背景
微服务模式下,一次请求可能会经过多个服务。如果没有日志链将单次请求的日志串起来,定位问题时很容易陷入海量的日志中,无法快速定位问题。
sleuth是spring cloud中日志链(调用链解决方案),引入该依赖后,日志中会自动添加(traceid,spanid)。当获取到traceid后,可以在kibana或者其他日志收集系统中,精确定位到本次的所有日志。
sleuth基本原理很简单,就是在入口生成(traceid,spanid),并在调用中将traceid传递下去。
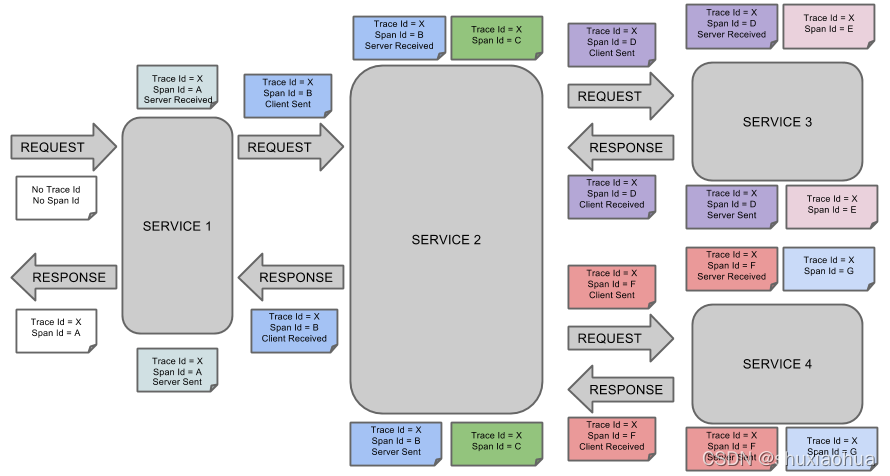
备注:上图来自spring官方文档。
但是在基本原理之上,sleuth如何做到无侵入性,个人总结有如下3点:
- 在入口生成(traceid,spanid),对系统又没有侵入性,应该是自动配置了一个filter,这个filter去检查请求头中是否有(traceid,spanid),如果没有的话,则认为此处是请求的入口,需要生成(traceid,spanid);如果有的话,则认为本处是调用链的一环,需要复用传入的traceid,并将其传入到下一环节中;
- 未做任何配置,日志模板是怎么如何添加(traceid,spanid)的占位符。
- 日志打印时如何获取(traceid,spanid)
traceid,spanid的自动生成
sleuth对系统没有侵入性,而且要保障业务处理逻辑的日志中,写入traceid,spanid。sleuth应该自动配置了一个filter去生成(traceid,spanid),而且该filter优先级最高。
根据该推测,在业务代码中随便打一个断点,然后查看堆栈中的第一个filter。

brave.servlet.TracingFilter#doFilter
HttpServletRequest req = (HttpServletRequest) request;HttpServletResponse res = servlet.httpServletResponse(response);// Prevent duplicate spans for the same requestTraceContext context = (TraceContext) request.getAttribute(TraceContext.class.getName());if (context != null) {// A forwarded request might end up on another thread, so make sure it is scopedScope scope = currentTraceContext.maybeScope(context);try {chain.doFilter(request, response);} finally {scope.close();}return;}# 调用链入口还没有生成traceid,因此走这个分支去生成Span span = handler.handleReceive(new HttpServletRequestWrapper(req));// Add attributes for explicit access to customization or span contextrequest.setAttribute(SpanCustomizer.class.getName(), span.customizer());request.setAttribute(TraceContext.class.getName(), span.context());SendHandled sendHandled = new SendHandled();request.setAttribute(SendHandled.class.getName(), sendHandled);Throwable error = null;Scope scope = currentTraceContext.newScope(span.context());......
