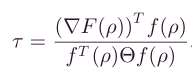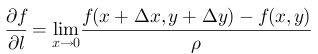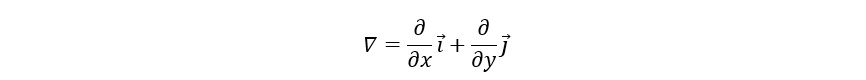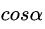前言:若需获取本文全部的手书版原稿资料,扫码关注公众号,回复: 梯度下降法 即可获取。
原创不易,转载请告知并注明出处!扫码关注公众号【机器学习与自然语言处理】,定期发布知识图谱,自然语言处理、机器学习等知识,添加微信号【17865190919】进讨论群,加好友时备注来自CSDN。

梯度下降法是机器学习中常用的参数优化算法,使用起来也是十分方便!很多人都知道梯度方向便是函数值变化最快的方向,但是有认真的思考过梯度方向是什么方向,梯度方向为什么是函数值变化最快的方向这些问题嘛,本文便以解释为什么梯度方向是函数值变化最快方向为引子引出对梯度下降算法的研究,后面也将通过线性回归详细介绍梯度下降算法以及算法调优方式及其变种
一、证明梯度方向是函数变化率最快方向
1、由导数看梯度
在很多梯度下降法教程中,都有提到梯度这个概念。从微积分角度,对多元函数的参数求偏导,将各参数偏导数以向量的形式展示出来便是梯度向量。如二元函数f(x,y)的梯度向量便是:
( ∂ f ∂ x , ∂ f ∂ y ) T {(\frac{\partial f}{\partial x},\ \frac{\partial f}{\partial y})}^{T} (∂x∂f, ∂y∂f)T
记作gradf(x,y) 或 ∇f(x,y),同理如果是三元函数,则梯度向量便是:
( ∂ f ∂ x , ∂ f ∂ y , ∂ f ∂ z ) T {(\frac{\partial f}{\partial x},\frac{\partial f}{\partial y},\frac{\partial f}{\partial z})}^{T} (∂x∂f,∂y∂f,∂z∂f)T
梯度方向是函数变化最快的方向,沿着梯度向量方向更易找到函的最大值;反之沿着梯度向量相反的方向,梯度减少最快,更易找到函数的最小值。相信有挺多人都会有疑问,为什么梯度方向是函数变化最快的方向,下面我们便从函数导数的角度讲解为什么?知其然知其所以然,探寻梯度本质。
(1) 先从单变量导数看起:
对于单变量函数f(x),在x0处导数定义为:
f ′ ( x 0 ) = y x = lim x − > 0 f ( x 0 + x ) − f ( x 0 ) x f^{'}\left( x_{0} \right) = \ \operatorname{}{\frac{y}{x} = \ \lim_{x - > 0}\frac{f\left( x_{0} + x \right) - f(x_{0})}{x}} f′(x0)= xy= x−>0limxf(x0+x)−f(x0)
公式含义如下图所示:

从几何意义上说,导数代表了函数在该点出切线斜率,表示此点处的变化率,因此单变量函数只有一个变量x在变动,所以便只有这一个方向上的变化率。因此对于多元函数来说便存在偏导数、方向导数,表示多个方向上的变化率。
(2) 偏导数到方向导数
我们以二元函数f(x,y)偏导数为例,偏导数指的是二元函数沿坐标轴的变化率:
fx(x,y) 指y方向固定不变时,函数值沿x轴的变化率;
fy(x,y) 指x方向固定不变时,函数值沿y轴的变化率
显然偏导数只是给出了函数值沿着坐标轴的变化率,这自然是完全不够的,如下图:

将上图二元函数看成一个山峰,当一个人处于黑色十字位置处想要尽快下山时,我们需有沿着任意方向的变化率才能够判断沿着哪个方向走才能够最快的下山。
当前我们已经有了沿着坐标轴x轴和y轴方向的变化率,接下来我们将推出该平面沿着任意方向的变化率,然后找出下降最快的变化率方向(可类比于已知平面的两个基向量然后表示平面内任意向量),看下图:

为了解决人如何沿着山峰变化率最快的方向走到山谷,我们先抽象问题作出几个假设:
<1> 假设山峰表面是一个二维曲面z = f(x,y)
<2> 人在山峰表面的初始点假设是M0点(x,y)
<3> 假设M0点处下山变化率最快的方向为L向量方向
<4> M1点(x + x,y +y)是L向量方向上离M0点很近的点
<5>角度φ是L向量与x轴的夹角,ρ表示M0点和M1 点之间距离: ( x ) 2 + ( y ) 2 \sqrt{{(x)}^{2}+ {(y)}^{2}} (x)2+(y)2
则函数沿任意方向L向量方向的方向导数定义为:
