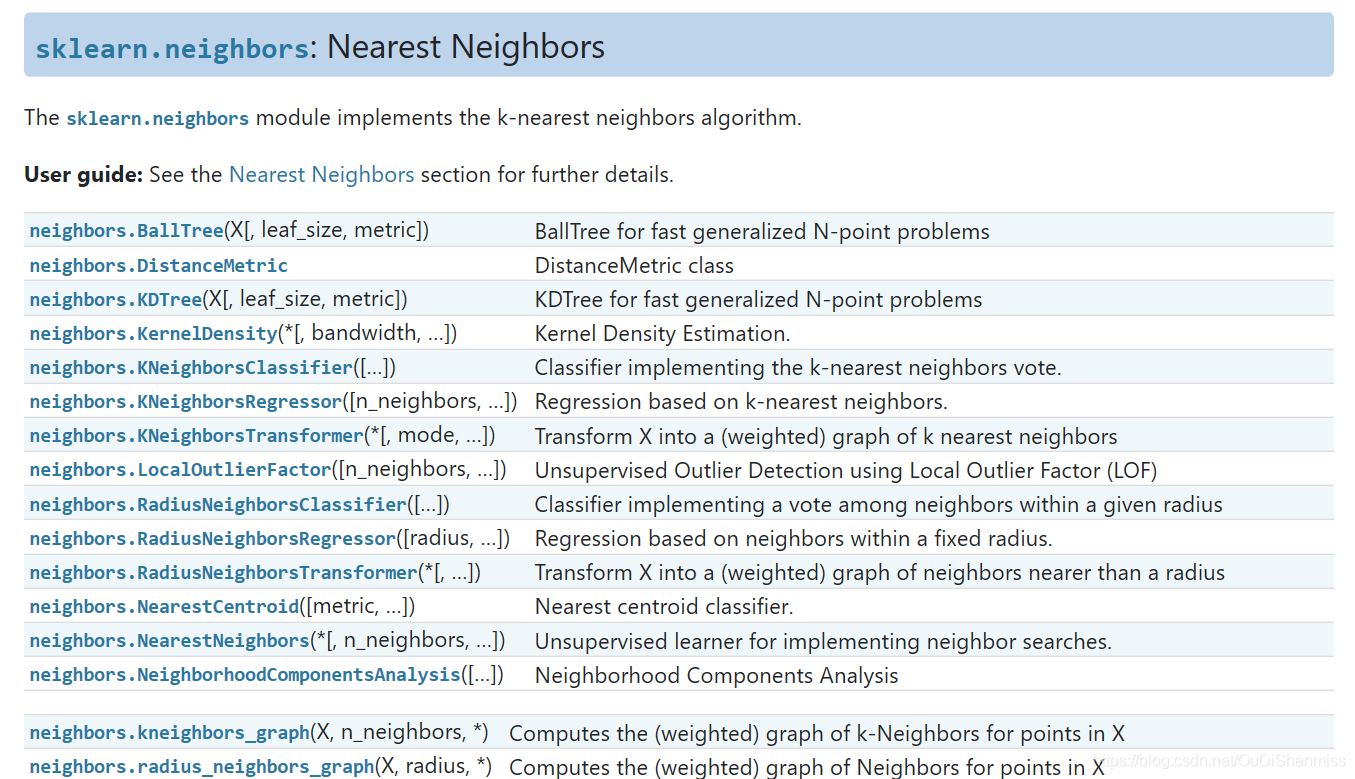
一、简介
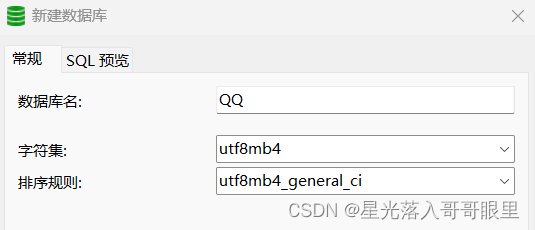
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。utf8mb4是utf8
的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。

二、内容描述
通常,计算机在存储字符时,会根据不同类型的字符以及编码方式分配存储空间。
例如以下几种编码方式;
①ASCII编码中,一个英文字母(不分大小写)占用一个字节的空间,一个中文汉字占用两个字节的空间。一个二进制的数字序列,在计算机中作为一个数字单元存储时,一般为8位二进制数,换算为十进制。最小值0,最大值255。
②UTF-8编码中,一个英文字符占用一个字节的存储空间,一个中文(含繁体)占用三个字节的存储空间。
③Unicode编码中,一个英文占用两个字节的存储空间,一个中文(含繁体)占用两个字节的存储空间。
④UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要占用2个字节的存储空间(Unicode扩展区的一些汉字存储需要4个字节)。
⑤UTF-32编码中,世界上任何字符的存储都需要占用4个字节的存储空间。
既然utf8能兼容绝大部分的字符,为什么要扩展utf8mb4?
随着互联网的发展,产生了许多新类型的字符,也就是我们通常在聊天时发的小黄脸表情(四个字节存储),所以,设计数据库时如果想要允许用户使用特殊符号,最好使用utf8mb4编码来存储,使得数据库有更好的兼容性,但是这样设计会导致耗费更多的存储空间。