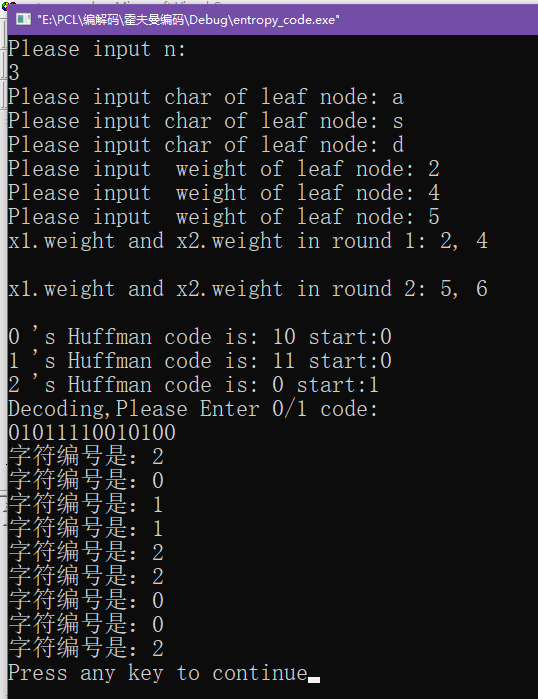
内容导读
1)回归概念介绍;
2)探索性回归工具(解释变量的选择)使用;
3)广义线性回归工具(GLR)使用;
*加更:广义线性回归工具的补充内容
4)地理加权回归工具(GWR)使用+小结。
说明:本节是这个学习笔记最后一部分。
PART/
04
地理加权回归工具(GWR)使用
上一节我们讲了GLR广义线性回归,它是一种全局模型,可以构造出最佳描述研究区域中整体数据关系的方程。如果这些关系在研究区域中是一致的,则 GLR 回归方程可以对这些关系进行很好的建模。不过,当这些关系在研究区域的不同位置具有不同的表现形式时,回归方程在很大程度上为现有关系混合的平均值;如果这些关系表示两个极值,那么全局平均值将不能为任何一个极值构建出很好的模型。当解释变量表现出不稳定的关系(例如人口变量可能是研究中某些地区911呼叫量的重要影响因子,但在其他地区可能是较弱的影响因子,这就是不平稳的表现)时,全局模型通常会失效。
为了解决非稳健的问题,提高模型的性能,可以使用将区域变化合并到回归模型中的方法,也就是GWR(Geographically Weighted Regression)地理加权回归的方法。
从数学角度上讲,广义线性回归是将整个研究区域给定一个线性方程。地理加权回归是给每一个要素一个独立的线性方程。
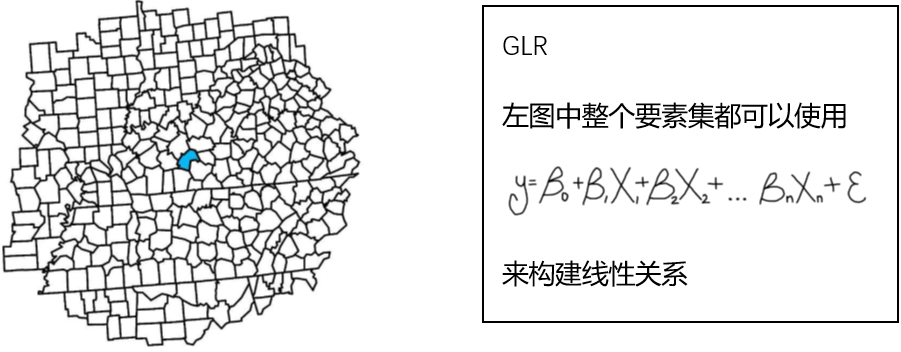
在GWR中,每一个要素的方程都是由邻近的要素计算得到的。(根据地理学第一定律,任何事物都是与其他事物相关的,只不过相近的事物关联更紧密,邻近要素对要求解的要素影响更大)
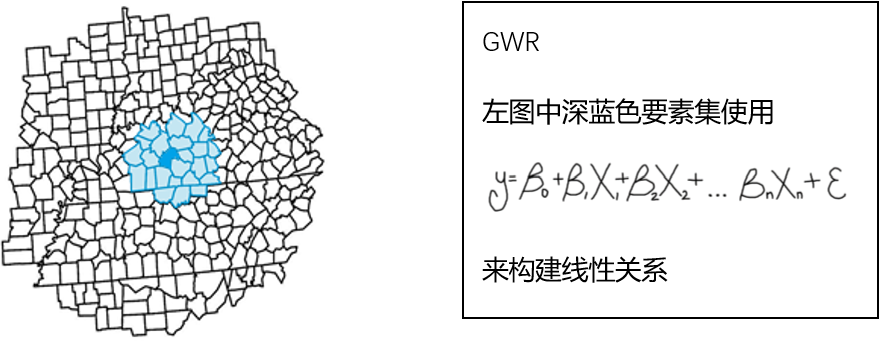
所以每一个要素的方程系数都有所不同。
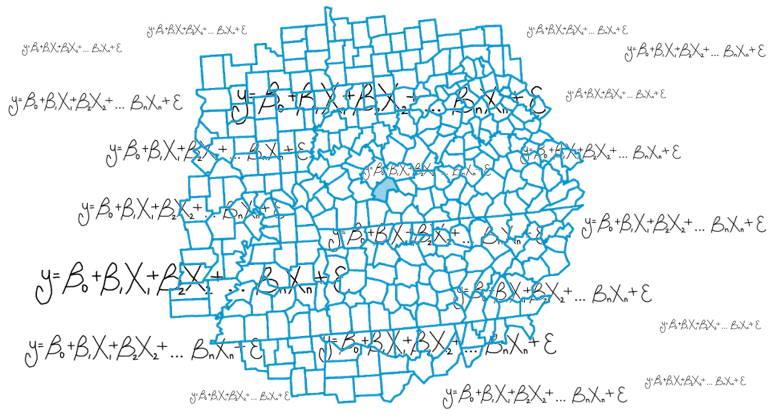
GWR实现原理
从公式中可以总结出,虽然GLR方法与GWR方法有些不同,也就是系数不同,但是其因变量与解释变量是不变的,所以通常在做GWR之前,我们可以先使用GLR或者是探索性回归工具找到解释变量,并分析GLR模型的精度,再使用GWR工具提高模型的精度。