∂ f ∂ l = f ( x + x , y + y ) − f ( x , y ) ρ \frac{\partial f}{\partial l} = \ \operatorname{}\frac{f\left( x + x,y + y \right) - \ f(x,y)}{\rho} ∂l∂f= ρf(x+x,y+y)− f(x,y)
二维平面z = f(x,y)在M0点是可微分的,根据函数的增量有下式:
f ( x + x , y + y ) − f ( x , y ) = ∂ f ∂ x x + ∂ f ∂ y y + o ( ρ ) f\left( x + x,y + y \right) - \ f\left( x,y \right) = \ \frac{\partial f}{\partial x}x + \ \frac{\partial f}{\partial y}y + o(\rho) f(x+x,y+y)− f(x,y)= ∂x∂fx+ ∂y∂fy+o(ρ)
上式两边除以ρ可得:
f ( x + x , y + y ) − f ( x , y ) ρ = ∂ f ∂ x x ρ + ∂ f ∂ y y ρ + o ( ρ ) ρ \frac{f\left( x + x,y + y \right) - \ f\left( x,y \right)}{\rho} = \ \frac{\partial f}{\partial x}\frac{x}{\rho} + \ \frac{\partial f}{\partial y}\frac{y}{\rho} + \frac{o(\rho)}{\rho} ρf(x+x,y+y)− f(x,y)= ∂x∂fρx+ ∂y∂fρy+ρo(ρ)
其中可知:
x ρ = x ( x ) 2 + ( y ) 2 = c o s φ \frac{x}{\rho} = \ \frac{x}{\sqrt{{(x)}^{2} + {(y)}^{2}}} = cos\varphi ρx= (x)2+(y)2x=cosφ
y ρ = y ( x ) 2 + ( y ) 2 = s i n φ \frac{y}{\rho} = \ \frac{y}{\sqrt{{(x)}^{2} + {(y)}^{2}}} = sin\varphi ρy= (x)2+(y)2y=sinφ
因此有:
∂ f ∂ l = f ( x + x , y + y ) − f ( x , y ) ρ = lim ρ − > 0 ( ∂ f ∂ x c o s φ + ∂ f ∂ y s i n φ + o ( ρ ) ρ ) \frac{\partial f}{\partial l} = \ \operatorname{}\frac{f\left( x + x,y + y \right) - \ f(x,y)}{\rho} = \ \lim_{\rho - > 0}(\frac{\partial f}{\partial x}\ cos\varphi + \frac{\partial f}{\partial y}\ sin\varphi + \frac{o\left( \rho \right)}{\rho}) ∂l∂f= ρf(x+x,y+y)− f(x,y)= ρ−>0lim(∂x∂f cosφ+∂y∂f sinφ+ρo(ρ))
这里我们便推出了一个重要表达式,二维山峰平面上任意导数变化率方向可表示成:
∂ f ∂ l = ∂ f ∂ x c o s φ + ∂ f ∂ y sinφ \frac{\partial f}{\partial l} = \ \frac{\partial f}{\partial x}\ cos\varphi + \frac{\partial f}{\partial y}\text{\ sinφ} ∂l∂f= ∂x∂f cosφ+∂y∂f sinφ
别忘了我们最初的问题,我们最终的目的是要求的是变化率最快的方向,在得出任意变化率方向的表达式后,我们继续向下看:这里令:
A = ( ∂ f ∂ x , ∂ f ∂ y ) T = ( f x ( x , y ) , f y ( x , y ) ) T A = \left( \frac{\partial f}{\partial x},\ \frac{\partial f}{\partial y} \right)^{T} = \ {(f_{x}\left( x,y \right),\ f_{y}(x,y))}^{T} A=(∂x∂f, ∂y∂f)T= (fx(x,y), fy(x,y))T
l = ( c o s φ , s i n φ ) l = (cos\varphi,\ sin\varphi) l=(cosφ, sinφ)
则有任意梯度方向:
∂ f ∂ l = A L = ∣ A ∣ ∗ ∣ l ∣ ∗ c o s β β A l \frac{\partial f}{\partial l} = AL = \left| A \right|*\left| l \right|*cos\beta\ \ \ \ \text{β\ }Al ∂l∂f=AL=∣A∣∗∣l∣∗cosβ β Al
