07.
SQL模糊查找
大家好,我是小C,上期给大家分享——通过查询条件实现数据过滤(完结篇)
本期分享内容:SQL模糊查找
本期小C邀请的是董旭阳老师(资深数据库架构师)为我们分享《SQL从入门到精通》专栏。
S Q L
使用SQL语句进行模糊查找
前两篇我们介绍了如何利用 WHERE 子句中的查询条件过滤数据,包括比较运算符、逻辑运算符以及空值判断等。同时,我们也提到了 LIKE 运算符可以用于字符串的模糊查找。本篇我们就来讨论一下 SQL 中的模糊匹配。
当需要查找的信息不太确定时,例如只记住了某个员工姓名的一部分,可以使用模糊查找的功能进行搜索。SQL 提供了两种模糊匹配的方法:LIKE 运算符和正则表达式函数。
LIKE 运算符
下面的语句查找姓名以“赵”开头的员工:
SELECT emp_id, emp_name, sexFROM employeeWHERE emp_name LIKE '赵%';
该语句使用了一个新的运算符:LIKE。LIKE 用于指定一个模式,并且返回匹配该模式的数据。该语句的结果如下:

LIKE 运算符支持两个通配符,用于指定模式:
%,百分号可以匹配零个或者多个任意字符。
_,下划线可以匹配一个任意字符。
以下是一些模式和匹配的字符串:
LIKE 'en%',匹配以“en”开始的字符串,例如“english languages”、“end”;LIKE '%en%',匹配包含“en”的字符串,例如“length”、“when are you”;LIKE '%en',匹配以“en”结束的字符串,例如“ten”、“when”;LIKE 'Be_',匹配以“Be”开始,再加上一个任意字符的字符串。例如“Bed”、“Bet”;LIKE '_e%',匹配一个任意字符加上“e”开始的字符串,例如“her”、“year”。
当我们不确定员工邮箱中某个字符的时候,例如“dengzh*@shuguo.com”(其中星号的内容不确定),可以通过模糊匹配进行查找:
SELECT emp_name, emailFROM employeeWHERE email LIKE 'dengzh_@shuguo.com';emp_name|email |
--------|------------------|
邓芝 |dengzhi@shuguo.com|
模式中的下划线匹配了字符“i”。
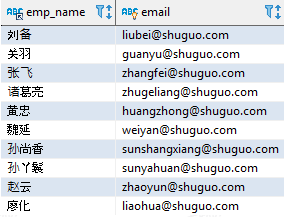
如果想要执行相反的操作,返回不匹配某个模式的数据,可以使用 NOT LIKE 运算符。以下查询将会返回除了“邓芝”之外的所有员工:
SELECT emp_name, emailFROM employeeWHERE email NOT LIKE 'dengzh_@shuguo.com';
该语句执行的结果如下(显示部分内容):
“%”和“_”是 LIKE 运算符中的通配符。如果需要查找的内容自身包含了“%”或者“_”时,例如想要知道哪些数据包含了“10%”(百分之十,而不是以 10 开始的字符串),应该如何指定模式呢?这种情况需要用到转义字符(escape character)。
转义字符
转义字符可以将通配符“%”和“_”进行转义,将它们当作普通字符使用。默认的转义字符为反斜杠(\)。因此,LIKE 运算符的完整语法如下:
expression LIKE pattern [ ESCAPE 'escape_character' ];
我们来看一个具体的示例就比较容易理解了。首先创建一个测试表:
CREATE TABLE t_like(c1 VARCHAR(20));
INSERT INTO t_like(c1) VALUES ('进度:25% 已完成');
INSERT INTO t_like(c1) VALUES ('日期:2019 年 5 月 25 日');
表 t_like 只有一个字段 c1,类型为字符串;表中包含两条记录。现在需要查找包含“25%”的数据,其中百分号是要查找的内容而不是任意多个字符。以下语句利用转义字符进行查找:
-- 查询包含字符串 25% 的数据
SELECT c1FROM t_likeWHERE c1 LIKE '%25\%%';
-- WHERE c1 LIKE '%25#%%' ESCAPE '#'; -- 指定 # 作为转义字符c1 |
----------|
进度:25% 已完成|
第一个 % 匹配多个任意字符;第二个 % 前面增加了转义字符(\),表示匹配一个百分号;第三个 % 匹配多个任意字符。查询结果中只有一条满足结果的数据,如果去掉转义字符(\)将会返回两条记录。另外,也可以通过 ESCAPE 指定其他的转义字符。
SQL Server 支持更多的通配符:’[ad]’ 匹配 ‘a’ 和 ‘d’;’[a-d]’ 匹配 ‘a’ 、‘b’、‘c’ 和 ‘d’;’[^ad]’ 匹配除了 ‘a’ 和 ‘d’ 之外的其他字符。
在使用 LIKE 查找数据时,还需要注意的一个问题就是大小写。
大小写匹配
对于汉字,不需要区分大小写;但是英文字母却有大小写之分,“A”和“a”是两个不同的字符。不过,4 种数据库对此采取了不同的处理方式:
Oracle 和 PostgreSQL 默认区分 LIKE 中的大小写,PostgreSQL 提供了不区分大小写的 ILIKE 运算符;
MySQL 和 SQL Server 默认不区分 LIKE 中的大小写。
我们使用大写字母查找员工的电子邮箱:
SELECT emp_name, emailFROM employeeWHERE email LIKE 'M%';emp_name|email |
--------|----------------|
马岱 |madai@shuguo.com|
糜竺 |mizhu@shuguo.com|
以上查询在 Oracle 和 PostgreSQL 中没有返回结果,在 MySQL 和 SQL Server 中返回 2 条结果。你用的是哪个数据库,有没有返回结果?
