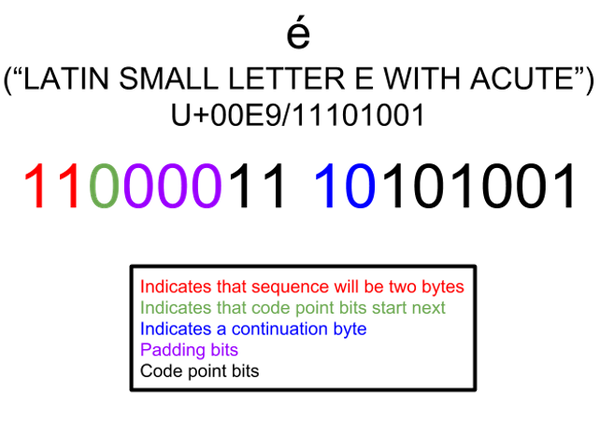1. 正文
1. set标签 和 foreach标签 trim标签 sql片段
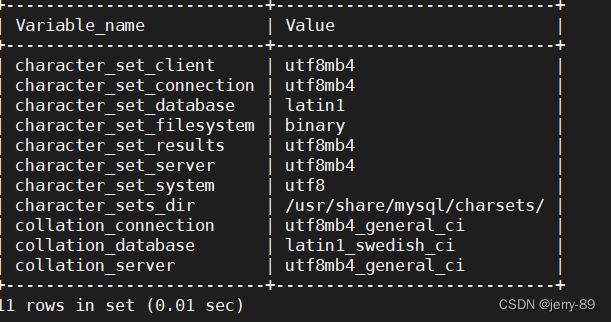
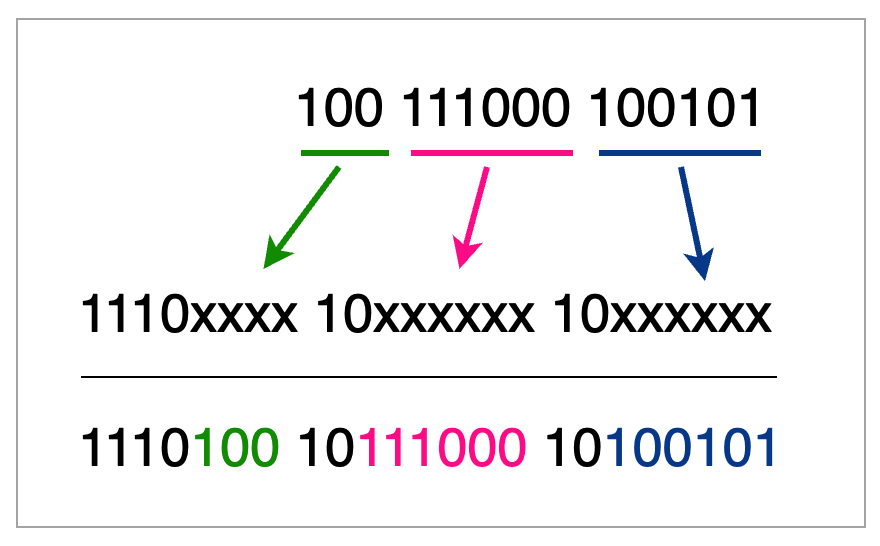
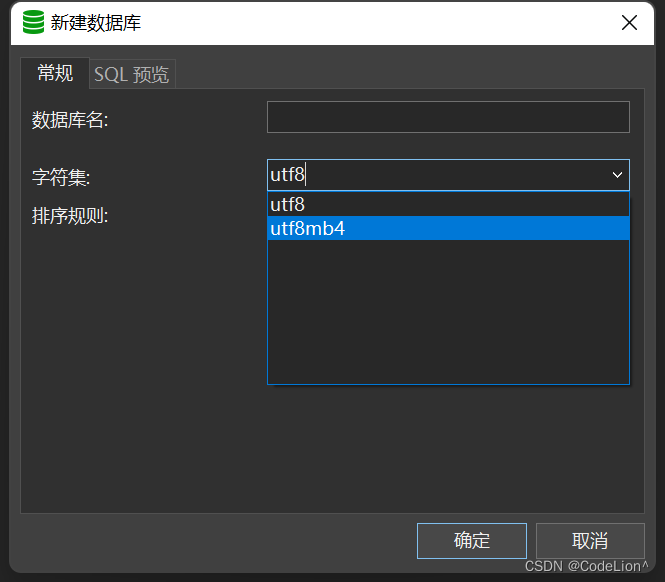
2. mybatis映射文件处理特殊字符.
3. mybatis完成模糊查询。
4. 联表查询
2. 动态sql
2.1 set标签
这个配合if标签一起用,一般用在修改语句。如果传递的参数值为null,那么应该不修改该列的值。
<!--set:可以帮我们生成关键字 set 并且可以去除最后一个逗号--><update id="update">update account<set><if test="name!=null and name!=''">name=#{name},</if><if test="money!=null">money=#{money},</if><if test="isdeleted!=null">isdeleted=#{isdeleted},</if><if test="created!=null">created=#{created},</if><if test="updated!=null">updated=#{updated},</if></set>where id=#{id}</update>2.2 foreach标签
循环标签.
