主要内容
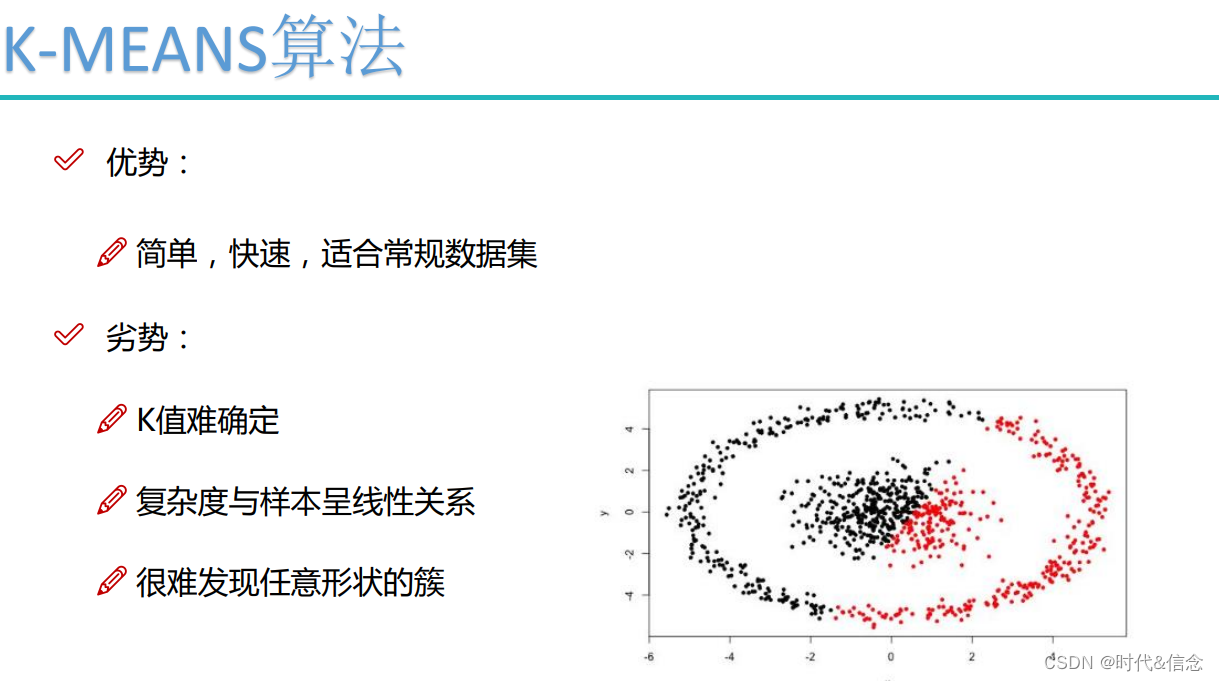
- K-均值算法的介绍
- K-均值算法的实现过程
- K-均值算法的具体例子实现过程
一、K-均值算法的介绍
-
K-均值(K- means) ** 是最普及的聚类算法**,算法接受一个未标记的数据集,然后将数据聚类成不同的组
-
聚类算法 是无监督学习中的典型算法,K-均值算法 又是聚类算法中的经典算法
-
K- means算法 要求预先设定聚类的个数,然后不断更新聚类中心,通过多次迭代最终使得所有数据点到其聚类中心距离的平方和趋于稳定
二、K-均值算法的实现过程
2.1 K-均值的具体过程
-
K-均值是一个迭代算法,假设我们想要将数据聚类成n个组,其方法为:
-
首先从n 个向量中随机选择 K K K个点,称为聚类中心(cluster centroids)

-
对于数据集中的每一个数据,按照距离 K K K个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类
-
计算每一个组的平均值,将该组所关联的聚类中心点移动到平均值的位置
-
重复步骤2-4直至中心点不再变化
- 某次迭代后只有不到1%的数据会出现类簇之间的归类变化,就可以认为聚类算法已经实现了

