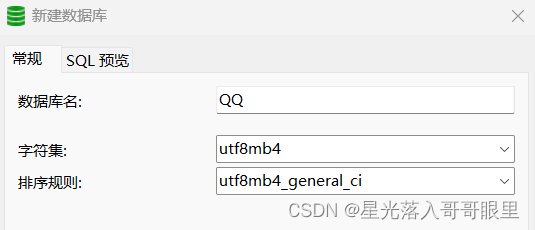
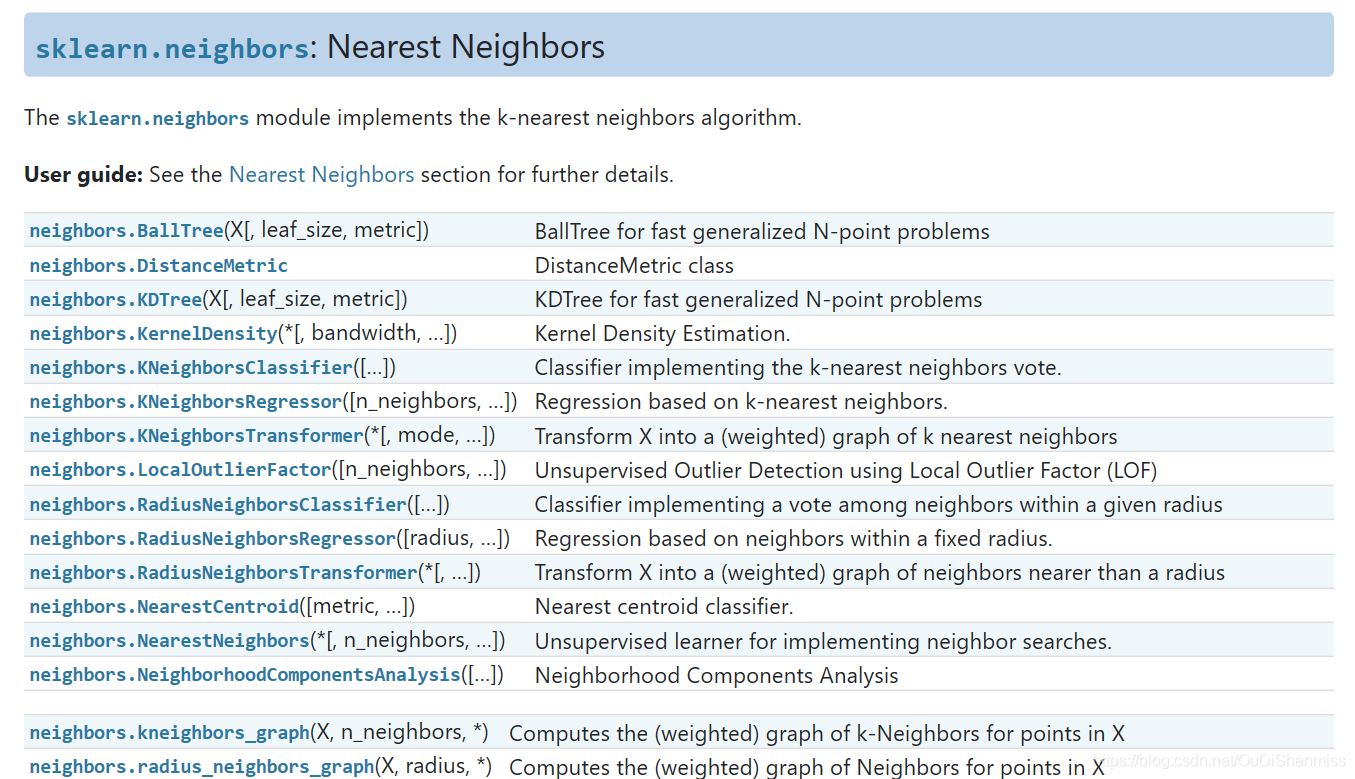
MySQL 的 utf8 实际上不是真正的 UTF-8。utf8 只支持每个字符最多三个字节,而真正的 UTF-8 是每个字符最多四个字节。
MySQL 一直没有修复这个 bug,他们在 2010 年发布了一个叫作 utf8mb4 的字符集,
绕过了这个问题。当然,他们并没有对新的字符集广而告之(可能是因为这个 bug 让
他们觉得很尴尬),以致于现在网络上仍然在建议开发者使用 utf8,但这些建议都是错误的。
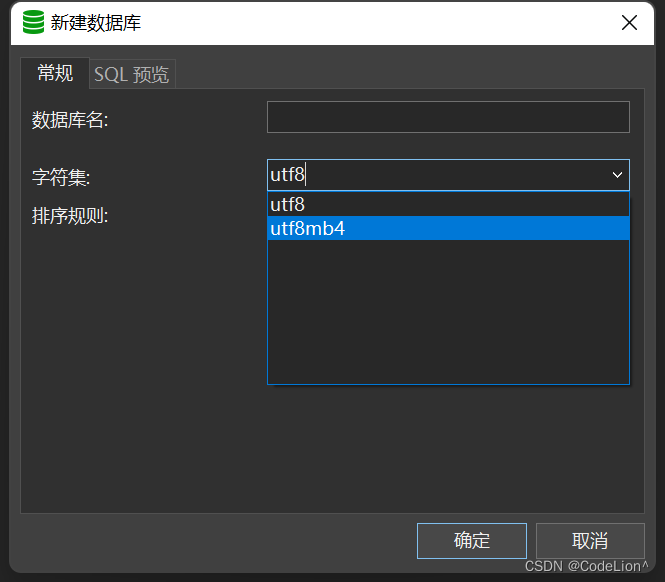
简单概括如下:
(1)MySQL 的 utf8mb4 是真正的 UTF-8。
(2)MySQL 的 utf8 是一种专属的编码,它能够编码的 Unicode 字符并不多。
所有在使用 utf8 的 MySQL 和 MariaDB 用户都应该改用 utf8mb4,永远都不要再使用 utf8。