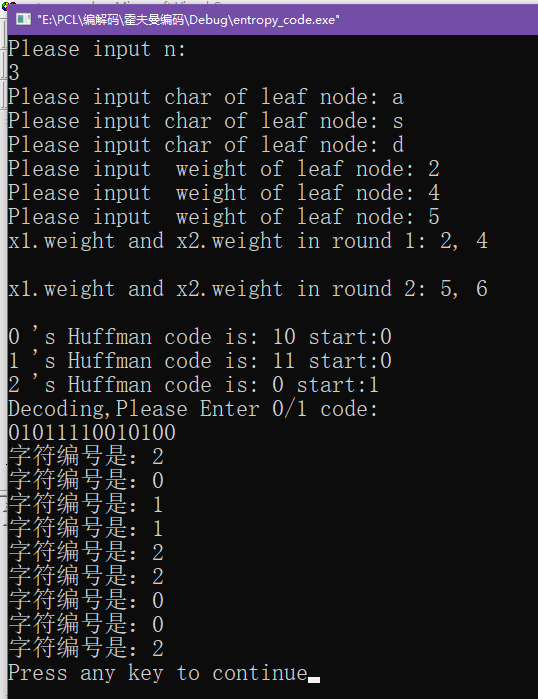
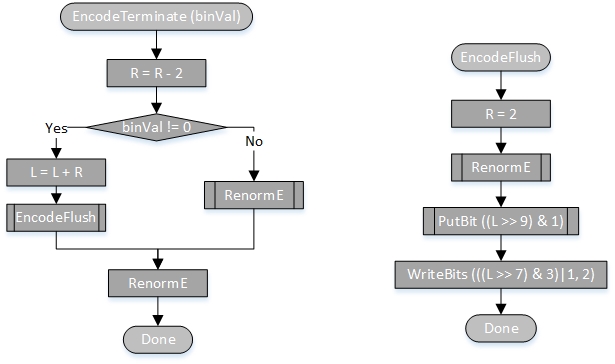
本来这一章准备直接写(
所以这次写GWR的时候,尽量少挖点坑,把该写的东西都写完,一者为了以后路过的同学少掉点坑,二者好记性不如烂笔头(烂键盘……),干脆就写完作为读书笔记或者记忆索引吧。
所以地理加权回归,可能还要写上好几章的原理,如果想快进的同学,请直接去查阅ArcGIS帮助文档中的空间统计工具箱——空间关系建模——地理加权回归部分,安装了ArcGIS for desktop的同学直接可以打开帮助文档,也可以查阅一下地址:
http://pro.arcgis.com/zh-cn/pro-app/tool-reference/spatial-statistics/geographically-weighted-regression.htm
如果觉得帮助文档太晦涩,那么就只能耐心等等忙得焦头烂额的虾神了……
今天主要来写写地理加权回归中空间权重矩阵里面的空间权函数的选择,看完之后,大家就可以解释ArcGIS中的GWR工具里面两个重要参数的意义了。
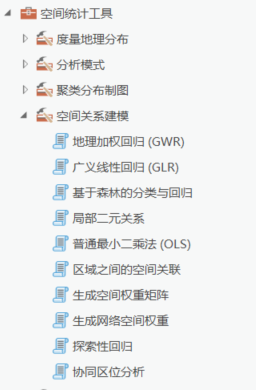
上一节写过,地理加权回归最重要的内容,就是所谓的空间权重矩阵,空间权重矩阵用是空间关系概念化计算出来的,在ArcGIS里面,有七类空间关系概念,如下所示:

首先看看距离阈值……距离阈值的概念就是

正如武学术语里面说的:近在咫尺,人尽敌国。
所以举着一把40米的长刀的话,尽可以很大方的说:“来吧,允许你先跑39米”……因为40米之内,都是攻击范围,可以看成是1……,四十米之外,都是0了,
所以距离阈值也就是一种局部回归,带来的问题请看上一篇文章,或者前几段。
剩下就只能是距离反比了,所谓的反比,就是距离越远,权重越小,看起来仿佛是很合理,因为这个说法符合是地理学第一定律的,越近关系越大,越远关系越小,所以给出这样一个距离公式:

其中α是一个常数,可以取1或者2(当然,你可以取得更大,它的意义是是否要突出距离变化的意义,参考下图)。根据ArcGIS官方的经验公式,这个值最好在0-3之间(最好不要等于0,等于0的话,d就变成常数了)。

但是,这也有一个问题,就是当我们的回归点,也是样本点的时候,就出现对回归点的观测值权值无穷大的情况……若要在每次计算的时候,把从样本数据中把这种情况剔除掉,又会出现精度降低等等一系列问题,所以反距离方法就不能直接在GWR中使用,需要进行一定的修正。
下面介绍一种在GWR中最常用的反距离改进方法函数。就是选择一个连续单调的递减函数来表示权重w和距离d之间关系,以此来克服反距离的缺点。这种方法一般来说,有很多函数都可以满足这种思想,只不过下面有两种函数因为普适性,应用最为广泛:
1、Gauss函数法
Gauss函数的表示形式如下:

函数表示如下:

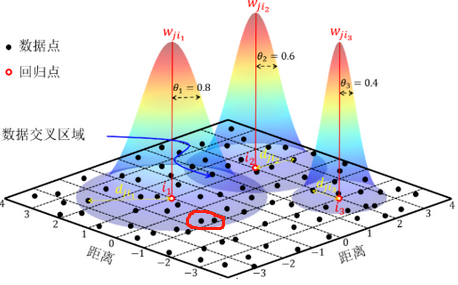
其中所谓的带宽b,指的就是权重与距离之间函数关系的非负衰减参数,就像上面那个图所示,带宽越大,权重随距离的增加衰减的越慢,带宽越小,权重随距离的增加衰减的就快。这个参数与上面反距离里面的幂函数作用是一样,但是与直接的反距离公式不同的是:在这个公式里面,当带宽为0的时候,只有回归点上的权值为1,其他各观测点的权重都无限趋近0,这样来说,回归的过程也就是数据的重新表达而已。而带宽无穷大的时候,所有的观察点权重都无限接近1,那么就变成了全局回归了。
把数据带入之后,只要带宽给定了,距离d为0的时候,权重w =1 ,权重达到最大,而随着距离的增加,权重w逐渐减少,当离得足够源的时候,权重w就无限接近于0了。所以这些足够远的点,可以看成对回归点的参数估计几乎没有影响。
但是,如果数据非常离散,带来的结果就是有大量的数据躲得远远的,这种所谓的“长尾效应”会带来大量的计算开销,所以在实际运算中,应用的是近高斯函数来替代高斯计算,把那些没有影响(或者影响很少)的点给截掉,以提高效率,在fotheringham教授1998年的论文里面,也提出,采用bi-square函数来进行计算。
bi-square 函数的表示如下:


从上图可以看出,bi-square函数其实是距离阈值法和Gauss函数发法的结合。回归点在带宽的范围内,通过高斯联系单调递减函数计算数据点的权重,超出的部分,权重全部记为0。
这两种函数,在GWR的实际计算中,是用的最多的两类方法。
下一节预告:带宽的选择,是空间权重计算的一个重要参数,下一节将简单论述带宽选择的两种方法,说完这个概念之后,就正式进入软件操作介绍部分。
待续未完。







![[信息论与编码理论专题-2]:信息与熵](https://img-blog.csdnimg.cn/20210707000950378.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0hpV2FuZ1dlbkJpbmc=,size_16,color_FFFFFF,t_70)