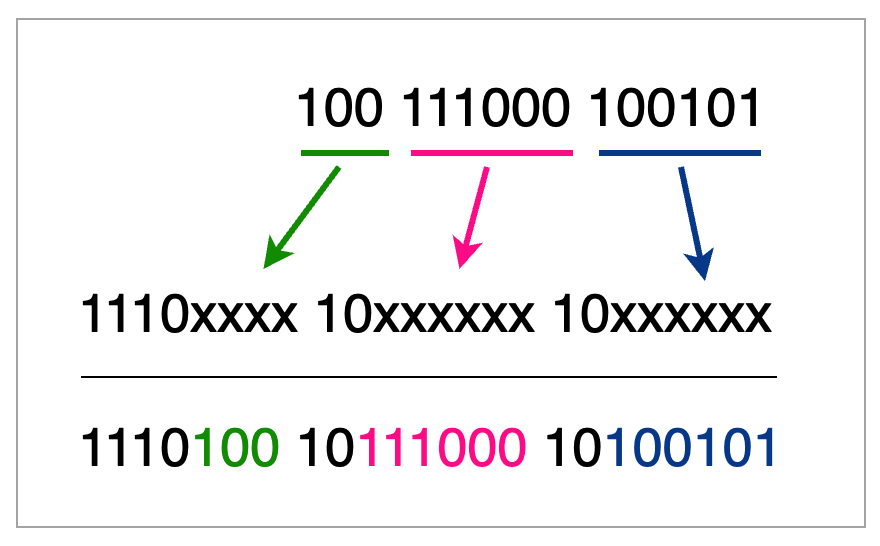
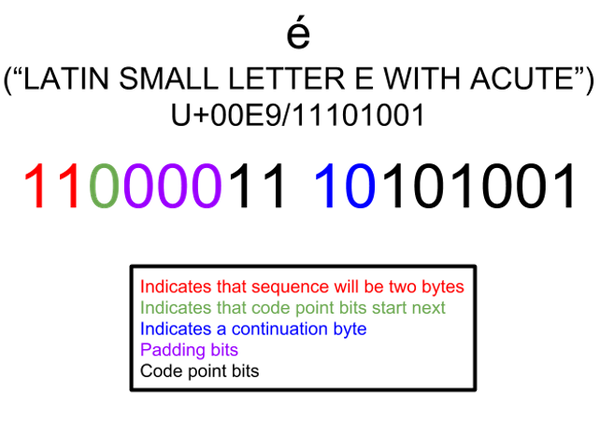utf-8编码可能2个字节、3个字节、4个字节的字符,但是MySQL的utf8编码只支持3字节的数据,而移动端的表情数据是4个字节的字符。如果直接往采用utf-8编码的数据库中插入表情数据,java程序中将报SQL异常:
java.sql.SQLException: Incorrect string value: ‘\xF0\x9F\x92\x94’ for column ‘name’ at row 1
utf8mb4编码是utf8编码的超集,兼容utf8,并且能存储4字节的表情字符。
采用utf8mb4编码的好处是:存储与获取数据的时候,不用再考虑表情字符的编码与解码问题。
1、查询当前数据库字符集
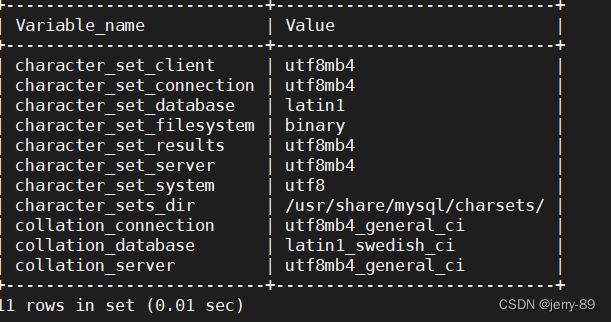
SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%';
2、设置mysql配置文件/etc/my.cnf
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_general_ci
init_connect='SET NAMES utf8mb4'
3、重启mysql服务
systemctl restart mysqld.service
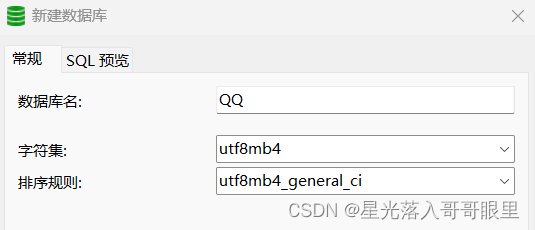
设置 MYSQL 数据库编码为 utf8mb4_mysql
MySQL 中字符集相关变量 character_set_client:客户端请求数据的字符集
character_set_connection:从客户端接收到数据,然后传输的字符集
character_set_database:默认数据库的字符集,无论默认数据库如何改变,都是这个字符集;如果没有默认数据库,那就使用 character_set_server指定的字符集,这个变量建议由系统自己管理,不要人为定义。
character_set_filesystem:把操作系统上的文件名转化成此字符集,即把 character_set_client转换character_set_filesystem, 默认binary是不做任何转换的
character_set_results:结果集的字符集
character_set_server:数据库服务器的默认字符集
character_set_system:存储系统元数据的字符集,总是 utf8,不需要设置
4、数据库链接参数
characterEncoding=utf8mb4&autoReconnect=true
5、如果已经有数据库和表,可以修改字符集:
更改数据库编码:
ALTER DATABASE DATABASE_NAME CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
更改表编码:
ALTER TABLE TABLE_NAME CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
-----------------------------------
设置 MYSQL 数据库编码为 utf8mb4
数据库编码 问题
mysql 修改字符集为utf8mb4
问题 ;
当向数据库插入表,或者在表中插入数据时,出现
ERROR 1366 (HY000): Incorrect string value: ‘\xBD\xF0\xD3\xB9’ for
column ‘name’ at row 1
原因 数据库编码方式 和 表编码方式 以及 插入数据(字符串)的编码方式不同
我们可以查看建表,建数据库语句,查看他们的编码
show create database database_name
show create table table_name
也可以使用 show full columns from emp 查看表的最详尽信息
在windows下mysql建表是默认是采用latin字符集
错误解决方式
将数据库和表的编码换成 utf8mb4 插入表的语句在记事本里另存为 utf8 编码
