一、序言
神经网络是模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
在深度学习领域,神经网络就是我们深度学习的灵魂,如果我们想依靠算法实现一些功能,就必须依托不同的神经网络结构,所以很有必要搞懂神经网络的类型和结构。
二、神经网络的类型
神经网络按照不同的分类方式,会有多种形式的划分。
第一种分类方式是按照类型来分,包含两种类型,分别为前馈神经网络和反馈神经网络。
我们分别解释下,首先前馈神经网络(Feedforward Neural Networks),它是我们最常用的神经网络类型。比如我们所说的BP神经网络,DNN网络,CNN网络等,举例如图所示:
前馈神经网络之DNN网络举例

前馈神经网络之CNN结构举例
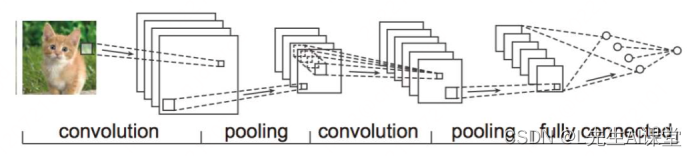
这种结构一般定义为一个有向无环图,信号只能沿着最终输出的那个方向传播,每一时刻间的输入互不影响。
然后另一种结构是反馈神经网络(Feedback Neural Networks),也称为递归神经网络(Recurent Neural Networks),它是一个网络中环的结构,如下图所示的RNN网络:

反馈神经网络之RNN网络
可以发现信号不再是沿直线传播,而是有一些环路。这里环路的原因是因为在RNN网络中上一时刻的输出要给到下一时刻,比如图中的Xt-1时刻的输出St-1会作为Xt时刻的输入,时刻间的输入不再是独立的。
第二种分类方式是按照网络的深浅来分类的,包含浅层神经网络和深度神经网络。
浅层神经网络就是我们所说的传统神经网络,这种网络结构包含的层次比较少,一般不会超过两层,所以浅层神经网络最开始的效果并不理想。如下图所示为浅层神经网络。
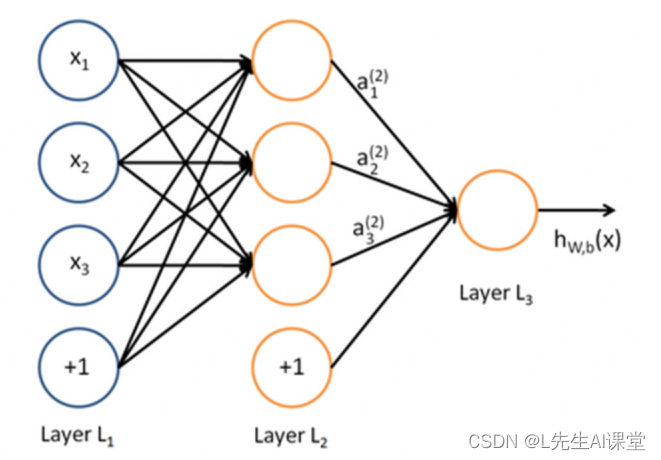
浅层神经网络示例
我们可以发现只有其中只有两个隐藏层。
另外一种就是深度神经网络。所谓深度实际上就是把把层次加深,增加其中的隐藏层。比如下图:
深度神经网络示例
可以发现深度神经网络中包含着最少两层隐藏层,这些隐藏层经过高阶的特征提取会让我们的神经网络真正去发掘数据内部隐藏的特性。所以深度神经网络的发展和演变让神经网络的枝叶更加枝繁叶茂,从而能够模拟更多的场景,解决更多的算法需求。
三、神经网络的结构
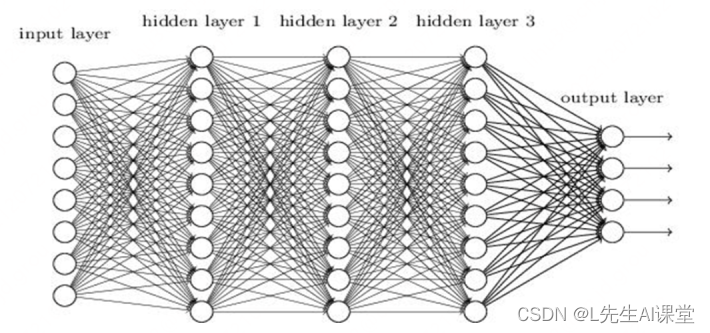
