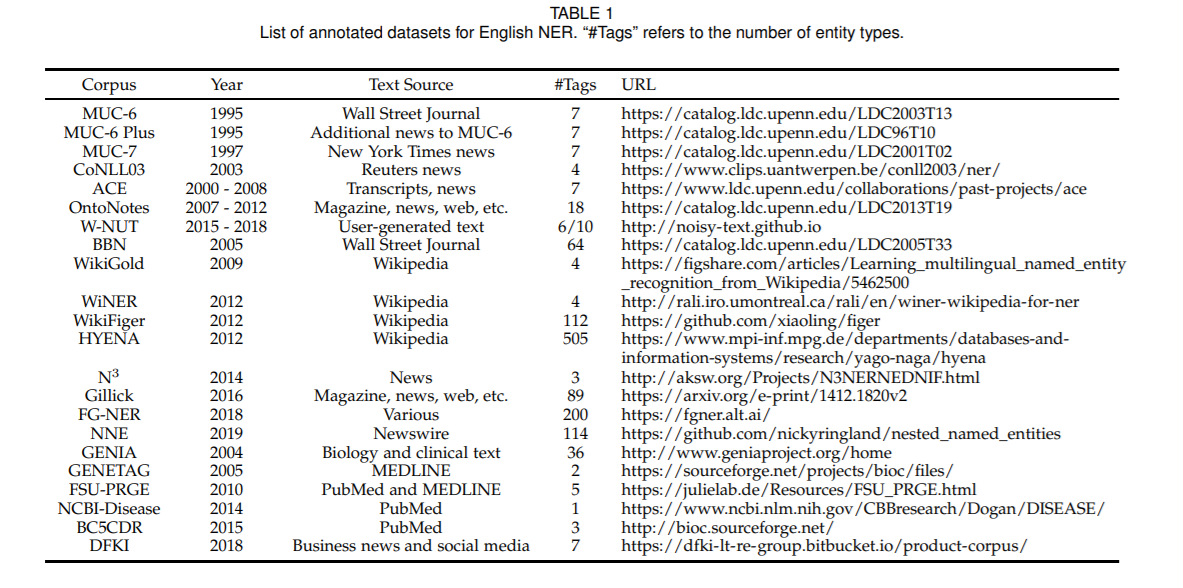
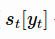在MUC-6中首次使用了命名实体(named entity)这一术语,由于当时关注的焦点是信息抽取(information extraction)问题,即从报章等非结构化文本中抽取关于公司活动和国防相关活动的结构化信息,而人名、地名、组织机构名、时间和数字表达(包括时间、日期、货币量和百分数等)是结构化信息的关键内容。
命名实体识别(Named EntitiesRecognition,NER),就是识别这些实体指称的边界和类别。主要关注人名、地名和组织机构名这三类专有名词的识别方法。
一、方法概述
和自然语言处理研究的其他任务一样,早期的命名实体识别方法大都是基于规则的。系统的实现代价较高,而且其可移植性受到一定的限制。
自20世纪90年代后期以来,尤其是进入21世纪以后,基于大规模语料库的统计方法逐渐成为自然语言处理的主流,一大批机器学习方法被成功地应用于自然语言处理的各个方面。根据使用的机器学习方法的不同,我们可以粗略地将基于机器学习的命名实体识别方法划分为如下四种:有监督的学习方法、半监督的学习方法、无监督的学习方法、混合方法。下表对这些方法进行了简要归纳。

二、命名实体识别方法
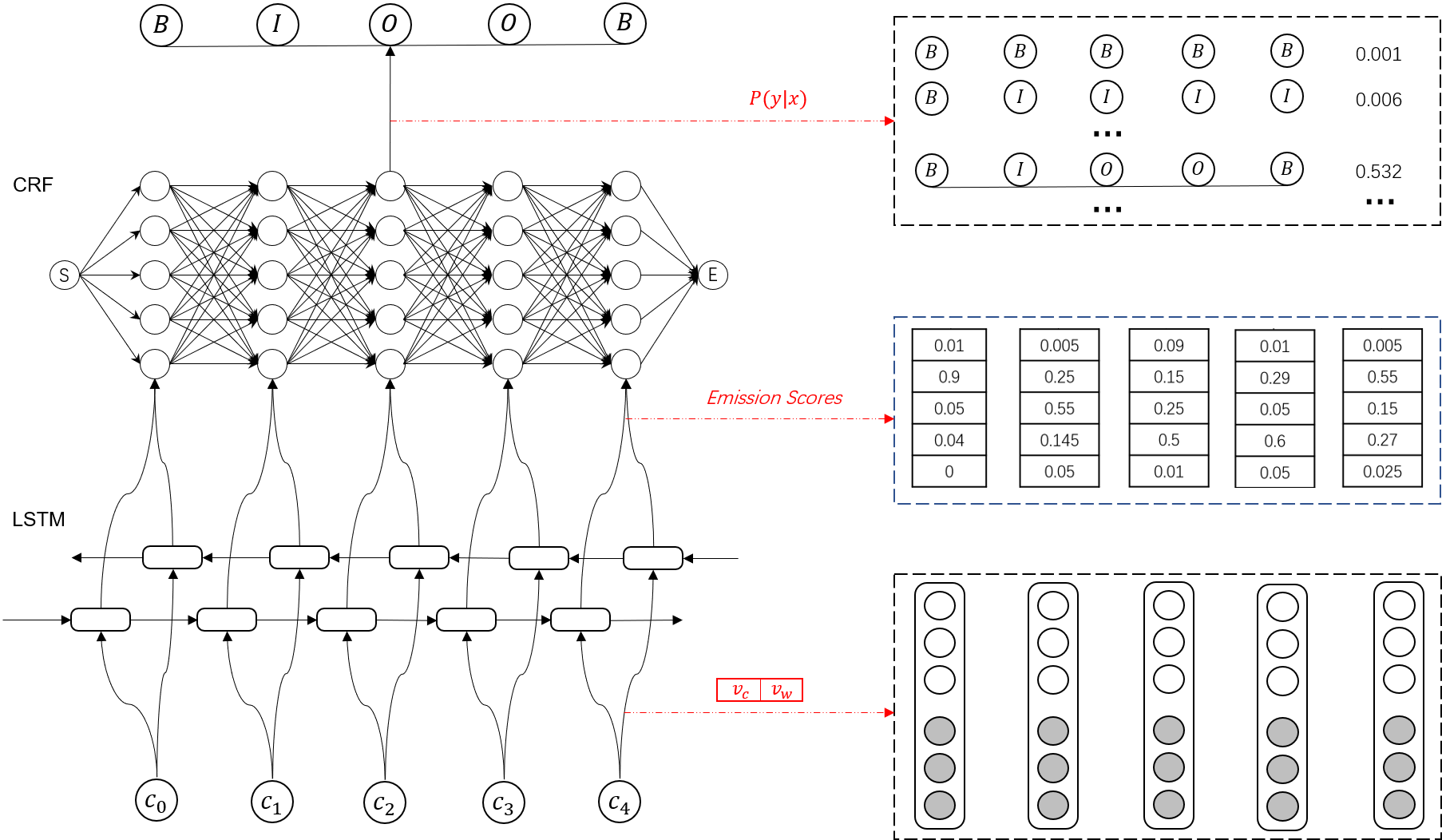
1.基于CRF的命名实体识别方法
McCallum等2003年最先将条件随机场(CRF)模型用于命名实体识别。由于该方法简便易行,而且可以获得较好的性能,因此受到业界青睐,已被广泛地应用于人名、地名和组织机构等各种类型命名实体的识别,并在具体应用中不断得到改进,可以说是命名实体识别中最成功的方法。
基于CRF的命名实体识别与前面介绍的基于字的汉语分词方法的原理一样,就是把命名实体识别过程看作一个序列标注问题。其基本思路是(以汉语为例):将给定的文本首先进行分词处理,然后对人名、简单地名和简单的组织机构名进行识别,最后识别复合地名和复合组织机构名。
所谓的简单地名是指地名中不嵌套包含其他地名,如地名:北京市、大不列颠、北爱尔兰、中关村等,而“北京市海淀区中关村东路95号”、“大不列颠及北爱尔兰联合王国”、“也门民主人民共和国”则为复合地名。同样,简单的组织机构名中也不嵌套包括其他组织机构名,如北京大学、卫生部、联合国等,而“欧洲中央银行”、“中华人民共和国卫生部”、“联合国世界粮食计划署”均为复合组织机构名。