未做任何配置,日志模板是怎么如何添加(traceid,spanid)的占位符
日志模板中包含(traceid,spanid)的占位符,肯定是初始化日志配置时,修改了默认的日志模板,因此需要追踪spring日志配置的初始化代码。经搜索知道spring的日志配置是在LoggingApplicationListener中配置,因此追踪到如下代码。
org.springframework.boot.context.logging.LoggingApplicationListener#onApplicationEvent
public void onApplicationEvent(ApplicationEvent event) {if (event instanceof ApplicationStartingEvent) {onApplicationStartingEvent((ApplicationStartingEvent) event);}# 日志配置初始化在这个阶段else if (event instanceof ApplicationEnvironmentPreparedEvent) {onApplicationEnvironmentPreparedEvent((ApplicationEnvironmentPreparedEvent) event);}......}private void onApplicationEnvironmentPreparedEvent(ApplicationEnvironmentPreparedEvent event) {if (this.loggingSystem == null) {# loggingSystem 为spring抽象的日志系统,其包含了日志的配置,初始化等功能this.loggingSystem = LoggingSystem.get(event.getSpringApplication().getClassLoader());}initialize(event.getEnvironment(), event.getSpringApplication().getClassLoader());}
org.springframework.boot.logging.LoggingSystem#get(java.lang.ClassLoader)
判断系统中存在的日志实现,取第一个,Logback优先。
static {Map<String, String> systems = new LinkedHashMap<>();systems.put("ch.qos.logback.classic.LoggerContext","org.springframework.boot.logging.logback.LogbackLoggingSystem");systems.put("org.apache.logging.log4j.core.impl.Log4jContextFactory","org.springframework.boot.logging.log4j2.Log4J2LoggingSystem");systems.put("java.util.logging.LogManager", "org.springframework.boot.logging.java.JavaLoggingSystem");SYSTEMS = Collections.unmodifiableMap(systems);}public static LoggingSystem get(ClassLoader classLoader) {........return SYSTEMS.entrySet().stream().filter((entry) -> ClassUtils.isPresent(entry.getKey(), classLoader)).map((entry) -> get(classLoader, entry.getValue())).findFirst().orElseThrow(() -> new IllegalStateException("No suitable logging system located"));}
org.springframework.boot.context.logging.LoggingApplicationListener#initialize
protected void initialize(ConfigurableEnvironment environment, ClassLoader classLoader) {new LoggingSystemProperties(environment).apply();this.logFile = LogFile.get(environment);if (this.logFile != null) {this.logFile.applyToSystemProperties();}this.loggerGroups = new LoggerGroups(DEFAULT_GROUP_LOGGERS);initializeEarlyLoggingLevel(environment);# 初始化日志系统initializeSystem(environment, this.loggingSystem, this.logFile);initializeFinalLoggingLevels(environment, this.loggingSystem);registerShutdownHookIfNecessary(environment, this.loggingSystem);}
org.springframework.boot.logging.logback.LogbackLoggingSystem#initialize
public void initialize(LoggingInitializationContext initializationContext, String configLocation, LogFile logFile) {LoggerContext loggerContext = getLoggerContext();super.initialize(initializationContext, configLocation, logFile);......}private LoggerContext getLoggerContext() {# LoggerFactory本身就是单例,日志配置包含在了其中,因此对其进行配置即可ILoggerFactory factory = StaticLoggerBinder.getSingleton().getLoggerFactory();return (LoggerContext) factory;}
org.springframework.boot.logging.logback.LogbackLoggingSystem#loadDefaults