了解完深度学习的类型划分之后,我们再看下神经网络的具体结构。我们现在所说的神经网络是指深度神经网络,即隐藏层大于2层的这种结构。
我们以4层的结构为例为大家讲解,包含一个输入层(Input Layer),2个隐藏层,分别为隐藏层1(Hidden Layer1),隐藏层2(Hidden Layer2),和一个输出层(Output Layer)。如图所示:
神经网络结构示意
我们需要了解各个层次之间的参数关系。
首先看下输入层和第一个隐藏层之间的结构,如图所示:
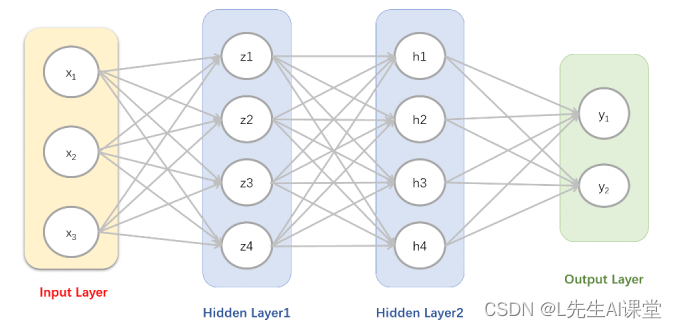
输入层和隐藏层1之间的结构
这里面x1,x2,x3是指样本特征属,相当于有3个特征。假设我们的数据有100条,当数据给到输入层的时候,每个样本有3个特征,所以我们X的形状即为X=(100,3)这样的一个输入矩阵,其中的100为样本个数,3为特征个数。
那这之间的参数个数是多少呢?举个例子来分析下,比如对于其中的一个特征x1来说,连接到下一层的4个节点z1,z2,z3,z4上。如图所示:
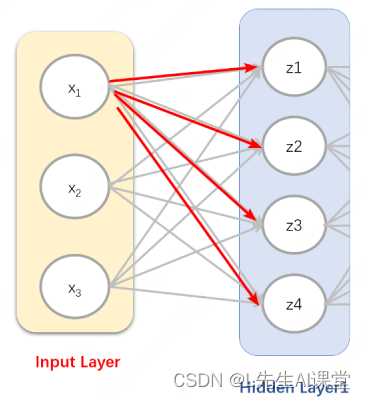
X1连接到下一层的4个节点示意
可以发现一个特征对应4个参数,而输入的时候总共有3个特征,所以中间的这种连线总的个数也就是3*4=12个,即我们的输入层和隐藏层之间的W形状为W1=(3,4)这样的一个矩阵。
输入层和隐藏层之间需要按照线性组合WX+b这种形式进行组合。所以输入数据矩阵X和W点乘的结果为(100,3)*(3,4)=(100,4)这样一个形状的矩阵。即100行4列,表示的含义为100个数据经过第一个隐藏层的变化,每个数据转变成4个隐特征。相当于隐藏层把我们上一层的输入在本层做了特征的转换和抽取,而这正是隐藏层节点的功能和作用。特征转换完以后再经过激活函数Sigmod的激活输入到下一层。
然后再来看下隐藏层1和隐藏层2之间的结构,如图所示:
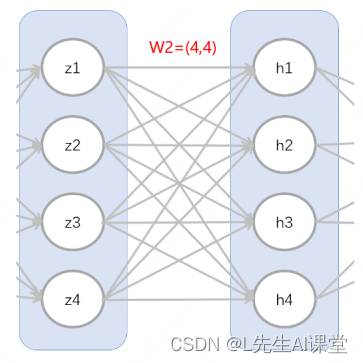
隐藏层1和隐藏层2之间的结构示意
可以发现隐藏层1和隐藏层2之间的结构类似于输入层和隐藏层1之间结构,所以参数个数的分析也是类似的。这里面z1到z4所构成的输入矩阵是由上一层传递过来的,形状为100行4列的矩阵。
那两个隐藏层之间的参数个数为多少呢?我们还是举一个例子来说明下,看下z1的输出,如图所示:
