个字符的编码)
还有更好的编码形式,如arithmetic coding,这里不涉及了