基于CRF的命名实体识别方法属于有监督的学习方法,因此,需要利用已标注的大规模语料对CRF模型的参数进行训练。北京大学计算语言学研究所标注的现代汉语多级加工语料库被众多研究者用于汉语命名实体识别的模型训练。
在训练阶段,首先需要将分词语料的标记符号转化成用于命名实体序列标注的标记,如用PNB表示人名的起始用字,PNI表示名字的内部用字。类似地,用LOCB表示地名的起始用字,LOCI表示地名的内部用字;ORGB表示组织机构的起始用字,ORGI表示组织机构的内部用字。用OUT统一表示该字或词不属于某个实体。
接下来要做的事情是确定特征模板。特征模板一般采用当前位置的前后n(n≥1)个位置上的字(或词、字母、数字、标点等,不妨统称为“字串”)及其标记表示,即以当前位置的前后n个位置范围内的字串及其标记作为观察窗口:(…w-n/tag-n,…,w-1/tag-1w0/tag0,w1/tag1,…,wn/tagn,…)。考虑到,如果窗口开得较大时,算法的执行效率会太低,而且模板的通用性较差,但窗口太小时,所涵盖的信息量又太少,不足以确定当前位置上字串的标记,因此,一般情况下将n值取为2~3,即以当前位置上前后2~3个位置上的字串及其标记作为构成特征模型的符号。
由于不同的命名实体一般出现在不同的上下文语境中,因此,对于不同的命名实体识别一般采用不同的特征模板。例如,在识别汉语文本中的人名时,考虑到不同国家的人名构成特点有明显的不同,一般将人名划分为不同的类型:中国人名、日本人名、俄罗斯人名、欧美人名等。同时,考虑到出现在人名左右两边的字串对于确定人名的边界有一定的帮助作用,如某些称谓、某些动词和标点等,因此,某些总结出来的“指界词”(左指界词或右指界词)也可以作为特征。
特征函数确定以后,剩下的工作就是训练CRF模型参数λ。
大量的实验表明,在人名、地名、组织机构名三类实体中,组织机构名识别的性能最低。一般情况下,英语和汉语人名识别的F1值都可以达到90%左右,而组织机构名识别的F1值一般都在85%左右,这也反映出组织机构名是最难识别的一种命名实体。当然,对于不同领域和不同类型的文本,测试性能会有较大的差异。
2.基于多特征的命名实体识别方法
在命名实体识别中,无论采用哪一种方法,都是试图充分发现和利用实体所在的上下文特征和实体的内部特征,只不过特征的颗粒度有大(词性和角色级特征)有小(词形特征)的问题。考虑到大颗粒度特征和小颗粒度特征有互相补充的作用,应该兼顾使用的问题,提出了基于多特征相融合的汉语命名实体识别方法,该方法是在分词和词性标注的基础上进一步进行命名实体的识别,由词形上下文模型、词性上下文模型、词形实体模型和词性实体模型4个子模型组成的。其中,词形上下文模型估计在给定词形上下文语境中产生实体的概率;词性上下文模型估计在给定词性上下文语境中产生实体的概率;词形实体模型估计在给定实体类型的情况下词形串作为实体的概率;词性实体模型估计在给定实体类型的情况下词性串作为实体的概率。