那在GWR工具中,究竟需要哪些参数呢?这些参数具体又代表什么呢?
我们仍以ObsData911Calls-不同区域911电话呼叫数为例。
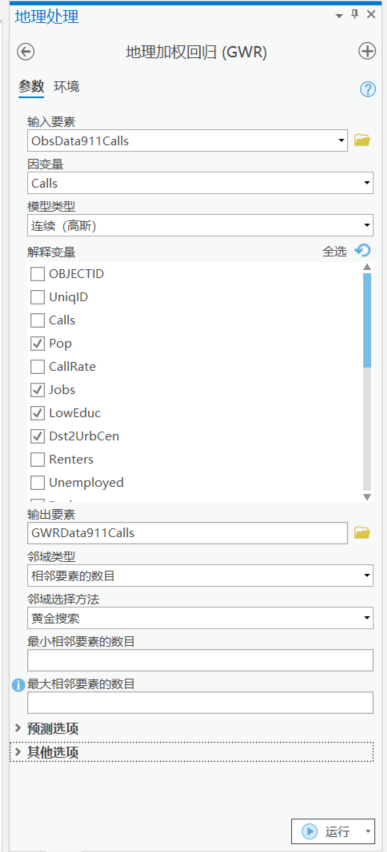
GWR工具
来看一下工具的参数:
输入要素:ObsData911Calls面要素
因变量:这里我们选择要解释的变量,也就是Y值为calls,911电话呼叫次数
模型类型:高斯、逻辑以及泊松模型。与GLR工具的模型分类是一致的,这里不再赘述。
PS:这里我们演示的仍然使用的是连续数据的高斯模型。
针对不同类型的数据可以选择不同的模型。
例如我们预测海岸线周边是否有海草栖息。是否有海草不是连续数据,只可能是观察到或者没有观察到。也就是0 和1的问题。就可以使用逻辑模型。
再比如我们想解释某地的死亡人数。这是离散的数据,就可以选择泊松模型了。
解释变量:仍然选择Pop, Jobs, LowEduc, Dst2UrbCen
设置输出要素名称GWRData911Calls
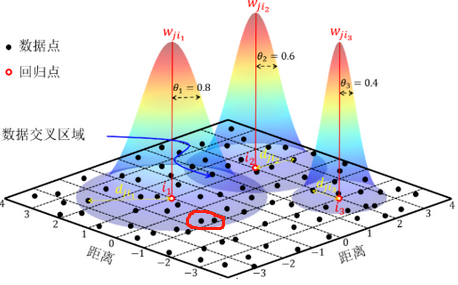
邻域也叫做带宽。表示每个局部回归方程的距离范围或相邻要素数,可以控制模型的平滑程度。下图表示使用不同的带宽得到的模型,可以发现带宽不同其模型的平滑程度不同。它是地理加权回归要考虑的最重要的参数
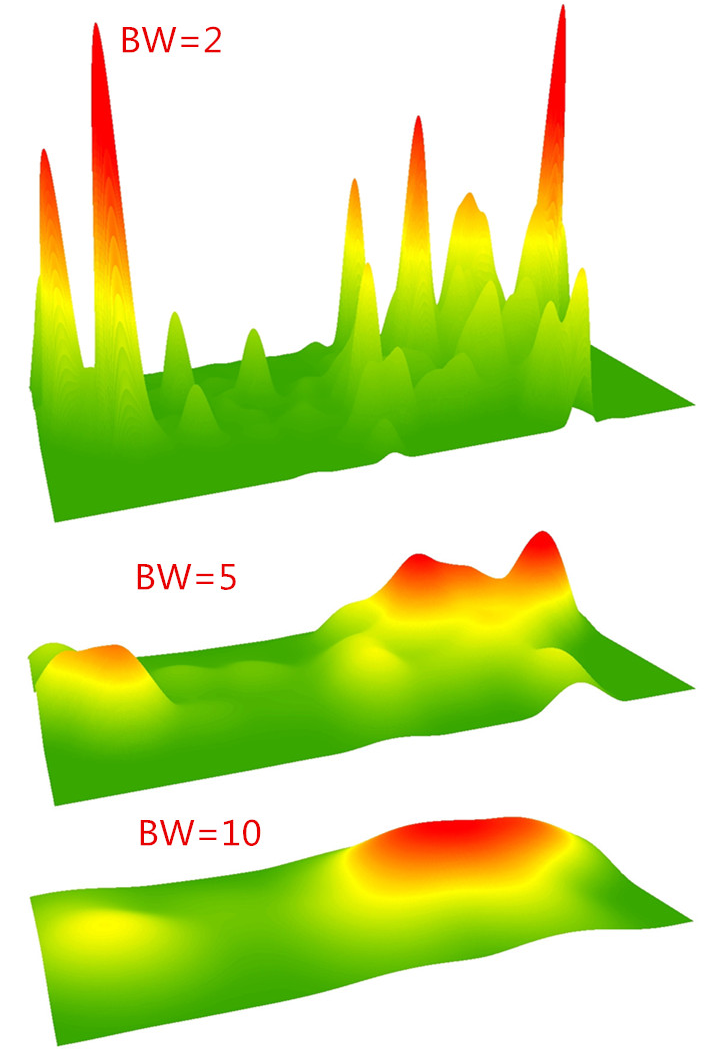
带宽对模型平滑程度的影响
在GWR中与邻域有关的参数有两个,一个是邻域类型,一个是邻域选择方法。
邻域类型可以选择相邻要素数或距离范围。
如果选择相邻要素数,也就说每个要素在解算线性方程时,参与每一个目标要素运算的邻近要素数相同。
这里我们以两个高亮显示的要素为例。不同要素选择相同的邻近要素数(要素数究竟是多少是根据邻域选择方法来确定的)
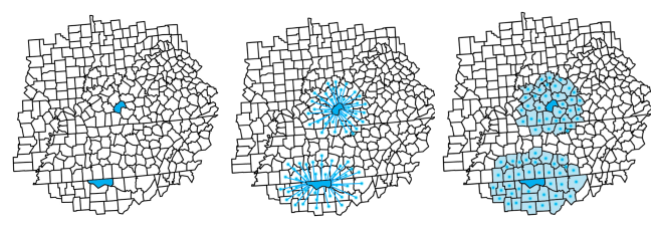
相邻要素数
如果选择距离范围,也就说每个要素在解算线性方程时,每个要素的邻域大小将保持不变 。(距离远近是根据邻域选择方法来确定的)

相同距离