于是我们也可得出要想让∂ f/∂L最大,则β,即任意变化率向量方向L和A同方向
啊啊啊,请注意啦,这里A的方向是什么,大家仔细看: A = ( ∂ f ∂ x , ∂ f ∂ y ) T A = \left( \frac{\partial f}{\partial x},\ \frac{\partial f}{\partial y} \right)^{T} A=(∂x∂f, ∂y∂f)T
这不正是我们上面说的二元函数的梯度方向嘛。因此我们便二元函数的偏导数组成的向量:
( ∂ f ∂ x , ∂ f ∂ y ) T \left( \frac{\partial f}{\partial x},\ \frac{\partial f}{\partial y} \right)^{T} (∂x∂f, ∂y∂f)T
即定义为函数的梯度方向,也就是函数变化率最快的方向。
二、线性回归理解梯度下降法
首先我们应该明白,梯度下降法是无约束优化算法。当对某个函数求最值时便并且该函数可微时便可以使用梯度下降算法进行求解最值。下面我们先从形象上认识一下梯度下降算法:

假设我们站在山峰的某个位置,现在要一步一步下山,为了最快的到达山谷,我们走每一步时先计算时当前位置的负梯度方向,沿着负梯度方向向下走,这样我们便可以尽快的到达山谷,这边是梯度下降算法的思想。当然从上图中我们可以看出,梯度下降算法不一定会找到全局最优解,可能是局部最优解。下面我们用线性回归问题实际应用一下梯度下降算法
这里先介绍几个梯度下降法的概念,方便后续内容理解:
(1) 学习率:表示为 α,控制步长大小,即参数到达最优值的快慢
(2) 步长:即是梯度下降算法每一步沿负梯度方向前进的距离,表示为: α ∂ J ( θ ) ∂ θ \alpha\frac{\partial J(\theta)}{\partial\theta} α∂θ∂J(θ)
(3) 特征: 表示为xi(i = 0,1,2,…,n),即样本的维度
(4) 假设函数: 表示为h~θ( x ),即模型的预测输出值
(5) 损失函数: 表示为J( θ ) 即定义预测输出值和真实输出值之间的差距,本文下面例子中便利用了最小二乘法定义损失函数
这里理解一个数据的例子来理解线性回归,房屋销售的数据,数据描述的是房屋的特征和房屋销售价格的关系。其中房屋特征包括:面积、房间数量、地段、朝向等,对应的该房屋的销售价格。对于这批数据我们做出以下假设:
m: 表示数据的销售数量
x: 数据的特征,假设共有n个特征,xi(i = 0,1,2,…,n) 表示数据的n个特征
y:输出变量,也就是房屋的价格 (xj,yj):表示第j个训练样本,(j = 1,2,…,m) 共有m个数据
(xij, yij):表示第j个数据的第i个特征,i =0,1,2,…,n数据共n个特征
针对上述数据,我们希望建立一个模型来描述房屋特征和房屋售价之间的关系,并通过梯度下降法求出最优的模型。
梯度下降算法有代数法和矩阵法两种描述形式,下面将分别从代数法和矩阵法给出上述问题的解决方案
1、 梯度下降法代数法推导过程
我们假设房屋的销售价格和房屋特征是线性关系,于是我们定义假设函数为,其中θi(i= 0,1,2,…,n) 为模型参数,xi(i =0,1,2,…,n) 表示每个样本的n个特征:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + … + θ n x n = ∑ i = 1 n θ i x i ( x 0 = 1 ) h_{\theta}\left( x \right) = \theta_{0} + \theta_{1}x_{1} + \theta_{2}x_{2} + \ldots + \theta_{n}x_{n}\ \ = \ \sum_{i = 1}^{n}{\theta_{i}x_{i}\text{\ \ \ \ }}\ (x_{0} = 1) hθ(x)=θ0+θ1x1+θ2x2+…+θnxn = i=1∑nθixi (x0=1)
损失函数:利用最小二乘法可得模型的损失函数为,其中m表示共有m个样本(这里请区分n表示的是每个样本的n个特征,m表示的则是样本数量):
