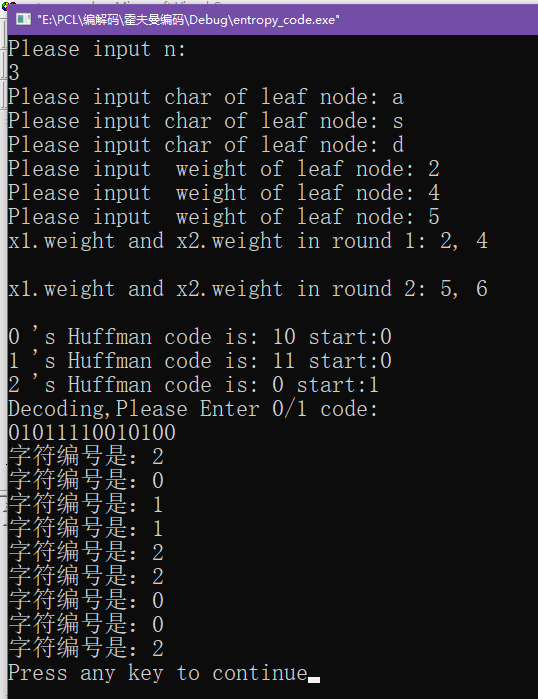
本章有数学公式……对数学过敏者慎入……
前文再续,书接上一回……上一次说到,在改进全局回归的基础上,GWR终于横空出世了,从此空间分析领域终于有了自己专用的回归算法。如果说,空间统计有别于经典统计学的两大特征:空间相关性和空间异质性,莫兰指数等可以用来量化空间相关性,那么地理加权回归,就可以用来量化空间异质性。
在对全局回归问题的改进中,局部回归可以说是最简单的方法,GWR继续应用了局部回归的思想,但是在局部窗口的模式下,遵循了所谓的“地理学第一定律”,在回归的时候,使用了空间关系作为权重加入到运算中,下面通过一个示例来讲讲GWR的基本思想。
首先看看全局回归和局部回归:

在局部回归里面,设定一个窗口,然后按照设定的窗口大小,分别在每个局部中进行回归计算,实际上看来,就是一个缩小版的全局回归。
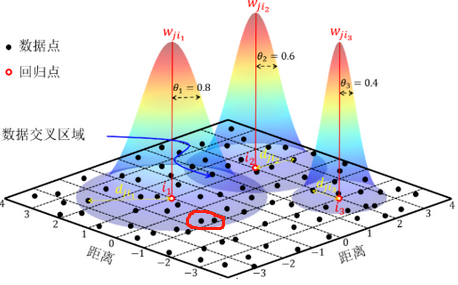
在看看地理加权回归:

地理加权和其他回归分析一样,首先要划定一个研究区域,当然,通常这个区域也可以包含整个研究数据的全体区域(以此扩展,你可以利用空间关系(比如k-临近),进行局部地理加权计算)……接下去最重要的就是利用每个要素的不同空间位置,去计算衰减函数,这个是一个连续的函数,有了这个衰减函数,当你把每个要素的空间位置(一般是坐标信息(x,y))和要素的值带入到这个函数里面之后,就可以得到一个权重值,这个值就可以带入到回归方程里面去。
所以可以看到,最重要的就是这个距离衰减函数,正因为有个这个衰减函数,得出不同权重,这个方法才会被叫做“地理加权回归分析”。这个衰减函数的理论基础,正是Tobler提出所谓的“地理学第一定律(Tobler's First Law或者Tobler's First Law of Geography):位置越接近的数据,比远处的数据对结果的影响更大。这个影响在数学上,就化为了权重。
利用这些公式,就可以对所有的样本点进行逐点的计算,每个样本点计算的时候,其他的参与计算的样本都会根据与这个样本点不同的空间关系赋予不同的权值,这样最后就可以得出每个不同样本的相关回归系数了。最后通过解读这些个系数,完成整个地理加权回归分析整个分析过程。
一直在强调这个衰减函数,那么考虑一下如果没有衰减呢?没有衰减的话,就发现所有的权重都是一样的(权重全部为1,1乘以任何数,都等于其本身)……那这个方程就变成了全局回归方程了。这样脱离了地理学第一定律,就立马变回了经典统计理论。
现在看看这个衰减函数如何来计算?
下面先贴公式,有数学恐惧症的同学请略过:

其中,W(ui,vi)是空间权重矩阵,这个概念请大家回头去看白话空间统计十七……不过鉴于大家难回头翻,我这里直接贴出来以前的内容吧:
权重矩阵,我们看看看这个空间权重矩阵到底是个啥东东:

左边这个东西,叫做无向图,由边那个,就是所谓的距离矩阵了。因为我们以前说过,在空间分析里面,需要进行空间关系的概念化,所以也通常称为空间权重矩阵。
当然这个权重矩阵为了简单明了,所以用的直接就是用最短距离作了矩阵里面的元素,比如B和C的距离,直接通过矩阵可以查询到WBC = 2 。
有权重矩阵之后,带入到矩阵中,得出如下方程:

在实际应用中,常见的空间权重函数主要有以下几种:
1、高斯函数:

其中,b是带宽(窗口大小),dij是样本点i和j的距离(至于是哪种距离,就看选择了(欧式、曼哈顿、闵可夫斯基、球面、余弦等))。
2、双重平方函数(bi-square)

这两种距离函数都非常倚赖带宽b,那么这个带宽和确定呢?国际上最普遍的方法就是用Cleveland(1979)和Bowman(1984)提出的交叉确认(cross-validation,CV)方法来确定:

这个方法,利用了拟合值来进行计算,其中

就是i处的拟合值,(为什么不用观测值?答:观测值还要跟着一个非线性的残差……直接用拟合值,更容易计算),当CV值到达最小的时候,对应的b就是所需要的带宽。由于采用不同的空间加权函数会得到不同的带宽,那么为了取得最优的带宽,Fotheringham等在2002的论文中提出了这样一个准则:当GWR模型的AIC最小的时候,就是最佳带宽。
好吧,这里又蹦出了一个新名词:AIC。。。那么这篇文章就以简介一下这个东东是个啥,来做一个结尾:
Akaike information criterion、简称AIC,是衡量统计模型拟合优良性的一种标准,是由日本统计学家赤池弘次创立和发展的。赤池信息量准则建立在熵的概念基础上,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。(这句话来自百度)
听完之后,反正虾神我的感觉是这样的:

大家有兴趣自己去研究,最后贴出历史科普信息:
下面这个老爷子就是赤池弘次,日文原版:

有兴趣的同学,可以去他的纪念站点去看看
http://www.ism.ac.jp/akaikememorial/
本文的公式,摘自北京大学出版社的《空间计量经济学》沈体雁等编著,在虾神共享的书单里面有,有兴趣的同学之间去看。
最后需要共享书单的,还是老规矩,通过公众号获取邮箱,然后发送一封需要啥东西的邮件即可。



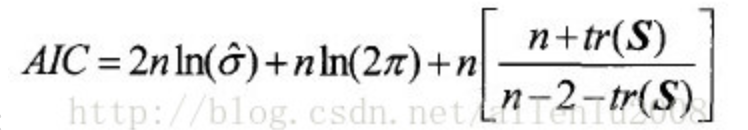


![[信息论与编码理论专题-2]:信息与熵](https://img-blog.csdnimg.cn/20210707000950378.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0hpV2FuZ1dlbkJpbmc=,size_16,color_FFFFFF,t_70)