1.模型描述
在基于多特征模型的命名实体识别系统中,词形包括以下几种情况:字典中任何一个字或词单独构成一类;人名(Per)、人名简称(Aper)、地名(Loc)、地名简称(Aloc)、机构名(Org)、时间词(Tim)和数量词(Num)各定义为一类。也就是说,词形语言模型中共定义了|V|+7个词形,其中,|V|表示词典的规模。由词形构成的序列称为词形序列WC。
词性采用北京大学计算语言学研究所开发的汉语文本词性标注标记集,另加上人名简称词性和地名简称词性,共47个词性标记。由词性标记构成的序列称为词性序列TC。
命名实体识别可以看作一个序列化数据的标注问题。输入是带有词性标记的词序列。
在分词和词性标注的基础上进行命名实体识别的过程就是对部分词语进行拆分、组合(确定实体边界)和重新分类(确定实体类别)的过程,最后输出一个最优的“词形/词性”序列WC*/TC*。
计算最优“词形/词性”序列WC*/TC*的方法有三种:词形特征模型、词性特征模型和混合模型。
(1)词形模型
词形特征模型根据词形序列W产生候选命名实体,用Viterbi确定最优词形序列WC*。目前的大部分系统都是从这个层面来设计命名实体识别算法的。
(2)词性模型
词性特征模型根据词性序列T产生候选命名实体,用Viterbi确定最优词性序列TC*。目前只有较少的系统使用。
(3)混合模型
词形和词性混合模型是根据词形序列W和词性序列T产生候选命名实体,一体化确定最优序列WC*/TC*,即本节将要介绍的基于多特征的识别算法。
词形和词性混合的汉语命名实体识别模型结合了词形特征模型和词性特征模型的优点,可以描述成下面式子的形式:
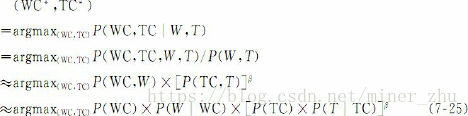
式子中的β是平衡因子,平衡词形特征和词性特征的权重,β>0。
模型(7-25)由四部分组成,分别称之为:词形上下文模型P(WC)、词性上下文模型P(TC)、实体词形模型P(W|WC)和实体词性模型P(T|TC)。实体词形模型和实体词性模型统称为实体模型。以下分别介绍这些模型。
2.词形和词性上下文模型
上下文模型估计在给定的上下文语境中产生实体的词形和词性概率。词形上下文模型和词性上下文模型均可采用三元语法模型近似描述:
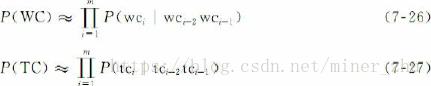
3.实体模型