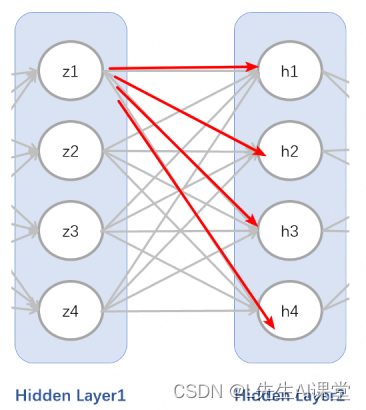
z1输出结构示意
可以发现,对于z1来说,与下一层的每个节点h1到h4都相连,所以对应4个参数。而像z1这样的输出节点有z1到z4,总共4个。所以隐藏层1和隐藏层2之间对应的参数矩阵W2为W2=(4,4)的形状,即每个特征对应4个输出,总共4个特征输入。
同样这两层结构也需要满足线性组合的方式,所以X和W相乘后即为(100,4)*(4,4)=(100,4),即从隐藏层2输出时为100行4列的矩阵形式。相当于隐藏层又做了一次特征转换,转换为新的4个特征。然后再做一次非线性变换函数的激活例如Sigmod函数后传递给下一层。
最后再来看下隐藏层2和输出层之间的结构,如图所示:
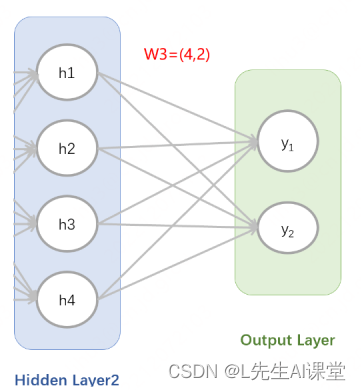
隐藏层2和输出层之间结构示意图
此时隐藏层2输出的形状为100行4列的矩阵 ,以h1为例,看下隐藏层2和输出层之间的参数矩阵W3。如图所示:
h1节点到下一层结构示意
可以发现h1分别连线到输出层节点的y1和y2上,对应2个参数。而类似h1这样的结构总共有4个,所以对应的参数矩阵为W3=(4,2)的形状。
然后再经过线性组合的原理XW+b=(100,4)*(4,2)+(100,2)=(100,2)。即100个样本,每个样本由两个预测输出。这也刚好符合我们的理解,对于二分类来说,每一个样本需要有各个类别的预测。
这里需要提醒一点的是在最后一个隐藏层和输出层之间,我们也要做一次非线性变化,只不过此时的非线性变换函数为SoftMax函数,区别于前面几层的Sigmod函数。这里之所以是SoftMax函数,是因为SoftMax函数可以将最后预测结果做概率化的输出,表示每个类别的概率。
四、结论
经过以上分析,我们对神经网络结构做下总结,可以得出以下几个结论。
1、隐层到隐层之间是非线性变换,对应Sigmod函数。隐层到输出之间是分类或者是回归变化,不做激活,因此需要SoftMax函数。
2、层与层之间的矩阵参数为上一层节点的个数和下一层节点个数之间所组成的矩阵。比如上面案例中输入层有3个节点,隐藏层1有4个节点,所以中间对应的参数矩阵形状为(3,4),即3行4列的形式。同理其它层之间也是如此。
所以掌握神经网络层与层之间的结构后,会有助于我们对神经网络的理解,从而更好的理解参数模型,找到算法合适的参数。