当我们需要匹配更复杂的模式时,例如判断用户输入的电子邮箱是否合法,无法通过 LIKE 运算符实现。这个时候,需要使用更加强大的正则表达式(Regular Expression)。
正则表达式
正则表达式用于检索或者替换符合某个模式(规则)的文本。很多的编程语言和编辑工具都提供了正则表达式搜索和替换,下图是文本编辑器 Notepad++ 提供的正则表达式查找功能。
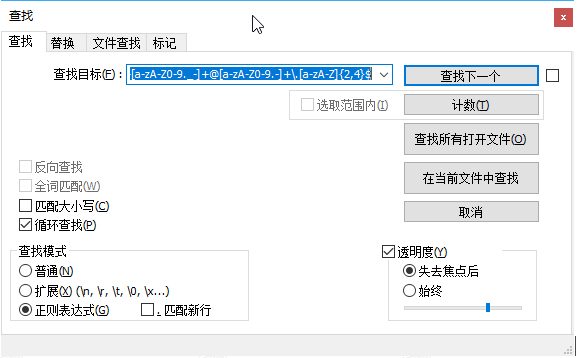
我们主要关注如何在 SQL 中使用正则表达式进行高级搜索,但不会介绍正则表达式的细节。如果想要学习正则表达式,可以参考 GitHub 上的正则表达式教程。
我们考虑一个 Web 开发中常见的问题:如何验证用户输入的邮箱地址是否合法?
首先,需要确认合法电子邮箱的规则。以下是一个简单的规则:
以字母或者数字开头;
后面是一个或者多个字母、数组或特殊字符( . _ - );
然后是一个 @ 字符;
之后包含一个或者多个字母、数组或特殊字符( . - );
最后是域名,即 . 以及 2 到 4 个字母。
以上规则使用正则表达式可以表示为:
^[a-zA-Z0-9]+[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}$
其中,^ 匹配字符串的开头;[a-zA-Z0-9] 匹配大小写字母或数字;+ 表示匹配前面的内容一次或多次;. 匹配任何一个字符,\. 匹配点号自身;{2,4} 匹配前面的内容 2 次到 4次;$ 匹配字符串的结束。
我们创建一个示例表并生成一些数据,然后查找表中的合法邮箱地址:
CREATE TABLE t_regexp (email VARCHAR(50)
);INSERT INTO t_regexp VALUES ('TEST@shuguo.com');
INSERT INTO t_regexp VALUES ('test@shuguo');
INSERT INTO t_regexp VALUES ('.123@shuguo.com');
INSERT INTO t_regexp VALUES ('test+email@shuguo.cn');
INSERT INTO t_regexp VALUES ('me.me@ shuguo.com');
INSERT INTO t_regexp VALUES ('123.test@shuguo-sanguo.org');
Oracle 和 MySQL 支持类似的正则表达式函数:
REGEXP_LIKE(source_str, pattern [, match_type])
其中,source_str 是被搜索的字符串;pattern 指定匹配的模式,使用正则表达式描述;match_type 指定可选的匹配方式,例如 i 表示不区分大小写,c 表示区分大小写。以下是用于查找合法邮箱地址的语句:
-- MySQL 实现
SELECT emailFROM t_regexpWHERE REGEXP_LIKE(email, '^[a-zA-Z0-9]+[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,4}$');email |
--------------------------|
TEST@shuguo.com |
123.test@shuguo-sanguo.org|-- Oracle 实现
SELECT emailFROM t_regexpWHERE REGEXP_LIKE(email, '^[a-zA-Z0-9]+[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}$');EMAIL |
--------------------------|
TEST@shuguo.com |
123.test@shuguo-sanguo.org|
以上查询返回了两个合法的邮箱地址。其中的区别在于,MySQL 中的转义字符需要使用两个反斜线(\)。
PostgreSQL 中提供了正则表达式匹配的运算符(~):
-- PostgreSQL 实现
SELECT emailFROM t_regexpWHERE email ~ '^[a-zA-Z0-9]+[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}$';email |
--------------------------|
TEST@shuguo.com |
123.test@shuguo-sanguo.org|
以上查询同样返回了两条合法的邮箱地址。另外,PostgreSQL 还支持以下运算符:
~* 匹配某个正则表达式,不区分大小写;
!~ 不匹配某个正则表达式,区分大小写;
!~* 不匹配某个正则表达式,不区分大小写。
SQL Server 中没有提供相关的正则表达式函数或者运算符。
小结
SQL 支持使用模式匹配对文本内容进行模糊查找,主要的方式有两种:LIKE 运算符和正则表达式函数或运算符。其中,LIKE 运算符通用性更好,但是需要注意区分大小写的问题;正则表达式函数功能更加强大,但是依赖于不同数据库的实现。
思考题:如果将本节中的邮箱验证模式改为 ^[a-z0-9]+[a-z0-9._-]+@[a-z0-9.-]+\.[a-z]{2,4}$,也就是去掉了正则表达式中的大写字母 A-Z,如何确保仍然能够匹配大写形式的邮箱地址?
今日内容有get吗,欢迎各位留言讨论!
以上,咱们《SQL从入门到精通》七天专栏打卡就结束了,如需了解更多,小伙伴们可识别下方二维码,订阅专栏,咱们下期专栏见!
了解更多详情
可识别下方二维码