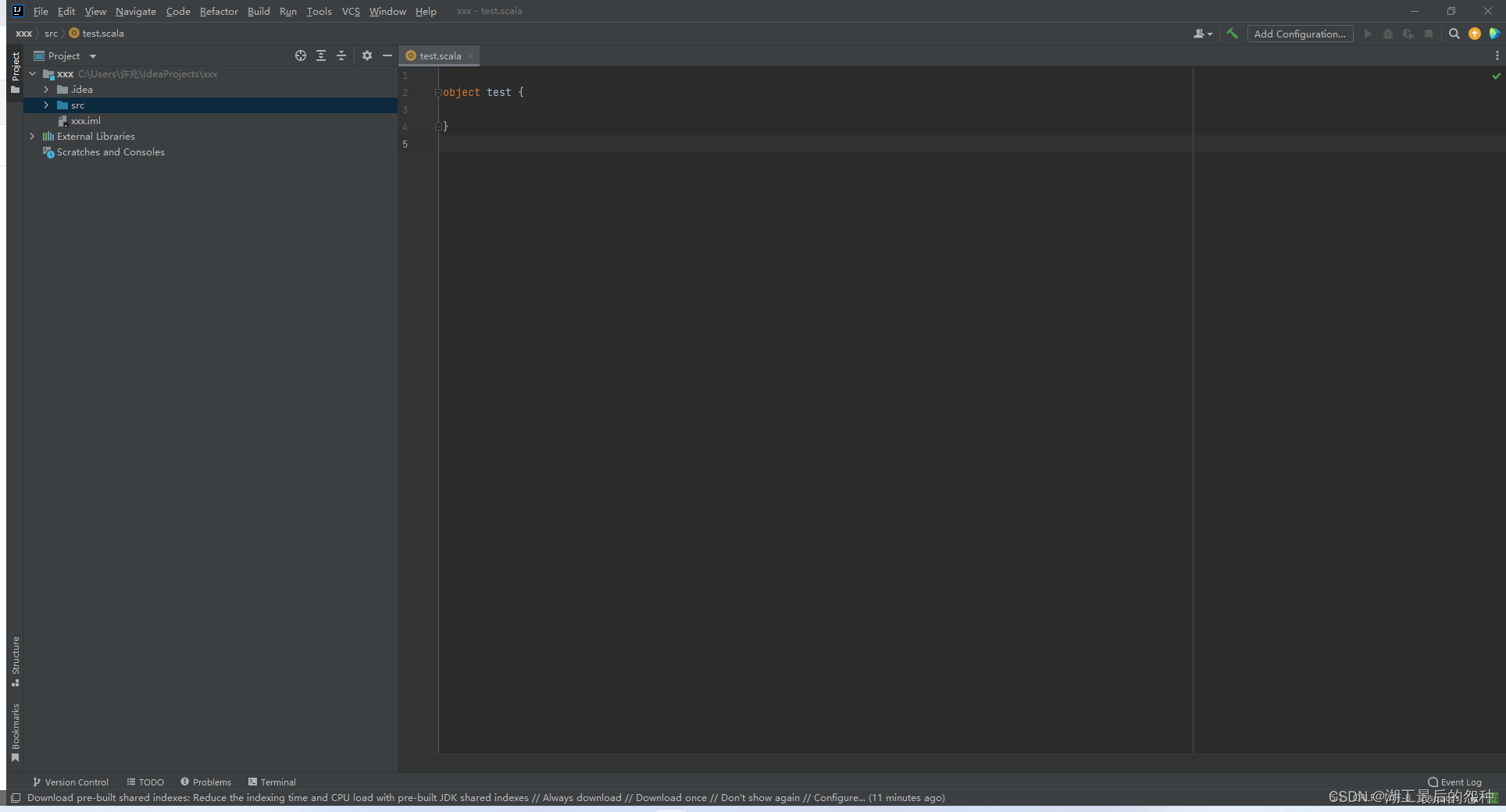
Spark 是一种基于内存快速、通用、可扩展的大数据分析计算引擎。
Spark 优势:
- Spark核心单元RDD适合并行计算和重复使用;
- RDD模型丰富,使用灵活;
- 多个任务之间基于内存相互通信(除了shuffle会把数据写入磁盘);
- Spark 启动响应Task速度快;
- Spark有高效的缓存机制。
SparkCore 架构及职责
Spark集群遵循标准的master-slave结构,主要架构包含Driver (master)、Executor(slave);
由于Spark具有资源调度分配能力,所有包含master和worker。
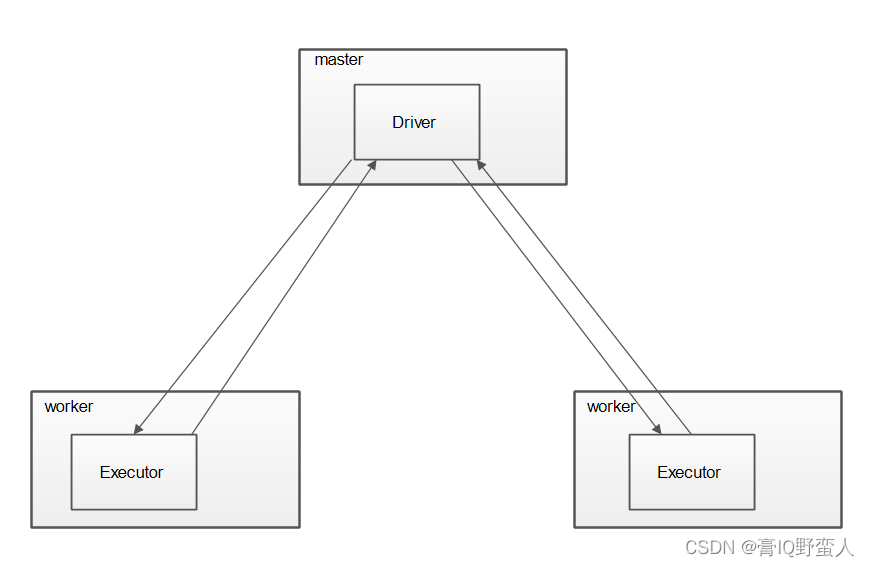
Driver:
- 驱动任务执行,协调代码的实际执行工作;
- 将上传的程序源码转化成作业(job);
- 在Executor之间进行任务调度;
- 监控跟踪Executor具体执行情况;
- 为UI界面提供api反馈job执行情况。
Executor:
Executor 是一个jvm进程,由spark启动而启动,伴随着spark整个生命周期;当某个Executor放生故障时,Driver会把该节点的任务调度到其他节点执行,不影响整个集群运行。
- 负责执行Driver调度的具体任务,并吧结果返回;
- 为RDD提供数据存储。
Master 和Worker:
Master协调资源管理,当集群资源不足时,Driver会向Master申请资源;
Worker为资源节点,当Master发送命令为集群开辟资源时,Worker调度自身资源提供给Driver。
SparkSQL组件
SparkSQL组件发展史:

