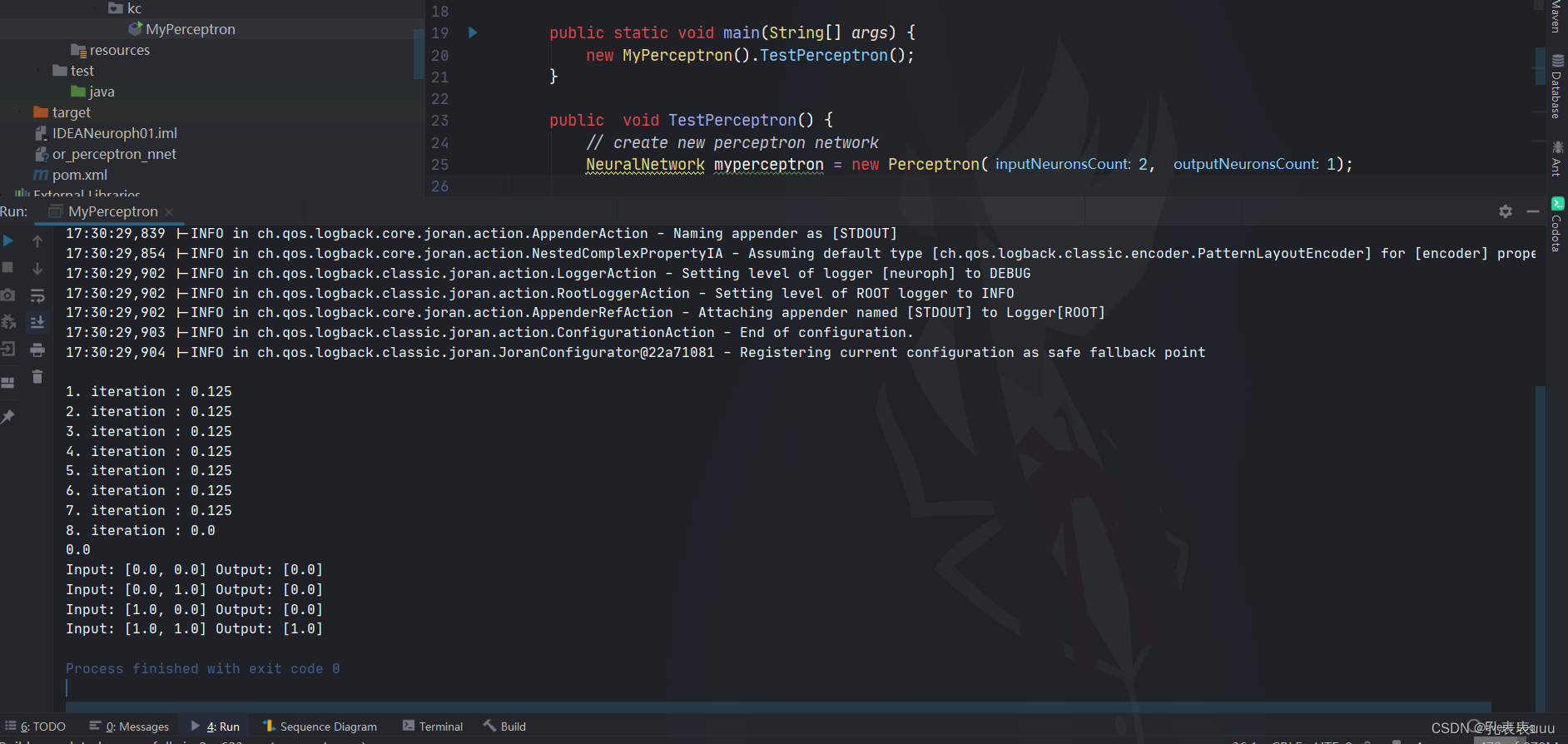
运行环境:jre1.7
以下是神经网络的主体类
public class NeuralNetwork {int inputNodes;//输入层节点数int hiddenNodes;//隐藏层节点数int outputNodes;//输出层节点数double learningRate;//学习率double[][] weight_ih;//输入层与隐藏层之间的权重double[][] weight_ho;//隐藏层与输出层之间的权重double[][] error_output;//输出层的误差double[][] error_hidden;//隐藏层的误差public NeuralNetwork(int inputNodes, int hiddenNodes, int outputNodes, double learningRate) {super();this.inputNodes = inputNodes;this.hiddenNodes = hiddenNodes;this.outputNodes = outputNodes;this.learningRate = learningRate;}//初始化网络public void init() {//创建权重矩阵weight_ih = new double[this.hiddenNodes][this.inputNodes];weight_ho = new double[this.outputNodes][this.hiddenNodes];//创建误差列表error_output = new double[this.outputNodes][1];error_hidden = new double[this.hiddenNodes][1];//设置输入层与隐藏层之间的权重this.weight_init(weight_ih);this.weight_init(weight_ho);}//训练网络public void train(double[][] input_list, double[][] target_list){//隐藏层的输入double[][] hidden_input = this.dot(weight_ih, input_list);//隐藏层的输出double[][] hidden_output = this.apply_funcS(hidden_input);//输出层的输入double[][] output_input = this.dot(weight_ho, hidden_output);//输出层的输出double[][] output_output = this.apply_funcS(output_input);//输出层输出误差error_output = this.error_compute(target_list, output_output);//隐藏层输出误差error_hidden = this.dot(this.transpose(weight_ho), error_output);//更新隐藏层与输出层的权重weight_ho = this.update_weight(weight_ho, learningRate, error_output, output_output, hidden_output);//更新输入层与隐藏层的权重weight_ih = this.update_weight(weight_ih, learningRate, error_hidden, hidden_output, input_list);}//根据输入列表查询输出结果public double[][] query(double[][] input_list){//隐藏层的输入double[][] hidden_input = this.dot(weight_ih, input_list);//隐藏层的输出double[][] hidden_output = this.apply_funcS(hidden_input);//输出层的输入double[][] output_input = this.dot(weight_ho, hidden_output);//输出层的输出double[][] output_output = this.apply_funcS(output_input);return output_output;}/** 以下是工具方法*///打印矩阵public void query_matrix(double[][] target) {for(int i=0;i<target.length;i++) {for(int j=0;j<target[i].length;j++) {//System.out.println("["+(i+1)+","+(j+1)+"]:"+target[i][j]+" ");System.out.print(target[i][j]+" ");}System.out.println();}}//激活函数public double functionS(double x) {double temp = 1/(Math.pow(Math.E, x));double output = 1/(1+temp);return output;}//权重初始化public void weight_init(double[][] weight_matrix) {for(int i=0; i<weight_matrix.length; i++) {for(int j=0; j<weight_matrix[i].length; j++) {//此处还可以加入随机正态分布以进一步增加准确度weight_matrix[i][j] = Math.random()*2 - 1;}}}//矩阵乘法 public double[][] dot(double[][] matrix1,double[][] matrix2){if (matrix1[0].length != matrix2.length) {System.err.println("矩阵格式不正确");return null;} double result[][] = new double[matrix1.length][matrix2[0].length];for (int i = 0; i < matrix1.length; i++)for (int j = 0; j < matrix2[0].length; j++)//result矩阵的第i行第j列所对应的数值,等于matrix1矩阵的第i行分别乘以matrix2矩阵的第j列之和for (int k = 0; k < matrix2.length; k++)result[i][j] += matrix1[i][k] * matrix2[k][j];return result;}//矩阵每个对应的位置的数仅仅相乘得到新矩阵,不是矩阵乘法public double[][] matrixMltp(double[][] matrix1,double[][] matrix2){if(matrix1.length != matrix2.length || matrix1[0].length != matrix2[0].length) {System.err.println("矩阵格式不正确");return null;}double[][] result = new double[matrix1.length][matrix1[0].length];for(int i=0;i<result.length;i++) {for(int j=0;j<result[0].length;j++) {result[i][j] = matrix1[i][j] * matrix2[i][j];}}return result;}//矩阵每个对应的位置的数仅仅相减得到新矩阵,第一个矩阵 - 第二个矩阵public double[][] matrixMinus(double[][] matrix1,double[][] matrix2){if(matrix1.length != matrix2.length || matrix1[0].length != matrix2[0].length) {System.err.println("矩阵格式不正确");return null;}double[][] result = new double[matrix1.length][matrix1[0].length];for(int i=0;i<result.length;i++) {for(int j=0;j<result[0].length;j++) {result[i][j] = matrix1[i][j] - matrix2[i][j];}}return result;}//矩阵每个对应的位置的数仅仅相减得到新矩阵,第一个矩阵 + 第二个矩阵public double[][] matrixAdd(double[][] matrix1,double[][] matrix2){if(matrix1.length != matrix2.length || matrix1[0].length != matrix2[0].length) {System.err.println("矩阵格式不正确");return null;}double[][] result = new double[matrix1.length][matrix1[0].length];for(int i=0;i<result.length;i++) {for(int j=0;j<result[0].length;j++) {result[i][j] = matrix1[i][j] + matrix2[i][j];}}return result;}/** 生成固定大小的矩阵,并且将矩阵的每一个位置都填充固定的数字* number:矩阵中要填充的数字* y:矩阵的列的长度,也就是二维数组的第一个长度* x:矩阵的行的长度,也就是二维数组的第二个长度*/public double[][] geneMatrixByNumber(double number,int y, int x){double[][] result = new double[y][x];for(int i=0;i<result.length;i++) {for(int j=0;j<result[0].length;j++) {result[i][j] = number;}}return result;}//矩阵转置public double[][] transpose(double[][] matrix){double[][] result = new double[matrix[0].length][matrix.length];for(int i=0; i<matrix.length; i++) {for(int j=0; j<matrix[i].length; j++) {result[j][i] = matrix[i][j];}}return result;}//列表应用激活函数函数public double[][] apply_funcS(double[][] input_matrix){double[][] result = new double[input_matrix.length][input_matrix[0].length];for(int i=0;i<result.length;i++){for(int j=0;j<result[i].length;j++) {result[i][j] = functionS(input_matrix[i][j]);}}return result;}//误差计算(输出层与隐藏层)public double[][] error_compute(double[][] target_matrix, double[][] real_output_matrix){double[][] result = new double[target_matrix.length][target_matrix[0].length];for(int i=0;i<result.length;i++){for(int j=0;j<result[i].length;j++) {result[i][j] = target_matrix[i][j] - real_output_matrix[i][j];}}return result;}/** 权重更新* weight_matrix 需要更新的权重矩阵* learningRate 学习因子* error_right 需要更新的权重矩阵的右边一列的误差* output_right 需要更新的权重矩阵的右边一列的输出* output_left 需要更新的权重矩阵的左边一列的输出* 返回值 更新后的权重矩阵*/public double[][] update_weight(double[][] weight_matrix, double