考虑到每一类命名实体都具有不同的内部特征,因此,不能用一个统一的模型刻画人名、地名和机构名等实体模型。例如,人名识别可采用基于字的三元模型,地名和机构名识别可能更适合于采用基于词的三元模型等。此外,为提高外国人名的识别性能,吴友政又把外国人名进一步划分为日本人名、欧美人名和俄罗斯人名三个子类。因为这三类人名的内部特征(主要是人名用字集)存在较大的差别,日本人名用字相对较广,具有相对明显的姓氏特征,但姓氏集合却很大,而且日本人名姓氏很多和地名重叠。俄罗斯人名常用斯、基、娃等汉字,而欧美人名常用朗、鲁、伦、曼等汉字。为计算需要,按照字或词在命名实体内部的位置,吴友政把这些字或词划分成19个子类。
有了上述分类之后,人名、普通地名和机构名、单字地名和简称机构名分别建立相应的实体模型。
(1)人名实体模型
基于字的中国人名和外国人名的实体词形模型用下式描述:
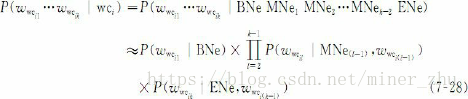
其中,wwcil(1≤l≤k)表示组成人名实体wci的单字。BNe,MNei(1≤i≤k-2)和ENe分别表示实体的首字、中间字和尾字,在具体计算人名时,分别将其替换成Sur、Dgb、Dge、EBfn、EMfn和EEfn等。
由于人名的词性实体模型的训练语料很难得到,因此,为了简化起见,使用词形实体模型替代词性实体模型,但乘以一个加权因子,如下式所示:
其中,γ为小于1的加权因子,在吴友政的实验系统中取经验值0.5。
(2)地名和机构名实体模型
对于地名和机构名,其实体模型要复杂得多,这是因为地名中除了普通词汇以外,还常嵌套人名和其他地名,如“茅盾故居纪念馆”,“北京市经济技术开发区”等;组织机构名中常嵌套人名、地名和其他机构名,如“富士通(中国)有限公司”,“宋庆龄基金会”等。
基于词的嵌套地名和机构名词形实体模型可以用下面的式子描述:
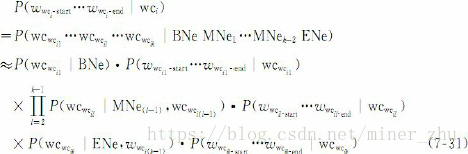
其中,wwci-start和wwci-end分别是实体wci被分词程序切分出的首词和尾词;wwcil- 和wwc 分别是wcwcil的首词和尾词,它们都是按照分词模start il-end块的词形定义切分出来的最基本的词形。wcwcil(1≤l≤k)是由原分词序列组合的可能的词,假设组合后含有k个词或子实体名,即长度为k,子实体可能是人名或地名。如果子实体是人名时,将被符号PER替换,如果子实体是地名时,将用标记Loc替换。BNe为实体wci被正确切分时的首词,根据表7-8记作Boo;MNe1…MNek-2为实体wci被正确切分时中间
部分的k-2个词,根据表7-8记作Moo;ENe为实体wci被正确切分时的末尾词,根据表7-8记作Eoo。
(3)单字地名实体模型