- 某次迭代后只有不到1%的数据会出现类簇之间的归类变化,就可以认为聚类算法已经实现了
-
2.2 K-均值算法的伪代码描述
- 用 μ 1 μ^1 μ1, μ 2 μ^2 μ2,…, μ k μ^k μk 来表示聚类中心,
- 用 c ( 1 ) c^{(1)} c(1), c ( 2 ) c^{(2)} c(2),…, c ( m ) c^{(m)} c(m)来存储与第 i i i个实例数据最近的聚类中心的索引
Repeat {for i = 1 to mc(i) := index (form 1 to K) of cluster centroid closest to x(i)for k = 1 to Kμk := average (mean) of points assigned to cluster k}
随机初始化N个聚类中心;
while(true)
{簇分配:计算所有点到这N个聚类中心的距离,从而把数据分为N个簇(隔得最近的一个簇);计算均值:对于每一个簇,计算各点到该簇聚类中心的距离,取平均值移动聚类中心:移动该聚类中心到平均值处;
}
- 算法分为两个步骤,
- 第一个for循环是赋值步骤,即:对于每一个样例 i i i,计算其应该属于的类
- 第二个for循环是聚类中心的移动,即:对于每一个类 K K K,重新计算该类的质心
三、K-均值算法的具体例子实现过程
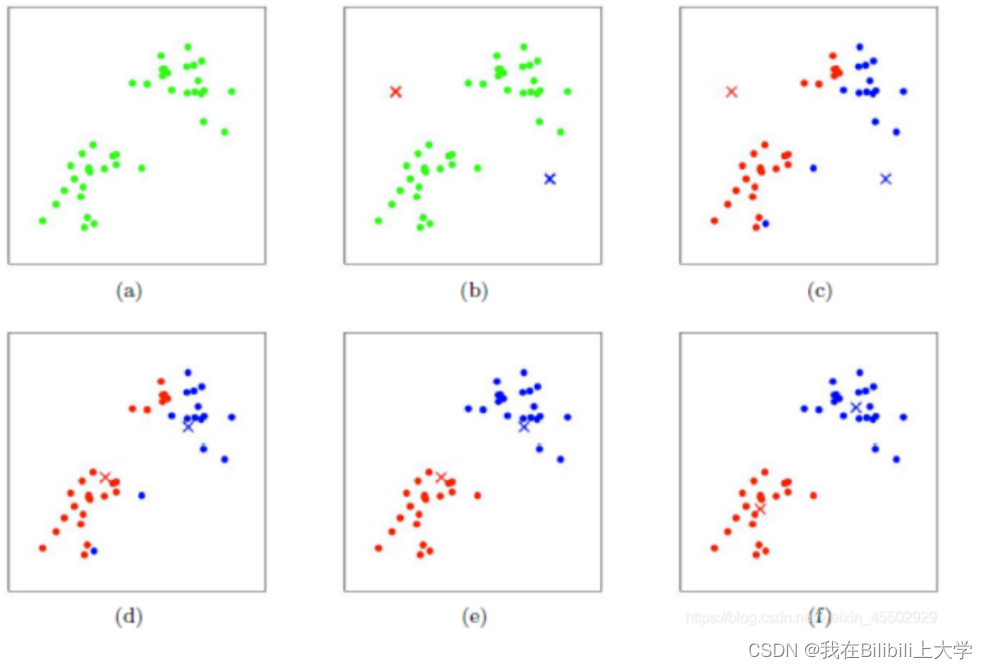
- 假设我们的数据如下图的小绿色的点,,现在要对其采用聚类算法——K-均值算法进行分类
-
首先初始化随机选取的中心点(如图中的红色X和黑色X)

-
分别计算每个样本数据点到红色红色X和黑色X的距离后分类,到谁的距离小就将其标记为哪一类(分为了红色和蓝色的点)

