CART决策树介绍
使用CART(Classification and regression tree)算法构建的决策树是二叉树,它对特征进行二分,迭代生成决策树。
CART回归树
假设X与Y分别为输入和输出变量,并且Y是连续变量,给定训练数据集
$$D=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}$$
考虑如何生成回归树。
一个回归树对应着输入空间(即特征空间)的一个划分以及在划分的单元上的输出值。假设已将输入空间划分为M个单元$R_1|R_2,...,R_M$,并且在每个单元$R_m$上有一个固定的输出值$c_m$,于是回归树模型可表示为
$$f(x)=\sum_{m=1}^Mc_mI(x\in R_m)\tag{1}$$
当输入空间的划分确定时,可以用平方误差$\sum_{x_i\in R_m}(y_i-f(x_i))^2$来表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上的最优输出值。易知,单元$R_m$上的$c_m$的最优值$\hat{c_m}$是$R_m$上的所有输入实例$x_i$对应的输出$y_i$的均值,即
$$\hat{c_m}=ave(y_i|x_i\in R_m)\tag{2}$$
这里选择第j个遍历$x^{j}$和它的取值s,作为切分遍历和切分点,并定义两个区域(左右结点)
$$\begin{cases} R_1(j,s)=\{x|x^{j}\leq s\}\\ R_2(j,s)=\{x|x^{j}> s\} \end{cases} \tag{3}$$
然后寻找最优切分变量j个最优切分点s。具体地,求解
$$min_{j,s}[min_{c_1}\sum_{x_i\in R_1(j,s)}(y_i-c_1)^2+min_{c_2}\sum_{x_i\in R_2(j,s)}(y_i-c_2)^2]\tag{4}$$
对固定输入变量j可以找到最优切分点s
$$\begin{cases}\hat{c_1}=ave(y_i|x_j\in R_1(j,s))\\ \hat{c_2}=ave(y_i|x_i\in R_2(j, s))\end{cases} \tag{5}$$
遍历所有输入变量,找到最优的切分变量j,构成一对(j,s)。以此将输入空间划分为两个区域。接着,对每个区域重复上述划分过程,知道满足停止条件为止(可以是满足叶子结点个数或误差阈值等条件)。这样就生成一颗回归树。这样的树通常称为最小二乘回归树。
具体过程如下
输入:训练数据集D(N,J)
输出:回归树f(x)
选择最优切分变量(特征)和切分点遍历所有特征。对该特征,按照式(3)依次计算第j个特征下的每个取值对应的平方误差。选择最小的特征和特征切分点对。
使用上一步得到的最佳的特征和特征切分对数据集D进行切分,得到左子树(满足条件进入)和右子树(不满足条件进入)。
继续执行步骤1和2(生成子树),直至满足停止条件。
得到回归树。
这里举一个简单的例子,介绍一下连续变量如何切分(和C4.5的处理方式是一样的)。
下表是一个数据集,包含了一个特征x,x为连续变量。y为类别标签。现在利用这个数据集来构建一个CART回归树。
x
1
2
3
4
5
6
7
8
9
y
0.3