hive是早起运行于Hadoop上的SQL-on-Hadoop工具,由于Hived是依赖于MapReduce,运算过程中产生大量的IO操作,运行效率低。
为了提高运行效率,产生大量SQL-on-Hadoop工具,其中知名度高的有Drill、Impala、Shark等,直到现在还有很多公司正在使用这些工具。其中Shark是伯克利实验室Spark生态基于Hive开发的组件,它主要是在Hive的基础上优化内存管理、物理计划、执行三个模块进行改进,使其运行在Spark引擎上,性能在Hive-on-MapReduce上提高了近百倍。
由于Shark对Hive的依赖程度高,Shark依然采用Hive的语法解析器,查询优化器,使得Spark生态组件开发很受限制。所以提出了SparkSQL项目,在数据兼容性、性能优化、组件扩展方面空前明朗。
2014年6月1日,Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目。数据兼容方面,在Shark的基础上,增加了RDD、Parquet文件、JSON文件中获取数据;性能方面,引进Cost Model对查询进行动态评估、获取最佳物理计划等。
形成Spark生态组件之一。
SparkSQL特点:
- 无缝整合SQL在Spark上编程;
- 统一了不同数据源访问方式;
- 兼容Hive,在已经存在的仓库中可直接运行HiveQL查询;
- BI工具通过标准的JDBC或ODBC查询大数据。
DataFrame、DataSet、RDD直接关系:
DataFrame 是一种以RDD为基础的分布式数据集,相当于关系型数据库中的数据表,带有元数据,每一列都带有列名和类型。这是RDD所没有的。同时DataFrame还支持struct、array、map等数据类型。所以DataFrame 比RDD更易用,提供的API更加灵活,Spark更加清楚数据结构以便于优化。DataFrame 与RDD一样,也是懒执行。