本例中我们选择相邻要素数。
邻域选择方法参数可指定邻域大小的确定方式(所使用的实际距离或相邻要素数)。有三个选项黄金搜索、手动间隔以及用户定义。当你选择了这当中的某一个选项,将会在工具里新增几个参数,参数会根据这是哪个选项而不同。
黄金搜索和手动间隔都以AIC值为基础,自动找到最优的实际距离或相邻要素数。(类似于我们使用探索性回归查找解释变量的方法)
用户定义选项设置特定的邻域距离或相邻要素数
这里我们选择黄金搜索,最小搜索距离和最大搜索距离参数不填。
预测选项:GWR模型用来估计和建模变量之间的线性关系然后用这个模型来产生预测,本练习中我们只探究变量之间的线性关系,不做预测。
再来看其他选项中的局部权重方案和系数栅格工作空间。
局部权重方案也就是GWR工具通过什么方法来确定邻近要素的距离权重,这里使用了核函数来确定,核是距离衰减函数。包括高斯和双平方这两种核函数选项。简单来说二者区别在于双平方衰减的更快,默认选择双平方。(注意这里的高斯是高斯核函数,与我们选择的高斯模型不同)
系数栅格工作空间是指为模型截距和每个解释变量创建系数栅格表面。这样会生成多个栅格,用于展示各系数在不同要素上的分布强弱情况。这里选择默认的数据库为工作空间。
PS:ArcGIS Pro对GWR工作做了更新,与ArcMap中的工具参数有所不同。ArcMap中只提供了高斯核函数算法来设置局部权重。ArcGIS Pro能够涵盖ArcMap中功能。例如ArcMap中将核类型参数设置为 FIXED,带宽方法参数设置为 BANDWIDTH_PARAMETER 时,对应ArcGIS Pro中的邻域类型选择距离范围,邻域选择方法为用户定义的功能。
运行工具
地图视图结果展示
地图视图中增加了GWRData911Calls图层。并使用标准残差来进行渲染。
内容列表中的GWRData911Calls图层
同时增加了3个图表。图表与结果是相互印证的,因此在这里我们主要分析GWRData911Calls图层的内容以及结果运行出来之后的详细信息。
还增加了以INTERCEPT(截距)\POP\Jobs\Loweduc\Dst2Urben系数为渲染条件的栅格专题图。
我们来逐个看一下。