J ( θ ) = 1 2 ∑ j = 1 m ( h θ ( x 0 j , x 1 ( j ) , … x n ( j ) ) − y ( j ) ) 2 = 1 2 ∑ j = 1 m ( h θ ( x ( j ) ) − y ( j ) ) 2 J\left( \theta \right) = \frac{1}{2}\sum_{j = 1}^{m}{(h_{\theta}\left( {x_{0}}^{j},{x_{1}}^{\left( j \right)},\ldots{x_{n}}^{\left( j \right)} \right)\ - \ y^{(j)})}^{2}\ = \frac{1}{2}\sum_{j = 1}^{m}{(h_{\theta}\left( x^{\left( j \right)} \right)\ - \ y^{(j)})}^{2} J(θ)=21j=1∑m(hθ(x0j,x1(j),…xn(j)) − y(j))2 =21j=1∑m(hθ(x(j)) − y(j))2
接下来通过梯度下降法J( θ),通过不断优化参数θ得出最优解
第一步求解损失函数的梯度,其中θ是向量: [ θ 0 , θ 1 , … , θ n ] T {\lbrack\theta_{0},\theta_{1},\ldots,\theta_{n}\rbrack}^{T} [θ0,θ1,…,θn]T
∂ J ( θ ) ∂ θ = ∑ j = 1 m ( h θ ( x ( j ) ) − y ( j ) ) ∗ x i ( j ) \frac{\partial J(\theta)}{\partial\theta} = \ \sum_{j = 1}^{m}{\left( h_{\theta}\left( x^{(j)} \right) - y^{(j)} \right)*x_{i}^{(j)}} ∂θ∂J(θ)= j=1∑m(hθ(x(j))−y(j))∗xi(j)
已知函数梯度便可以通过梯度迭代参数,其中α是学习率:
θ : = θ − α ∗ ∑ j = 1 m ( h θ ( x ( j ) ) − y ( j ) ) ∗ x i ( j ) \theta\ : = \ \theta - \ \alpha*\sum_{j = 1}^{m}{\left( h_{\theta}\left( x^{(j)} \right) - y^{(j)} \right)*x_{i}^{(j)}} θ := θ− α∗j=1∑m(hθ(x(j))−y(j))∗xi(j)
上式参数何时达到最优?因为在每次沿着梯度的方向进行迭代时,参数减去步长,当不断接近局部最小值时,步子会越来越小,梯度也会逐渐趋向0,下面给出参数迭代收敛条件:
(1) 两次迭代的值变化很小时;
(2) 迭代的过程中需要最小化的那个值不再变小时迭代收敛
2、 梯度下降法矩阵法推导过程
矩阵法和代数法解决问题的思路是一致的,不同的是数据的表示形式。首先我们仍旧给出模型的假设函数和损失函数。首先我们令
X = [ x 0 , x 1 , … , x n ] m ∗ n X = \left\lbrack x_{0},x_{1},\ldots,x_{n} \right\rbrack\ \ \ \ \ m*n X=[x0,x1,…,xn] m∗n
m*n维矩阵为数据输入,m表示共m个样本,n表示每个样本共n个特征,其中x0 = 1 是为了数据整齐而假设的多出一维的特征,无实际含义
θ = [ θ 0 , θ 1 , … , θ n ] T n ∗ 1 \mathbf{\theta = \ }{\lbrack\theta_{0},\theta_{1},\ldots,\theta_{n}\rbrack}^{T}\ \ n*1 θ= [θ0,θ1,…,θn]T n∗1
因此假设函数为:
h θ ( x ) = X θ h_{\theta}\left( x \right)\mathbf{= X\theta} hθ(x)=Xθ
利用最小二乘法定义损失函数为:
J ( θ ) = 1 2 ( X θ − Y ) T ( X θ − Y ) J\left( \theta \right) = \frac{1}{2}\left( \mathbf{X\theta - Y} \right)^{T}\left( \mathbf{X\theta - Y} \right) J(θ)=21(Xθ−Y)T(Xθ−Y)
其中Y为m*1维向量,表示m个数据实际放假值,接下来仍旧使用梯度下降法最优化对模型参数进行调优,第一步求损失函数梯度为:
∂ J ( θ ) ∂ θ = X T ( X θ − Y ) \frac{\partial J(\theta)}{\partial\theta} = \ X^{T}\left( \mathbf{X\theta - Y} \right) ∂θ∂J(θ)= XT(Xθ−Y)
于是得到参数θ的迭代公式:
θ : = θ − αX T ( X θ − Y ) \theta\ : = \ \theta\ - \ \text{αX}^{T}\left( \mathbf{X\theta - Y} \right) θ := θ − αXT(Xθ−Y)