learningRate, double[][] error_right, double[][] output_right, double[][] output_left){/** 目的是计算 learningRate * error_right * output_right * (1- output_right) * output_left* 由于 learningRate * error_right * output_right * (1- output_right) 都是权重右侧的矩阵所以单独简单相乘得到一个矩阵* 然后再与output_left做矩阵乘法运算*/double[][] learningRateMatrix = this.geneMatrixByNumber(learningRate, error_right.length, error_right[0].length);double[][] temp1 = this.matrixMltp(learningRateMatrix, error_right);//最终得到learningRate * error_right * output_right 的矩阵temp1 = this.matrixMltp(temp1, output_right);//数字1的矩阵,用于计算1- output_rightdouble[][] one = this.geneMatrixByNumber(1, output_right.length, output_right[0].length);//1- output_right的结果矩阵double[][] temp2 = this.matrixMinus(one, output_right);//learningRate * error_right * output_right * (1- output_right)结果double[][] temp = this.matrixMltp(temp1, temp2);/** 获取最终变化量* 即:learningRate * error_right * output_right * (1- output_right) * output_left结果* 备注:因为output_left 与 前面的乘积矩阵格式相同,为了配合矩阵乘法,我们需要提前将output_left矩阵进行转置*/double[][] variation = this.dot(temp,this.transpose(output_left));//原矩阵+变化量double[][] result = this.matrixAdd(weight_matrix, variation);return result;}}以下是神经网络处理数据的工具类
public class Tools {//读取文件中的数据,一行一个数据,用于训练或者测试public ArrayList<String> getData(String filePath, int dataCount) {ArrayList<String> data = new ArrayList<String>();try {File file = new File(filePath);@SuppressWarnings("resource")BufferedReader reader = new BufferedReader(new FileReader(file));String str = new String();for(int i=1; i<=dataCount; i++) {str = reader.readLine();data.add(str);}} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}return data;}//将训练数据格式化public HashMap<double[][],double[][]> formatTrainData(ArrayList<String> trainData) {HashMap<double[][],double[][]> map = new HashMap<double[][],double[][]>();for(String temp:trainData) {String[] trainDataStringArray = temp.split(",");//取出第一个数字,得到训练的目标值int targetNum = Integer.parseInt(trainDataStringArray[0]);//创建存储训练数据的矩阵,由于之前的数组第一个数是目标值,所以矩阵的列的长度是数组长度-1double[][] trainDataDoubleArray = new double[trainDataStringArray.length-1][1];//将数据处理成0-1的数,并存在矩阵中,从第二个数开始循环for(int i=1; i<trainDataStringArray.length; i++) {trainDataDoubleArray[i-1][0] = (Double.parseDouble(trainDataStringArray[i])/ 255 * 0.99) +0.01;}//创建目标值的矩阵,目标值为0-9所以矩阵列长度为10double[][] trainDataTargetArray = new double[10][1];//将数组中所有值初始化为0.01for(int i=0; i<trainDataTargetArray.length; i++) {//将目标值大小对应数组下标的值改为最大,如目标值为9那么把数组中第10个数改为最大,因为第1个数是0所以9就是第10个数if(i == targetNum) {trainDataTargetArray[i][0]=0.99;continue;}trainDataTargetArray[i][0]=0.01;}map.put(trainDataDoubleArray, trainDataTargetArray);}return map;}//将测试数据格式化public HashMap<double[][],Integer> formatTestData(ArrayList<String> testData) {HashMap<double[][],Integer> map = new HashMap<double[][],Integer>();for(String