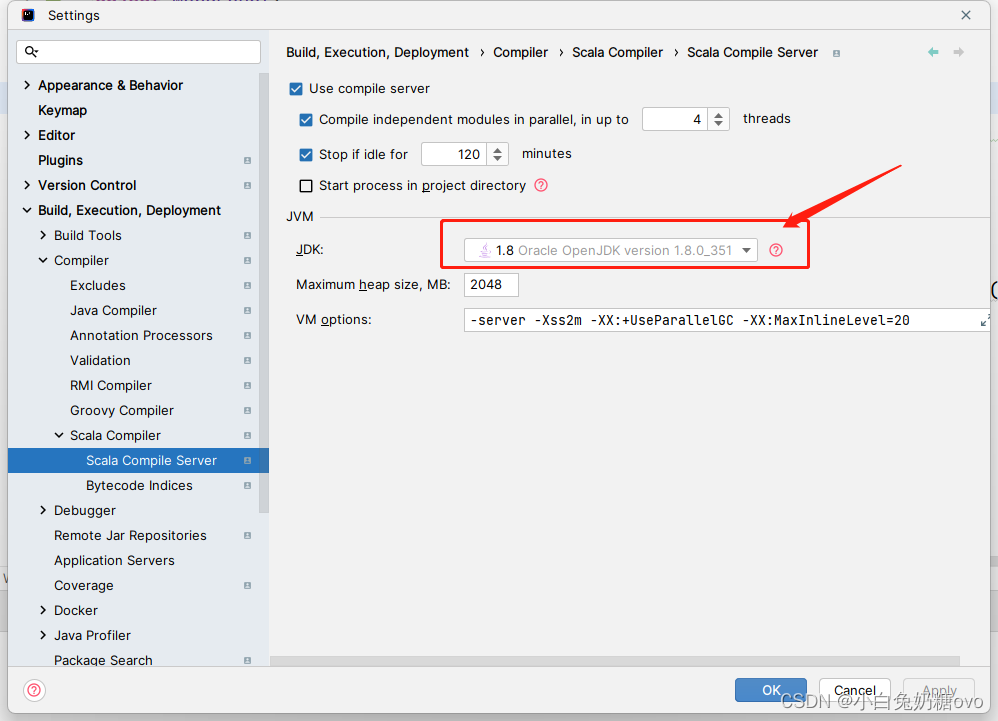
目前Intellij IDEA对scala支持的比较好,本文使用idea构建spark开发环境。
1.准备工作
jdk版本,scala sdk环境(我的是jdk1.8,scala 2.1)
scala官网下载地址:http://www.scala-lang.org/download/
2.Intellij IDEA
下载地址https://www.jetbrains.com/idea/download/#section=windows
3.idea安装scala插件

scala插件离线下载地址:https://plugins.jetbrains.com/plugin/1347-scala
到这里,idea的scala插件环境已经OK了。
4.idea通过maven搭建spark环境
新建maven工程

填写GroupId和ArtifactId

第三步很重要,首先是你的Intellij IDEA里有Maven,一般的新版本都会自带maven,而且maven的目录在IDEA安装路径下plugins下就能找到,然后再Maven home directory地址中填写maven相对应的路径,然后完成即可。
接下来在pom.xml文件中加入spark环境所需要的一些依赖包。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.spark_study</groupId><artifactId>spark_study</artifactId><version>1.0-SNAPSHOT</version><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spark.version>2.1.0</spark.version><scala.version>2.11</scala.version><hadoop.version>2.6.0</hadoop.version></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0</version></dependency><!--<dependency> //报错,所以先注释了<groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka_${scala.version}</artifactId><version>${spark.version}</version></dependency>--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.39</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency></dependencies><repositories><repository><id>central</id><name>Maven Repository Switchboard</name><layout>default</layout><url>http://repo2.maven.org/maven2</url><snapshots><enabled>false</enabled></snapshots></repository></repositories><build><sourceDirectory>src/main/scala</sourceDirectory><testSourceDirectory>src/test/scala</testSourceDirectory></build>
</project>
注意这里面的版本一定要对应好,我这里的spark版本是2.1.0对应的scala是2.11,因为是通过spark-core_${scala.version}是找spark依赖包的
(这一步参考网上,自己没试过)这里要注意下几个小问题:
这里面会有src/main/scala和src/test/scala需要你自己在对应项目目录下构建这两个文件夹路径,若不构建会报错。