修改database默认的字符集
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE =
utf8mb4_unicode_ci
虽然修改了database的字符集为utf8mb4,但是实际只是修改了database新创建的表,默认使用utf8mb4,原来已经存在的表,字符集并没有跟着改变,需要手动为每张表设置字符集
修改table的字符集
只修改表默认的字符集
ALTER TABLE table_name DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
修改表默认的字符集和所有字符列的字符集
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
单独修改column默认的字符集 ALTER TABLE table_name CHANGE column_name column_name
VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
注意内容
检查字段的最大长度和索引列
字段长度
由于从utf8升级到了utf8mb4,一个字符所占用的空间也由3个字节增长到4个字节,但是我们当初创建表时,
设置的字段类型以及最大的长度没有改变。例如,你在utf8下设置某一字段的类型为TINYTEXT, 这中字段类型
最大可以容纳255字节,三个字节一个字符的情况下可以容纳85个字符,四个字节一个字符的情况下只能容纳63
个字符,如果原表中的这个字段的值有一个或多个超过了63个字符,那么转换成utf8mb4字符编码时将转换失
败,你必须先将TINYTEXT更改为TEXT等更高容量的类型之后才能继续转换字符编码
索引
在InnoDB引擎中,最大的索引长度为767字节,三个字节一个字符的情况下,索引列的字符长度最大可以达到
255,四个字节一个字符的情况下,索引的字符长度最大只能到191。如果你已经存在的表中的索引列的类型为
VARCHAR(255)那么转换utf8mb4时同样会转换失败。你需要先将VARCHAR(255)更改为VARCHAR(191)才能继续
转换字符编码
修改配置文件
SET NAMES utf8 COLLATE utf8_unicode_ci becomes SET NAMES utf8mb4
COLLATE utf8mb4_unicode_ci
vim /etc/my.cnf
对本地的mysql客户端的配置
[client] default-character-set = utf8mb4
对其他远程连接的mysql客户端的配置
[mysql] default-character-set = utf8mb4
本地mysql服务的配置
[mysqld] character-set-client-handshake = FALSE character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci
service mysqld restart
检查修改
mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%';
+--------------------------+--------------------+
| Variable_name | Value |
+--------------------------+--------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| collation_connection | utf8mb4_unicode_ci |
| collation_database | utf8mb4_unicode_ci |
| collation_server | utf8mb4_unicode_ci |
+--------------------------+--------------------+
10 rows in set (0.00 sec)
修复&优化所有数据表
mysqlcheck -u root -p --auto-repair --optimize --all-databases