0.5
0.7
0.8
0.95
1.3
1.5
1.6
1.9
首先需要选择特征和特征切分点
特征x包含了9个元素,长度为9,这里x已经排序好了,直接以$\frac{x_i+x_{i+1}}{2},i\in \{1,2,..., 9\}$作为切分点(一种常用的切分方式)。
从第一个切分点开始,第一个切分点为$\frac{1 + 2}{2}=1.5$。小于1.5则归到$R_1$(左子树),大于1.5则归为$R_2$(右子树)。
根据式(3)可得,$R_1=\{1\}$,$R_1=\{2,3,4,5,6,7,8,9\}$,根据式(5)可得,$c_1=0.3$,$c_2=\frac{0.5+0.7+0.8+0.95+1.3+1.5+1.6+1.9}{8}$,所以根据式(4),第一个切分点对应平方误差为$0+0.21=0.21$。按照这种方式依次计算每个切分点对应的误差,选择具有最小误差的切分点。
CART分类树
CART分类树使用最小基尼指数(Gini)准则来选择特征,同时决定最优切分点。
基尼指数的定义如下
$$G(p)=\sum_{k=1}^Kp_k(1-p_k)=1-\sum_{k=1}^Kp_k^2\tag{6}$$
对于指定的数据集D,其基尼系数为:
$$G(D)=\sum_{k=1}^K\frac{|C_k|}{|D|}(1-\frac{|C_k|}{|D|})\tag{6}$$
$|C_k|$表示第k类的样本数目。
设特征A的取值将数据集D分成两部分$D_1$和$D_2$。在特征A的条件下,数据集D的基尼系数定义为:
$$G(D,A)=\sum_{k=1}^K\frac{|D_1|}{|D|}G(D_1)+\sum_{k=1}^K\frac{|D_2|}{|D|}G(D_2)$$
G(D)表示数据集D的不确定性,基尼指数越大,不确定性越大。这点和熵比较相似。
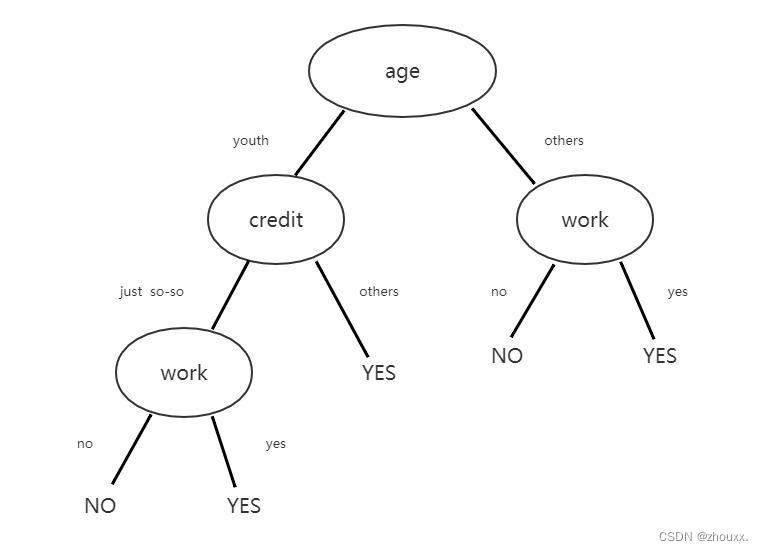
CART分类决策树和上一节中的ID3和C4.5构建决策树的差别不大,这里就不细说。下面直接给出CART分类树构建的代码。
代码实现
结点
class Node:
def __init__(self, val, tag=None):
"""
Params:
val: 特征名(内部节点)或类别标签(叶子节点)
tag: 切分点
left: 左子树
right: 左子树
"""
self.val = val
self.left = None
self.right = None
self.tag = tag
def __str__(self):
return f'val: {self.val}, tag: {self.tag}'
CART分类树
class CARTClassifier:
def __init__(self, thresh=1e-3, feat_names=None):
self.tree = None
self.feat_names = feat_names
self.thresh = thresh
def fit(self, x_train, y_train):
"""
构建决策树
"""
self.tree = self._build(x_train, y_train)
print('Finish train...')