5.环境搭建好后新建package,和scala class
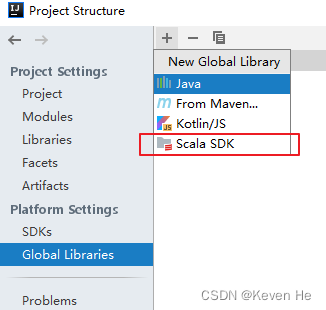
new发现没有 scala class时
打开设置界面的路径如下: 主界面File——>Project Structure——>modules

- 如上图红圈所示,我们可以根据对项目的任意目录进行这五种目录类型标注,这个知识点非常非常重要,必须会。
- Sources 一般用于标注类似 src 这种可编译目录。有时候我们不单单项目的 src 目录要可编译,还有其他一些特别的目录也许我们也要作为可编译的目录,就需要对该目录进行此标注。只有 Sources 这种可编译目录才可以新建 Java 类和包,这一点需要牢记。
- Tests 一般用于标注可编译的单元测试目录。在规范的 maven 项目结构中,顶级目录是 src,maven 的 src 我们是不会设置为 Sources 的,而是在其子目录 main 目录下的 java 目录,我们会设置为 Sources。而单元测试的目录是 src - test - java,这里的 java 目录我们就会设置为 Tests,表示该目录是作为可编译的单元测试目录。一般这个和后面几个我们都是在 maven 项目下进行配置的,但是我这里还是会先说说。从这一点我们也可以看出 IntelliJ IDEA 对 maven 项目的支持是比彻底的。
- Resources 一般用于标注资源文件目录。在 maven 项目下,资源目录是单独划分出来的,其目录为:src - main -resources,这里的 resources 目录我们就会设置为 Resources,表示该目录是作为资源目录。资源目录下的文件是会被编译到输出目录下的。
- Test Resources 一般用于标注单元测试的资源文件目录。在 maven 项目下,单元测试的资源目录是单独划分出来的,其目录为:src - test -resources,这里的 resources 目录我们就会设置为 Test Resources,表示该目录是作为单元测试的资源目录。资源目录下的文件是会被编译到输出目录下的。
- Excluded 一般用于标注排除目录。被排除的目录不会被 IntelliJ IDEA 创建索引,相当于被 IntelliJ IDEA 废弃,该目录下的代码文件是不具备代码检查和智能提示等常规代码功能。
通过上面的介绍,我们知道对于非 maven 项目我们只要会设置 src 即可。如上图箭头所示,被标注的目录会在右侧有一个总的概括。其中 classes 虽然是 Excluded 目录,但是它有特殊性,可以不显示在这里。
最后新建scala class

新建scala class时,kind选择object类型

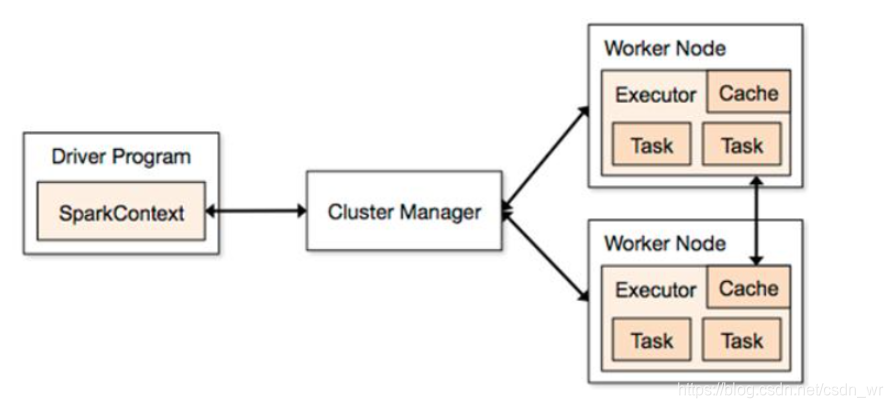
到这里,所有环境都搞定了,愉快的进行spark开发吧!