查询:
<!-- select * from account where id in(2,3,5,7,0)如果你使用的为数组array 如果你使用的为集合 那么就用listcollection:类型item:数组中每个元素赋值的变量名open: 以谁开始close:以谁结束separator:分割符--><select id="findByIds" resultType="com.zjh.entity.Account">select * from account where id in<foreach collection="array" item="id" open="(" close=")" separator=",">#{id}</foreach></select>删除:
<delete id="batchDelete"><foreach collection="array" item="id" open="delete from account where id in(" close=")" separator=",">#{id}</foreach></delete>添加:
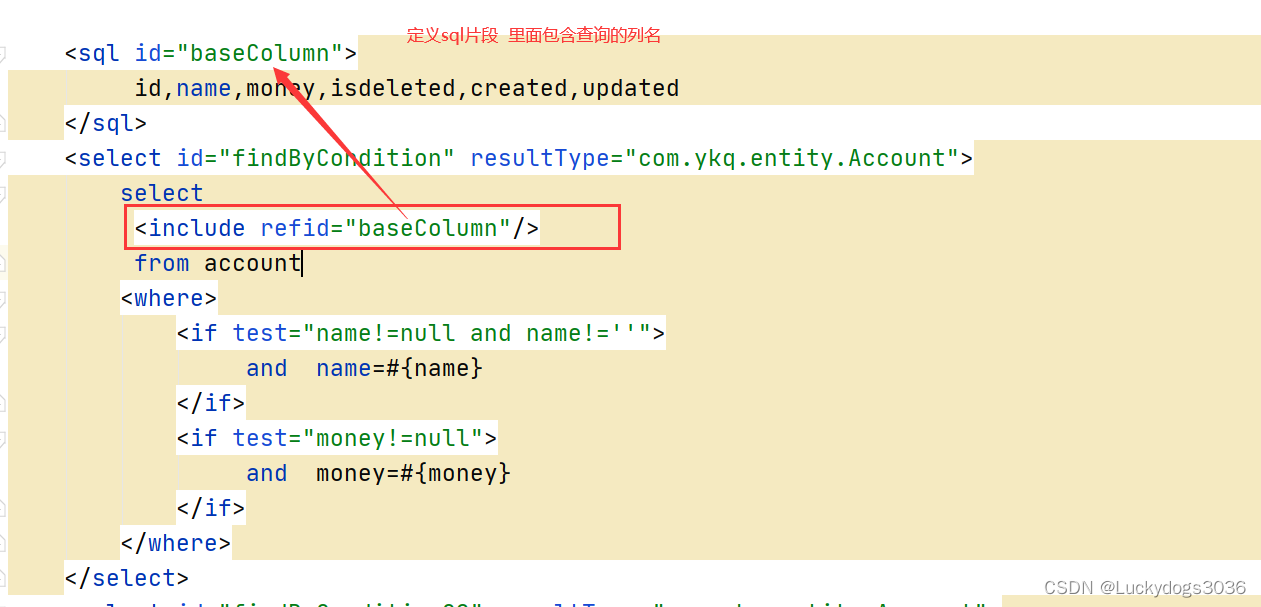
insert into account(name,isdeleted) values('ldh',0),('ldh2',0),('ldh4',0)<insert id="saveBatch">insert into account(name,isdeleted) values<foreach collection="list" item="acc" separator=",">(#{acc.name},#{acc.isdeleted})</foreach></insert>2.3 sql片段
在执行查询语句时不建议大家使用select *, 建议大家把查询的列写出。
3. mybatis映射文件处理特殊字符.
<!--第一种:转义标签 < 第二种: <![CDATA[sql]]>--><select id="findByMaxMin" resultType="com.zjh.entity.Account"><![CDATA[select * from account where id >#{min} and id <#{max}]]></select>4. mybatis完成模糊查询。
select * from 表名 where 列名 like '%a%'
(1)使用字符串函数 完成拼接 concat
<select id="findByLike" resultType="com.zjh.entity.Account">select * from account where name like concat('%',#{name},'%')
</select>(2) 使用${}
<select id="findByLike" resultType="com.zjh.entity.Account">select * from account where name like '%${name}%'
</select>通过观察: 发现使用${}实际上是字符串拼接,它不能防止sql注入, 而#{}它是预编译,它可以防止sql注入问题,#{}实际使用的PreparedStatement.
总结:
动态sql标签: if where (choose when otherwise) set foreach sql 处理特殊字符: <![CDATA[sql]]> 转义符 模糊查询: concat('',#{},'') ${}
5. 联表查询
-
多对一 : 从多的一方来查询一的一方。
班级表:
|1-n
学生表:
根据学生id查询学生信息并携带班级信息。
select * from tb_stu s join tb_class c on s.class_id=c.cid where stu_id=1
实体类:
package com.zjh.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/*** @author: jh* @create: 2022/6/2*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {private int id;private String name;private int age;private String sex;private Integer classId;
private Clazz clazz;//学生所属的班级
}
//如何把联表查询体现到实体类上。
package com.zjh.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/*** @author: jh* @create: 2022/6/2*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Clazz {private Integer cid;private String cname;
}xml:
<resultMap id="baseMap" type="com.zjh.entity.Student"><id column="stu_id" property="id"/><result column="stu_name" property="name"/><result column="stu_age" property="age"/><result column="sex" property="sex"/><result column="class_id" property="classId"/><!--association: 表示一的一方property: 它表示属性名javaType: 该属性名对应的数据类型--><association property="clazz" javaType="com.zjh.entity.Clazz"><id column="cid" property="cid"/><result column="cname" property="cname"/></association></resultMap><select id="findStudentById" resultMap="baseMap">select * from tb_stu s join tb_class c on s.class_id=c.cid where stu_id=#{id}</select>上面你要是绝的没有懂,那么这里可以使用的一个笨的方式: 但是不推荐。
返回类型就用map封装
//根据学生编号查询学员信息以及班级信息public Map findById(Integer id);<!--key:value--><select id="findById" resultType="java.util.Map">select <include refid="aa"/> from tb_stu s join tb_class c on s.class_id=c.id where s.id=#{id}</select>