protected void loadDefaults(LoggingInitializationContext initializationContext, LogFile logFile) {LoggerContext context = getLoggerContext();stopAndReset(context);boolean debug = Boolean.getBoolean("logback.debug");if (debug) {StatusListenerConfigHelper.addOnConsoleListenerInstance(context, new OnConsoleStatusListener());}LogbackConfigurator configurator = debug ? new DebugLogbackConfigurator(context): new LogbackConfigurator(context);Environment environment = initializationContext.getEnvironment();# 关键点-从spring配置中获取值,并配置LogContext自己的LOG_LEVEL_PATTERN变量的值context.putProperty(LoggingSystemProperties.LOG_LEVEL_PATTERN,environment.resolvePlaceholders("${logging.pattern.level:${LOG_LEVEL_PATTERN:%5p}}"));context.putProperty(LoggingSystemProperties.LOG_DATEFORMAT_PATTERN, environment.resolvePlaceholders("${logging.pattern.dateformat:${LOG_DATEFORMAT_PATTERN:yyyy-MM-dd HH:mm:ss.SSS}}"));context.putProperty(LoggingSystemProperties.ROLLING_FILE_NAME_PATTERN, environment.resolvePlaceholders("${logging.pattern.rolling-file-name:${LOG_FILE}.%d{yyyy-MM-dd}.%i.gz}"));new DefaultLogbackConfiguration(initializationContext, logFile).apply(configurator);context.setPackagingDataEnabled(true);}
org.springframework.boot.logging.logback.DefaultLogbackConfiguration#apply
上一步loadDefaults中会给LoggerContext配置${LOG_LEVEL_PATTERN:-%5p}占位符的值。
# 默认的日志模板private static final String FILE_LOG_PATTERN = "%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd HH:mm:ss.SSS}} "+ "${LOG_LEVEL_PATTERN:-%5p} ${PID:- } --- [%t] %-40.40logger{39} : %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}";void apply(LogbackConfigurator config) {synchronized (config.getConfigurationLock()) {base(config);Appender<ILoggingEvent> consoleAppender = consoleAppender(config);......}}# 完成日志模板的配置private Appender<ILoggingEvent> consoleAppender(LogbackConfigurator config) {ConsoleAppender<ILoggingEvent> appender = new ConsoleAppender<>();PatternLayoutEncoder encoder = new PatternLayoutEncoder();String logPattern = this.patterns.getProperty("logging.pattern.console", CONSOLE_LOG_PATTERN);encoder.setPattern(OptionHelper.substVars(logPattern, config.getContext()));config.start(encoder);appender.setEncoder(encoder);config.appender("CONSOLE", appender);return appender;}
org.springframework.cloud.sleuth.autoconfig.TraceEnvironmentPostProcessor#postProcessEnvironment
最终在sleuth中找到其通过TraceEnvironmentPostProcessor提前配置好了logging.pattern.level变量,用以将(traceid、spanid)的占位符嵌入到日志模板中
public void postProcessEnvironment(ConfigurableEnvironment environment,SpringApplication application) {Map<String, Object> map = new HashMap<String, Object>();// This doesn't work with all logging systems but it's a useful default so you see// traces in logs without having to configure it.if (sleuthEnabled(environment)&& sleuthDefaultLoggingPatternEnabled(environment)) {map.put("logging.pattern.level", "%5p [${spring.zipkin.service.name:"+ "${spring.application.name:}},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]");}addOrReplace(environment.getPropertySources(), map);}
日志打印时如何获取filter中生成的(traceid、spanid)
跟踪日志打印的代码可以发现sleuth借助日志系统的MDC特性,将traceid、spanid塞到相关容器中,供logback替换占位符时查询真实的值。
日志系统有一些内置的变量,比如线程号,用于替换日志模板中的占位符;为了支持自定义的占位符,需要一个容器去存储这个占位符所对应的值。该容器即为MDC。可以百度MDC获得跟多相关知识。
通过截图可以看到logback从MDC中获取的traceid、spanid等值,用于后续替换占位符。

获取MDCPropertyMap的方法为ch.qos.logback.classic.util.LogbackMDCAdapter#getPropertyMap。
可以在设值的地方打断点,分析sleuth是何时设置进来的。

从下面截图中可以看到是在sleuth的filter中去设置这些值的。