先来看一下GWRData911Calls图层属性。
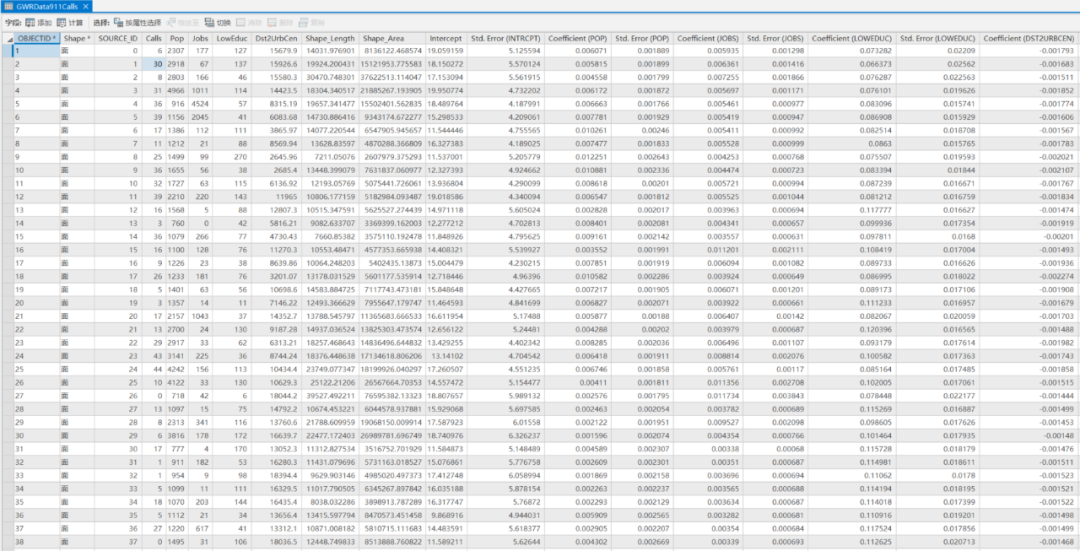
GWRData911Calls图层属性
与原始的ObsData911Calls相比较,保留了全部要素的Calls、Pop, Jobs, LowEduc, Dst2UrbCen也就是因变量和解释变量,
新增字段
增加了截距、截距的标准误差、每个解释变量的系数和标准误差、预测、残差、标准残差、条件数、影响、Cook 距离、局部 R 平方和邻域数这些字段。
细心的同学会发现Intercept、Std. Error以及Coefficient这系列字段在GLR中都是一个数字,出现在结果中的。在GWR中我们也讲过了每个要素都会构建一个方程,所以每个要素都会有Intercept、Std. Error以及Coefficient这系列属性。也充分说明了GWR是一个局部的线性回归方程。
再来看地图视图,它表示标准残差的分布情况,标准残差是残差除以标准差之后得到的数据,也就是说标准残差与残差是线性相关的。标准残差不能大于2.5或者小于-2.5,如果出现这种情况,表示这些区域的预测可能不可靠。
另外标准残差需要保证呈现随机的空间模式,这一点我们可以通过运行空间自相关工具来验证。
接下来是本节的重点了,如何看GWR结果指标
在历史工具中找到GWR工具,查看详细信息中的消息。

运行结果详细信息
结果包括黄金搜索结果,分析详细信息以及模型诊断三部分。
邻域类型这里我们设置的相邻要素数据,所以黄金搜索结果显示的是最佳要素数量,最后找到的最低值是56。黄色字体表示使用黄金搜索结果并没有找到最低AICc,也就是说黄金搜索结果中的相邻要素数据不是最优解。(这里明显可以看出相邻要素数为55时,AIC值更低,如果在选择邻域选项中选择用户指定数量为55时,结果如下图)

相邻要素数量为55时,模型拟合度更高
分析详细信息这里显示了模型中的要素数据、因变量、解释变量、相邻要素数目。
模型诊断部分内容就比较少了,包括了R方和校正R方,AIC、σ²、Sigma-Squared MLE和有效自由度这五项。
