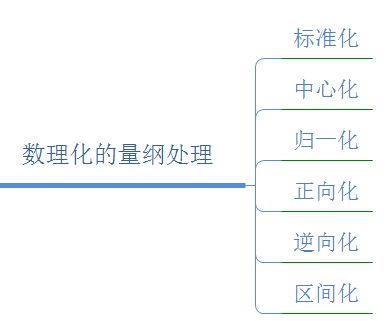
数据归一化方法
数据标准化(normalization)数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。
数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。
一、 标准化
标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过 标准化映射成在区间[0,1]中的值 ,其公式为:
新数据=(原数据-极小值)/(极大值-极小值)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:
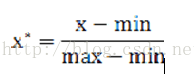
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
二、z-score 标准化
这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
新数据=(原数据-均值)/标准差
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
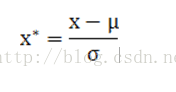
其中 u为所有样本数据的均值, *所有样本数据的标准差。
例如:spss默认的标准化方法就是z-score标准化。
用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。
步骤如下:
1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ;
2.进行标准化处理:
zij=(xij-xi)/si
其中:zij为标准化后的变量值;xij为实际变量值。
3.将逆指标前的正负号对调。
标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
三、Decimal scaling小数定标标准化
这种方法通过移动数据的小数点位置来进行标准化。小数点移动多少位取决于属性A的取值中的最大绝对值。将属性A的原始值x使用decimal scaling标准化到x'的计算方法是:
x'=x/(10*j)
其中,j是满足条件的最小整数。
注意,标准化会对原始数据做出改变,因此需要保存所使用的标准化方法的参数,以便对后续的数据进行统一的标准化。
四、对数Logistic模式
新数据=1/(1+e^(-原数据))
对数函数转换,表达式如下:
y=log10(x)
说明:以10为底的对数函数转换。
五、模糊量化模式
新数据=1/2+1/2sin[3.1415/(极大值-极小值)*(X-(极大值-极小值)/2) ] X为原数据
反余切函数转换,表达式如下:
y=atan(x)*2/PI
资料整理自网络,感谢原作者。


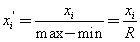

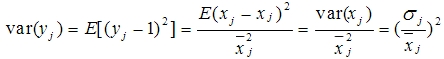



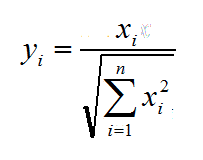
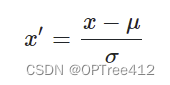
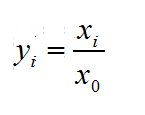

![LaTex排版技巧:[15]公式太长如何换行](https://imgsa.baidu.com/exp/w=500/sign=185604bfd2160924dc25a21be406359b/b8014a90f603738d07dc6fcbb11bb051f919ec41.jpg)