def predict(self, x_test, y_test=None):
"""
预测
"""
if self.tree == None:
return
y_pred = []
for x in x_test:
y_pred.append(self._search(x))
y_pred = np.array(y_pred)
if y_test is not None:
self._score(y_test, y_pred)
return y_pred
def _search(self, x):
"""
根据特征取值进行搜索
"""
root = self.tree
tag = root.tag
while tag is not None:
idx = self.feat_names.index(root.val)
if isinstance(x[idx], str):
root = root.left if x[idx] == root.tag else root.right
else:
root = root.left if x[idx] < root.tag else root.right
tag = root.tag
return root.val
def _score(self, y_test, y_pred):
"""
计算预测得分(准确率)
"""
self.score = np.count_nonzero(y_test == y_pred) / len(y_test)
def _build(self, x, y):
"""
Params:
x(pandas.DataFrame): 特征features
y(pandas.DataFrame or numpy.array): 标签labels
"""
cks, cnts = np.unique(y, return_counts=True)
if len(cks) == 1:
return Node(cks[0])
if x.shape[0] == 0:
return None
self.feat_names = list(x.columns)
best_gini = float('inf')
best_split = None
best_feat = 0
# 特征选择
for i in range(x.shape[1]):
if x.iloc[:, i].dtypes != 'object':
gini, split = self.calc_cond_gini_continuous(x.iloc[:, i], y)
else:
gini, split = self.calc_cond_gini(x.iloc[:, i], y)
if gini < best_gini:
best_gini = gini
best_split = split
best_feat = i
if best_gini < self.thresh:
return Node(cks[cnts.argmax(0)])
tree = Node(self.feat_names[best_feat], best_split)
# 连续特征处理
if x.iloc[:, best_feat].dtypes != 'object':
fmask = x.iloc[:, best_feat] < best_split
bmask = x.iloc[:, best_feat] > best_split
# 离散特征处理
else:
fmask = x.iloc[:, best_feat] == best_split
bmask = x.iloc[:, best_feat] != best_split
tree.left = self._build(x[fmask], y[fmask])
tree.right = self._build(x[bmask], y[bmask])
return tree
# 计算基尼系数
def calc_gini(self, label):
gini = 0
for (ck, cnt) in zip(*np.unique(label, return_counts=True)):
prob_ck = cnt / len(label)
gini += prob_ck * (1 - prob_ck)
return gini
# 处理离散特征
def calc_cond_gini(self, feat, label):
cks = np.unique(feat)
best_gini = float('inf')
best_split = 0
for ck in cks:
fmask = feat == ck
bmask = feat != ck
cond_gini = sum(fmask) * self.calc_gini(label[fmask])/ len(label) + sum(bmask) * self.calc_gini(label[bmask])/ len(label)
if cond_gini < best_gini:
best_gini = cond_gini
best_split = ck
return best_gini, best_split
# 处理连续特征
def calc_cond_gini_continuous(self, feat, label):
# 对特征进行升序排序
sorted_feat = np.sort(feat, axis=0)
sorted_feat = np.unique(sorted_feat)
# 确定可能的划分点
split_pos = (sorted_feat[:-1] + sorted_feat[1:]) / 2
best_gini = float('inf')
best_split = 0
for pos in split_pos:
lmask = feat < pos
rmask = feat > pos
cond_gini = sum(lmask) * self.calc_gini(label[lmask])/ len(label) + sum(rmask) * self.calc_gini(label[rmask])/ len(label)
if cond_gini < best_gini:
best_gini = cond_gini
best_split = pos
return best_gini, best_split
def pruning(self, tree, x_test, y_test):
"""
后剪枝
根据测试集, 对创建好的决策树进行剪枝
"""
# TODO
pass
def preorder(self):
"""
决策树前序遍历
"""
print('--- PreOrder ---')
tree = self.tree
self._preorder(tree)
def _preorder(self, tree):
if tree == None:
return
print(tree)
self._preorder(tree.left)
self._preorder(tree.right)
构建CART决策树并执行分类,这里还是以Iris数据集为例
# 读取数据
data = load_iris()
x, y = data['data'], data['target']
# 分割成训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=20190320, test_size=0.1)
x_train = pd.DataFrame(x_train, columns=data.feature_names, index=None)
# 构建决策树
tree = CARTClassifier()
tree.fit(x_train, y_train)
# CART决策树前序遍历
tree.preorder()
# 执行预测
y_pred = tree.predict(x_test, y_test)
print(tree.score)
代码实现结果

总结
本节主要介绍了CART回归树和分类树的构建过程,决策树的剪枝之后再讨论吧,就这样吧。
Reference
李航《统计学习方法》