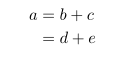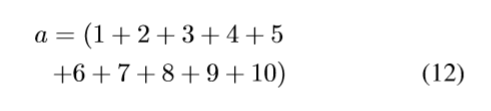数据预处理——无量纲化处理
1.无量纲化定义
无量纲化,也称为数据的规范化,是指不同指标之间由于存在量纲不同致其不具可比性,故首先需将指标进行无量纲化,消除量纲影响后再进行接下来的分析。
2.无量纲化方法
无量纲化方法有很多,但是从几何角度来说可以分为:直线型、折线型、曲线形无量纲化方法。
(1)直线型无量纲化方法
直线型无量纲化方法是指指标原始值与无量纲化后的指标值之间呈现线性关系,常用的线性量化方法有阈值法、标准化法与比重法。
- 阈值法。阀值化是将指标的实际值与该指标的阀值相比较,从而得到指标评价值的方法,公式如下:
y i = x i / x 0 y_i = x_i/x_0 yi=xi/x0
y i y_i yi :指标转化后的评价值; x i x_i xi:指标实际值; x 0 x_0 x0:该指标的阀值
由上述公式可以看出,如果阀值确定的太大,评价值对指标变化的反应就会很迟钝,如果阀值太小,评价值又会过于灵敏地反应指标的变化。这两种情况都会使最终合成的综合评价难以准确地反映客观实际。因此,阀值的确定对综合评价是至关重要的。因此,确定阀值应注重以下几点:
第一,根据综合评价的目的来确定,如果动态评价,阀值可以定为被评价对象的历史最好水平,也可以基期水平。如果是对计划完成情况的评价,阀值则为计划数。对于实际水平的评价,阀值可以是同类被评价对象的最好水平或平均水平。
第二,阀值的确定应便于综合评价为原则。 - 规范化。规格化也称为极差正规化,先找出每个指标的最大值和最小值,这两者之差称为极差,然后以每个指标实际值xi减去该指标的最小值,再除以极差,就得到正规化评价值 y i y_i yi,公式如下:
y i = ( x i − x m i n ) / ( x m a x − x m i n ) y_i=(x_i-x_{min})/(x_{max}-x_{min}) yi=(xi−xmin)/(xmax−xmin)
这种无量纲方法实际上是求各种评价指标实际值在该指标全距中所处位置的比率。而且取值范围均为:0-1 - 中心化标准化)。中心化也称为均值化,先求出每个评价指标的样本均值,在将指标的实际值xi与该指标的均值相比较,就得到中心化后的评价值yi,公式如下:
y i = x i / x 0 y_i=x_i/x_0 yi=xi/x0
其中 x 0 x_0 x0为数据的平均值。 - 标准化。标准化也称为z-score变换,求出每个指标的样本均值xi和标准差S就得到标准化评价值 y i y_i yi,公式如下
y i = ( x i − x 0 ) / s y_i=(x_i-x_0)/s yi=(xi−x0)/s
其中 x 0 x_0 x0为均值, s s s为标准差
当被评价对象(样本)较多是,才能用该方法进行无量纲化处理,可以看出,评价值在-1—1之间。 - 比重法。比重化主要为多目标决策分析中的一些方法所采用。公式如下:
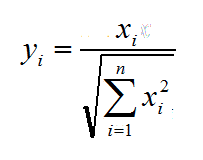
(2)折线型无量纲化方法
折线型无量纲化适用于被评价事物呈现阶段性变化,即指标值在不同阶段变化对事物总体水平影响是不一样的。
虽然折线型无量纲化方法比直线型无量纲化方法更符合实际情况,但是要想确定指标值的转折点不是一件容易的事情,需要对数据有足够的了解和掌握。
(3)曲线形无量纲化方法
有些事物发展的阶段性变化并不是很明显,而前、中、后期的发展情况又各不相同,就是说指标值的变化是循序渐进的,并不是突变的,在这种情况下,曲线形无量纲化方法也更为合适。
(4)模糊无量纲化方法
综合评价中的评价指标可以分为正向指标(即指标值越大越好)、逆指标(即指标值越小越好)和适度指标(即指标值落在某个区间最好,大了、小了都不好),指标彼此之间“好”与“坏”并没有一个标准,在很大程度上具有一定的模糊性,这时候可以选择此方法对指标进行无量纲化处理,有兴趣自行搜索学习。
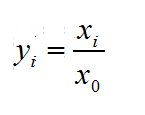

![LaTex排版技巧:[15]公式太长如何换行](https://imgsa.baidu.com/exp/w=500/sign=185604bfd2160924dc25a21be406359b/b8014a90f603738d07dc6fcbb11bb051f919ec41.jpg)