temp:testData) {String[] dataStringArray = temp.split(",");//数据中第一个数为目标值,将其取出int targetNum = Integer.parseInt(dataStringArray[0]);//创建存储测试数据的矩阵,由于之前的数组第一个数是目标值,所以矩阵的列的长度是数组长度-1double[][] dataDoubleArray = new double[dataStringArray.length-1][1];//将数据处理成0-1的数,并存在矩阵中,从第二个数开始循环for(int i=1; i<dataStringArray.length; i++) {dataDoubleArray[i-1][0] = (Double.parseDouble(dataStringArray[i])/ 255 * 0.99) +0.01;}map.put(dataDoubleArray, Integer.valueOf(targetNum));}return map;}//根据输出数组中的数的大小确定目标值public int getTargetNumber(double[][] output) {int targetNumber = 0;double temp = 0;for(int i=0;i<output.length;i++) {if(output[i][0]>temp) {temp = output[i][0];targetNumber = i;}}return targetNumber;}}以下是神经网络运行的main函数
public class Test {public static void main(String[] args) {// TODO Auto-generated method stubint inputNodes = 784;//输入层节点个数int hiddenNodes = 500;//隐藏层节点个数int outputNodes = 10;//输出层节点个数double learningRate = 0.1;//学习率int trainDataNumber = 50000;//训练数据的个数int testDataNumber = 1000;//测试数据的个数NeuralNetwork network = new NeuralNetwork(inputNodes, hiddenNodes, outputNodes, learningRate);network.init();//初始化神经网络Tools tools = new Tools();/** 获取训练数据* 这里的mnist_train.csv文件中一共有60000个训练数据,不一定全用,这里用了50000个数据,可以通过trainDataNumber变量自由定义*/ArrayList<String> trainData = tools.getData("/Users/apple/mnist_train.csv",trainDataNumber);//格式化训练数据HashMap<double[][],double[][]> trainMap = tools.formatTrainData(trainData);//记录当前训练个数int count = 0;//训练精神网络for(Map.Entry<double[][],double[][]> entry:trainMap.entrySet()) {network.train(entry.getKey(), entry.getValue());count++;//显示训练进度System.out.println("训练进度:"+count+"/"+trainDataNumber);}/** 获取测试数据* 这里的mnist_test.csv文件中一共有10000个训练数据,不一定全用,这里用了1000个数据,可以通过testDataNumber变量自由定义*/ArrayList<String> testData = tools.getData("/Users/apple/mnist_test.csv",testDataNumber);//格式化测试数据HashMap<double[][],Integer> testMap = tools.formatTestData(testData);//记录正确的个数double correctCount = 0;//测试神经网络for(Map.Entry<double[][],Integer> entry:testMap.entrySet()) {double[][] output = network.query(entry.getKey());//获取结果矩阵中目标数(取矩阵中数字最大的数的对应下标)int targetNumber = tools.getTargetNumber(output);System.out.println("targetNumber:"+targetNumber);System.out.println("realNumber:"+entry.getValue());if(targetNumber == entry.getValue()) {correctCount++;}}System.out.println("训练数据个数:"+trainData.size()+" 测试数据个数:"+testData.size());System.out.println("正确个数:"+correctCount);System.out.println("正确率:"+correctCount/testData.size()*100+"%");}}下面是运行的结果

训练数据和测试数据可以从以下网址获取:(如果打开后直接显示具体数据,可以右键点击然后另存为文件)
https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_test_10.csv 该链接是10条测试数据的记录
https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_train_100.csv 该链接是100条训练数据的记录
http://www.pjreddie.com/media/files/mnist_test.csv 该链接是完整测试数据 约10000个标记样本
http://www.pjreddie.com/media/files/mnist_train.csv 该链接是完整训练数据 约60000个标记样本