-
然后移动中心点——将得到的所有红色(蓝色)的样本点数据进行求平均值,得到的两个平均值即为新的中心点

-
重复迭代上述很多次之后,得到中心点不在变化,则得到最终聚类结果

-
注意:如果有一个聚类中心,它没有被分配到任何一个点:
- 一般情况移除这个聚类中心,但是聚类中心就会从K变为K-1;
- 如果想保持K个聚类,则在初始化这个点一次
-
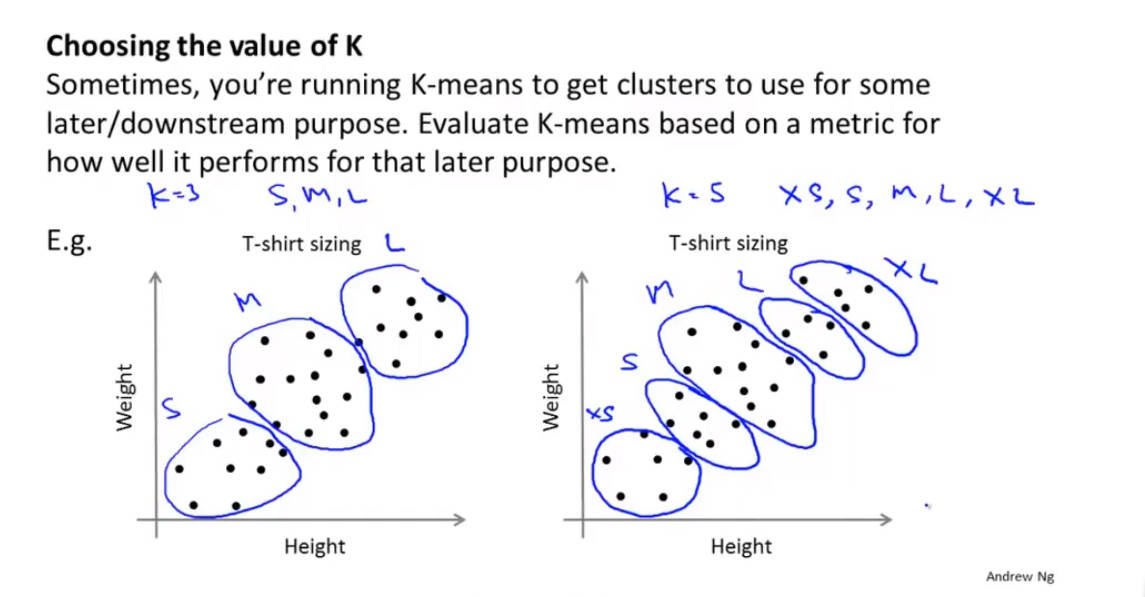
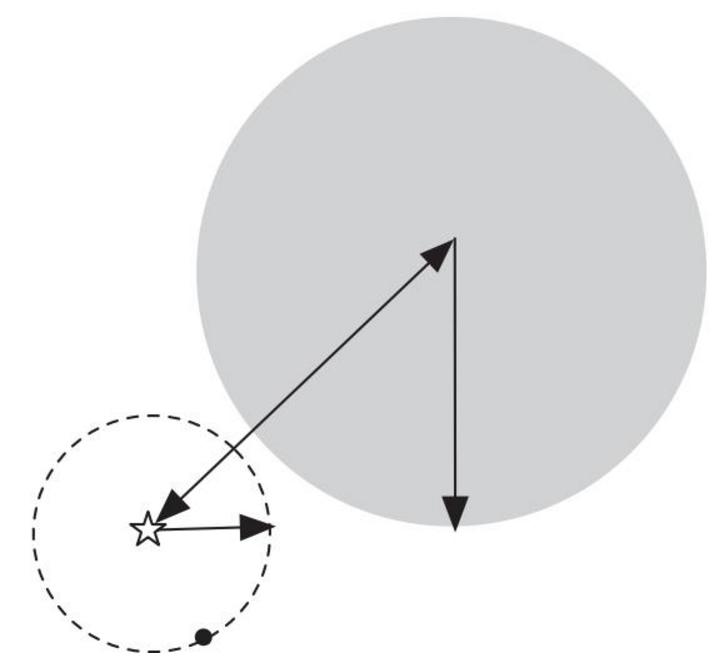
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在没有非常明显区分的组群的情况下也可以
- 下图所示的数据集包含身高和体重两项特征构成的,利用K-均值算法将数据分为三类,用于帮助确定将要生产的T-恤衫的三种尺寸