上述求梯度是用到了矩阵求导,这里给出上述用到的矩阵求导的两个公式:
公式1: ∂ ∂ X ( X X T ) = 2 X \frac{\partial}{\partial X}\left( XX^{T} \right) = \ 2X ∂X∂(XXT)= 2X
公式2: ∂ ∂ θ ( Xθ ) = X T \frac{\partial}{\partial\theta\ }\left( \text{Xθ\ } \right) = \ X^{T} ∂θ ∂(Xθ )= XT
迭代收敛条件和代数法中描述的相同
三、梯度下降法调优及变种
1 、梯度下降算法可优化主要有以下三点:
<1> 步长: 由学习率来控制,步长过小则迭代缓慢,步长过大则错过最优解,步长公式表示为:
α ∂ J ( θ ) ∂ θ \alpha\frac{\partial J(\theta)}{\partial\theta} α∂θ∂J(θ)
<2> 参数初始值: 初始值的选择不同得到的解可能不同,这就是梯度下降算法出现局部最优解的原因,可以通过多次选取初始值得到全局最优解,参数向量表示为:
[ θ 0 , θ 1 , … , θ n ] T {\lbrack\theta_{0},\theta_{1},\ldots,\theta_{n}\rbrack}^{T} [θ0,θ1,…,θn]T
<3> 归一化: 因为输入数据特征的取值范围不一样,可能使得迭代缓慢。因此我们可以对数据特征进行归一化操作,即求出特征的期望和标准差,利用下式进行归一化处理:
x − m e a n ( x ) s t d ( x ) \frac{x - mean(x)}{std(x)} std(x)x−mean(x)
2、梯度下降算法的可以有以下变种:
<1>按照每次迭代处理数据量的多少可分为:
(1) 批量梯度下降法:上述推导式使用的公式便是批量梯度下降法,即每次迭代都会使用全部的样本进行更新,好处是准确,但每次迭代都需计算全部样本,参数迭代公式为:
θ : = θ − α ∗ ∑ j = 1 m ( h θ ( x ( j ) ) − y ( j ) ) ∗ x i ( j ) \theta\ : = \ \theta - \ \alpha*\sum_{j = 1}^{m}{\left( h_{\theta}\left( x^{(j)} \right) - y^{(j)} \right)*x_{i}^{(j)}} θ := θ− α∗j=1∑m(hθ(x(j))−y(j))∗xi(j)
(2) 随机梯度下降法:原理和批量梯度类似,只是每次迭代只使用一个样本进行参数迭代,好处是每次迭代速度快,但缺点便是解可能不是最优,不能很快收敛到最优解,公式为:
θ : = θ − α ∗ ( ( h θ ( x ( j ) ) − y ( j ) ) ∗ x i ( j ) ) \theta\ : = \ \theta - \ \alpha*\left( \left( h_{\theta}\left( x^{\left( j \right)} \right) - y^{\left( j \right)} \right)*x_{i}^{\left( j \right)} \right) θ := θ− α∗((hθ(x(j))−y(j))∗xi(j))
(3) 小批量梯度下降法:是批量梯度下降法和随机梯度下降法的这种,每次选取一部分样本进行迭代,参数迭代公式为:
θ : = θ − α ∗ ∑ j = t t + x − 1 ( h θ ( x ( j ) ) − y ( j ) ) ∗ x i ( j ) \theta\ : = \ \theta - \ \alpha*\sum_{j = t}^{t + x - 1}{\left( h_{\theta}\left( x^{(j)} \right) - y^{(j)} \right)*x_{i}^{(j)}} θ := θ− α∗j=t∑t+x−1(hθ(x(j))−y(j))∗xi(j)
<2>按照梯度迭代的方向可分为:
(1)梯度下降法:既是上面一直讨论的,是沿着负梯度方向求函数最小值,即每次迭代是减去学习率乘以梯度
(2)梯度上升法:和梯度下降法想法,梯度上升法每次迭代是沿着正梯度方向,是求函数极大值使用,参数迭代公式为:
θ : = θ + α ∗ ∑ j = 1 m ( h θ ( x ( j ) ) − y ( j ) ) ∗ x i ( j ) \theta\ : = \ \theta + \ \alpha*\sum_{j = 1}^{m}{\left( h_{\theta}\left( x^{(j)} \right) - y^{(j)} \right)*x_{i}^{(j)}} θ := θ+ α∗j=1∑m(hθ(x(j))−y(j))∗xi(j)
欢迎积极讨论!