重点看校正R方和AIC。校正R方可以理解为是Local R方的均值。通过这个值我们会发现与GLR工具相比,GWR工具的拟合程度更高。再比较AIC,两者相差大于3,说明GWR模型更好一些。(GLR的值是683,GWR的值是675)
当然这里如果使用不同的参数将会得到不同的模型精度。比如邻域范围参数这里选择了距离范围,邻域选择方法设置为黄金搜索,也就是按照最佳距离进行搜索,得出的模型精度在85.15%。

设置距离范围运行GWR工具
整个模型的结果解释完了,与GLR模型一样,仍然需要验证一下残差是否是随机分布。
使用空间自相关工具,评估所表达的模式是聚类模式、离散模式还是随机模式。
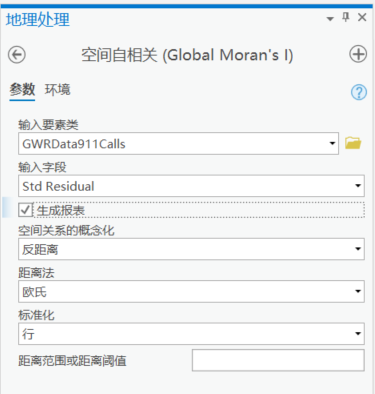
空间自相关工具
输入要素类为GWR
输入字段为标准化残差
可以选择将结果生成报表,也可以在运行结果中直接查看
空间关系的概念化选择反距离。
其他参数默认
查看其运行结果为随机模式,也就得出残差随机分布,使用GWR方法是合理的结论。
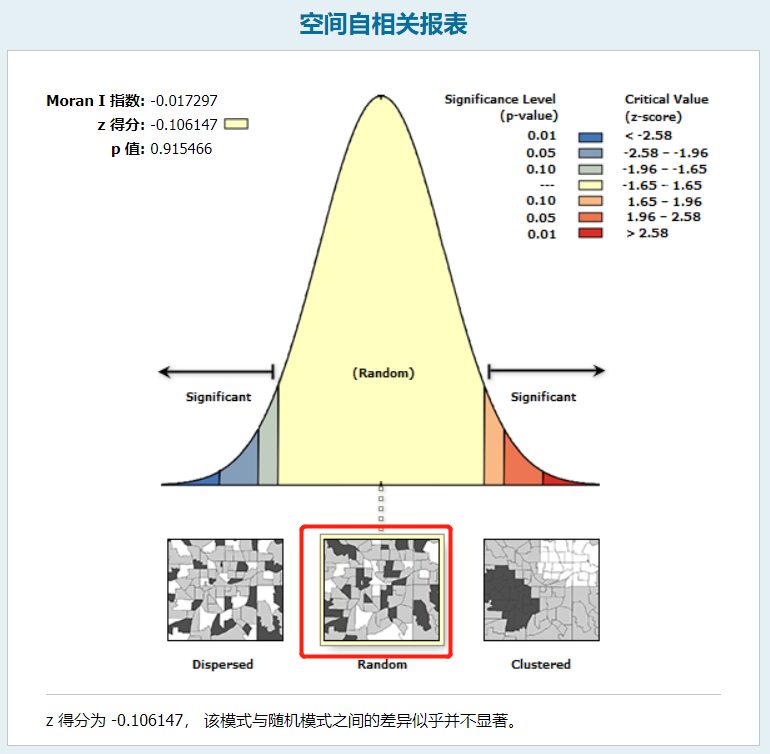
空间自相关报表
PS:GWR中加入了地理权重,这个与GLR中的解释距离要素是不同的,解释距离要素是所有要素与给定要素之间的距离,它是一个距离单位的变量,例如距离市中心5公里,地理权重则是一个没有单位的比值,表示其重要程度,例如权重为0.88。
使用工具实现回归分析不是我们的最终目的,更多时候我们是想通过这个模型进行预测或者是说明问题,或者说除了得出模型合理的结论之外,结果该如何解读呢?
以本例的GWR工具为例。我们将工具运行之后得到的系数栅格图重新进行颜色渲染。(使用

配色方案,从绿到黄表示系数从高到低)分别得到以下几张图。
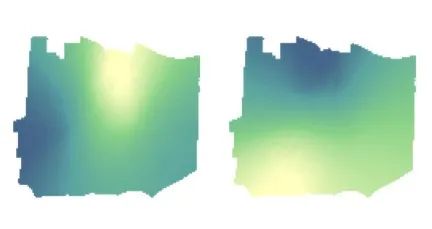
POP系数栅格图 JOBS系数栅格图

LowEduc系数栅格图 Dst2UrbCen系数栅格图
全区拨打911电话的数量受人口、就业人数、低教育程度人数以及距离市中心的程度影响。
其中低教育程度人数的影响程度最高。
从图上可以看出人口对911电话数量的影响呈现中北部向外辐射的情况,越靠近东西部人口对电话数量的影响越小。
