在sklearn中使用preprocessing预处理与impute缺失值处理,两个模块进行数据预处理
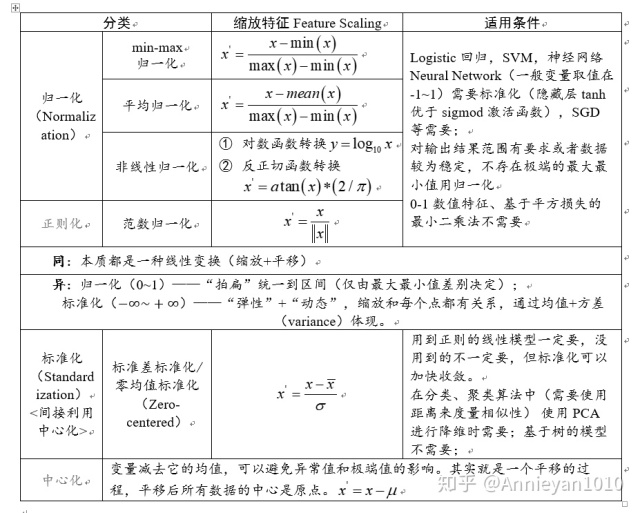
数据无量纲化:将不同量纲的数据转化到同一区间,避免某一取值的数据范围太大或太小对影响计算,加快求解速度,提高精度
无量纲化包括线性与非线性
线性无量纲化包括中心化与缩放处理
中心化:将原数据减去某一个值,将数据平移到某位置
缩放处理:将数据除以某值,将数据固定到某位置
数据归一化:将数据进行缩放与收敛处理,通常将数据归一到【0-1】区间,也可以归一到其他区间,归一化后数据服从正态分布
归一化公式:x - 最小值 / 极差(最大值-最小值)(注:计算范围是每一列数据)
sklearn进行归一化代码:
from sklearn.preprocessing import MinMaxScaler #导入归一化库
data = [[-1,2],[-0.5,6],[0,10],[1,18]]
import pandas as pd
pd.DataFrame(data)#实现归一化
one = MinMaxScaler() #实列化
scaler = one.fit(data) #fit归一化模型
re = scaler.transform(data) #接口导出结果
re
上述归一化后两列数据相同,说明数据中信息相同
r = scaler.fit_transform(data) #训练与导出结果同时进行
r
将数据归一化到【5-10】区间
data = [[7,2],[-0.5,20],[0,10],[1,18]]
s = MinMaxScaler(feature_range=[5,10]) #将数据归一化到[5-10]区间
res = s.fit_transform(data)
res 
归一化逆转
s.inverse_transform(res) #归一化后实现逆转