单字地名词形实体模型和词性实体模型均可采用最大似然估计方法计算,分别运用如下算式估计:

其中,C(wi,Aloc)和C(ti,Aloc)分别是语料中wi作为单字地名和其词性ti出现的次数。C(Aloc)为训练语料中单字地名出现的次数。
(4)简称机构名实体模型
简称机构名是对机构名全称的缩略叫法。机构名简称的出现形式大致可分为连续简写、不连续简写和混合简写三种方式。
包括机构名关键词的机构名简称(如福特公司,绿得公司,新唐公司)的识别同机构名全称的识别过程是一样的,但对于那些省略了机构名关键词的简称机构名的识别则是非常困难的问题。
经过分析我们发现,简称机构名在文本中的出现基本上有以下三种形式:
① 某些简称可以作为常用词收录进词典中,如中共、北约、欧盟等
② 有些简称机构名无法被收录进词典,但该简称的全称形式在文本中出现过,如华虹NEC(全称为“上海华虹NEC电子有限公司”,且在文中已经出现过)
③ 文本中直接出现省略了机构名关键词的简称机构名,如“百度”(省略了关键词“公司”)等。
对于上述形式③没有标志性关键词的情况,识别非常困难,我们暂不探讨。以下主要介绍形式①和②的处理方法。
形式①简称机构名的实体模型:简称机构名的词形和词性实体模型用最大似然估计方法计算
形式②简称机构名的词形实体模型:在真实文本中,简称可能出现在文本的前面,也可能出现在后面,为了完成这类简称机构名的识别,一般需要把命名实体识别分成两个阶段。第一阶段识别1类简称机构名和全称形式的机构名,并将其放入缓存器(cache)中,第二阶段利用第一阶段的识别结果进行简称识别。这样做一方面可以避免简称机构名的遗漏,并限制不必要的简称机构名的产生,另一方面可以方便、合理地计算简称机构名的产生概率,即简称的实体模型。
4.专家知识
在基于统计模型的命名实体识别中,最大的问题是数据稀疏严重,搜索空间太大,从而影响系统的性能和效率。因此,吴友政通过引入专家知识来限制候选实体的产生,从而达到了提高系统性能和效率的目的。这些专家知识主要包括如下几类:
1)人名识别的专家知识
这类专家知识包括:476个中国人名姓氏列表和9189个日本人名姓氏列表,用于限制中国人名和日本人名的候选词数;俄罗斯人名和欧美人名用字列表,用来限制俄罗斯人名和欧美人名的候选词数;另外,中国人名的长度最大为8个字符,外国人名则不受长度限制。
2)地名识别的专家知识
这里专家知识包括一个含607个地名关键词的列表、一个含407个单字地名的列表和一个介词、动词列表。如果当前词属于地名关键词,如“省、开发区、沙滩、瀑布”等,则触发地名识别。单字地名的候选由单字地名列表触发产生。如果前一个词包含在介词、动词列表中,如“去、到、在”等则触发地名识别。另外,地名最多包含12个汉语字符。