就业人数对911电话数量的影响呈现南高北低的情况,越靠近北部就业人数对电话数量的影响越小。
低教育程度人数对911电话数量的影响呈现西高东低的情况,越靠近东部就业人数对电话数量的影响越小。
距离市中心的远近程度对911电话数量的影响呈现西高东低的情况,越靠近东部距离市中心对电话数量的影响越小。
为什么会出现上述的分布情况呢?这就需要我们从当前研究区域的经济、地理、政策、历史沿革等多角度去解释说明了。(探索模型系数的重要程度和分布情况,这一步其实是比较重要的,这个例子能够拿到的分析依据不多,类似的解释建议大家观看虾神说D卢老师的https://www.bilibili.com/video/BV1nM4y157dX?p=4 对山东省财政收入的解读)

(欢迎关注史上最不着调空间统计科普小能手虾神的公众号,收看大长篇“白话空间统计”)
以上我们就完成了ArcGIS Pro中线性回归分析工具的介绍。除了常用了OLS、GLR、GWR这三个工具之外。ArcGIS还提供了使用机器学习技术的基于森林的分类与回归工具,同样也能够实现基于地理加权的空间回归,但是这个回归不是线性的(后续有时间我们将补充这个工具的介绍)而且这个工具不需要事先确定解释变量,也不用担心出现冗余变量。GWR与基于森林的分类与回归工具算法不同,但是不能说哪个工具就更加的优秀, 一般来说如果拿到了实验要求,我们更建议大家使用两个工具都运行一下,看哪个工具更合理,模型精度更高。甚至你还可以先使用局部二元关系工具确定两个变量间(因变量与某个解释变量)属于哪种关系,例如不具有显著性、正线性、负线性、凹函数、凸函数以及未定义这几类,再决定使用哪种回归模型。
PART/
05
小结
关于ArcGIS Pro中的回归分析就全部介绍完了。我们来总结一下
一般我们拿到研究课题以及研究数据之后,如果发现其中的属性或者变量之间有一定的联系,或者需要对这些数据的变量进行建模和预测,就可以考虑使用ArcGIS Pro中的回归分析工具。
ArcGIS Pro提供了OLS、GLR、GWR以及基于随机森林的分类与回归工具。这些工具都位于空间统计工具箱中的空间关系建模工具集中。
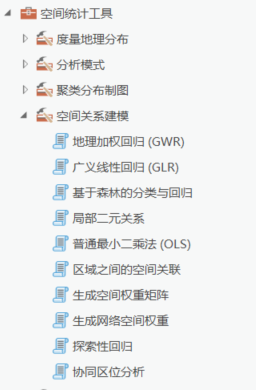