DataSet 分布式数据集是Spark1.6增加的一个新抽象,是DataFrame的一个扩展。增强了RDD的优势,使用lambda函数的能力。DataSet可以功能转换使用map、flatMap、filter算子。
DataSet是DataFrame API的一个扩展,是SparkSQL数据抽象;
具有友好的API风格,具有类型安全检查又有DataFrame的查询优化特性;
样例类中每个属性名称可直接对应DataSet中字段名称,是强类型;
DataFrame是DataSet的特例,DataFrame = DataSet[Row];
三者之间关系及转化:
- RDD、DataFrame、DataSet都是spark内部的分布式弹性数据集,为解决海量数据;
- 它们都是懒执行,创建、转换算子不会立刻执行,只有遇到Action算子才执行;
- 它们都有许多共同的函数;
- 它们都会根据Spark内存情况自动缓存及运算;
- 它们都有分区的概念;
- DataFrame和DataSet需要引进import spark.implicits._,能通过模式匹配字段的值和类型。
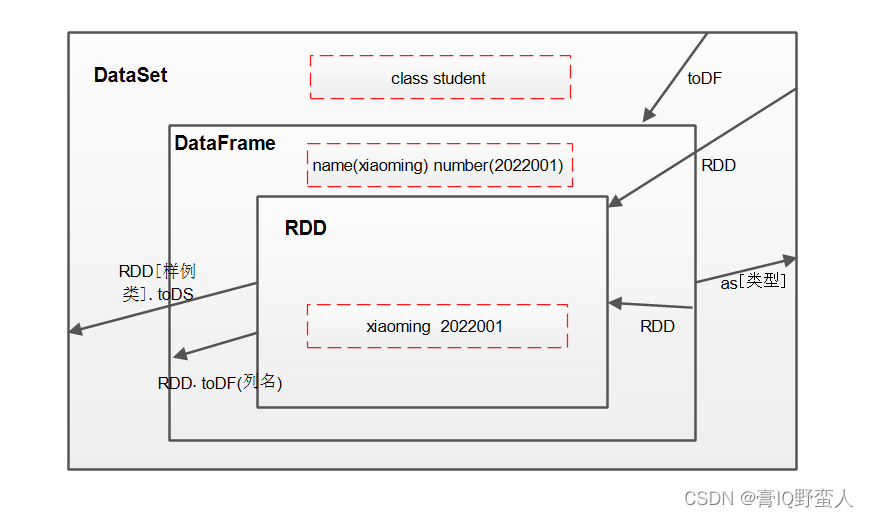
RDD:
-
RDD一般与SparkMllib同时使用,不支持SparkSQL;
DataFrame: -
DataFrame 每一行的类型固定为Row,每一列的值没发直接访问,只能通过解析才能获取字段值;
-
DataFrame、DataSet一般不予SparkMllib同时使用;都支持SparkSQL函数、临时表、视图等;都支持csv等直观的保存方式。
DataSet:
-
DataFrame是DataSet的一个特例等于DataSet[row],拥有相同的函数。