(3)机构名识别的专家知识
机构名识别专家知识包括一个含有3129个机构名关键词的列表,用于触发产生机构名候选,即如果当前词属于该列表,则机构名识别触发。另外,还包括一组机构名模板,用于识别统计模型遗漏的嵌套命名实体。
5.模型训练
根据前面的介绍,基于多特征的汉语命名实体识别模型式(7-25)由4个参数组成,在吴友政(2006)实现的系统中,这些参数使用最大似然估计从不同的训练语料中学习,其中,词性上下文模型P(TC)和词形上下文模型P(WC)是从1998年2月至1998年6月的《人民日报》标注语料中学习的;中国人名、外国人名、地名、机构名的实体词性模型和实体词形模型分别从156万、1.4万、4.4万和32万条的实体列表中训练得到的。
尽管使用了这样大规模的训练语料,数据稀疏问题还是非常严重。为此,吴友政采用了Back-off数据平滑方法,并引入逃逸概率计算权值,如下式所示:
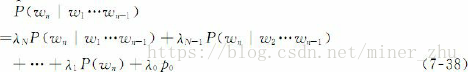
6.测试结果
系统性能表现主要通过准确率(precision,简记为P)、召回率(recall,简记为R)和F-测度值(F-measure,简记为F)3个指标来衡量,计算公式分别如式(7-40)、式(7-41)和式(7-42)所示:

根据模型计算式(7-25),平衡因子β是用于平衡词形特征和词性特征所发挥作用的权值,β值越大,词性特征的作用越强;否则,词形特征的作用就越强。根据吴友政(2006)的实验,β值从0到9.6变化时,系统对人名、地名和机构名称识别的准确率、召回率和F-测度值均有不同程度的上升和下降,当β值大于9.6时,人名、地名和机构名称识别的正确率、召回率和F-测度值均呈急剧下降趋势。经综合考察后,β=2.8时系统对人名、地名和机构名称识别的总体性能可达到最佳状态。
混合模型的人名、地名、机构名识别性能(F-测度值)比单独使用词形特征模型时的性能分别提高了约5.4%,1.4%,2.2%,比单独使用词性特征模型时分别提高了约0.4%,2.7%,11.1%。也就是说,结合词形和词性特征的命名实体识别模型优于使用单一特征的命名实体识别模型。
另外,实验还表明,结合了专家知识的统计模型对人名、地名和机构名的识别能力(F-测度值)与纯统计模型相比,分别提高了约14.8%,9.8%,13.8%,而且,系统的识别速度也有所提高。
上述结果表明,基于多特征模型的命名实体识别方法综合运用了词形特征和词性特征的作用,针对不同实体的结构特点,分别建立实体识别模型,并利用专家知识限制明显不合理的实体候选的产生,从而提高了识别性能和系统效率。