ArcGIS Pro中的回归工具
在传统的线性回归中,我们为了模型的准确性,可以先确定解释变量。ArcGIS Pro提供探索性回归工具来选择解释变量。
在选择了解释变量之后,可以先运行GLR工具(如果GLR中选择了高斯模型,就是OLS工具),再对其结果进行解释。同时确保残差的随机性(运行空间自相关工具)
GLR的结果中如果一定指标建议使用GWR工具,我们可以继续运行GWR工具,根据结果比较GLR与GWR模型的精确程度。同时确保残差的随机性。
最后,不要忘了挖掘并解释模型合理性的原因。
如有问题,欢迎留言讨论。
参考资料:
Esri RegressionAnalysisTutorial_ArcGIS10.pdf
ArcGIS Pro 中的回归和分类
https://learn.arcgis.com/zh-cn/paths/regression-and-classification-in-arcgis-pro/
https://spatialstats-analysis-1.hub.arcgis.com/
ArcGIS Pro高级培训(3)空间数据科学与空间统计学
https://www.bilibili.com/video/BV1nM4y157dX?p=4
白话空间统计之地理加权回归
https://blog.csdn.net/allenlu2008/article/details/59480437
ArcGIS 规划应用之空间回归分析
https://space.bilibili.com/307935671?spm_id_from=333.788.b_765f7570696e666f.2
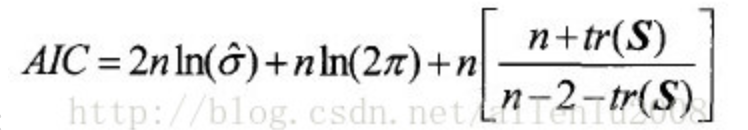


![[信息论与编码理论专题-2]:信息与熵](https://img-blog.csdnimg.cn/20210707000950378.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0hpV2FuZ1dlbkJpbmc=,size_16,color_FFFFFF,t_70)