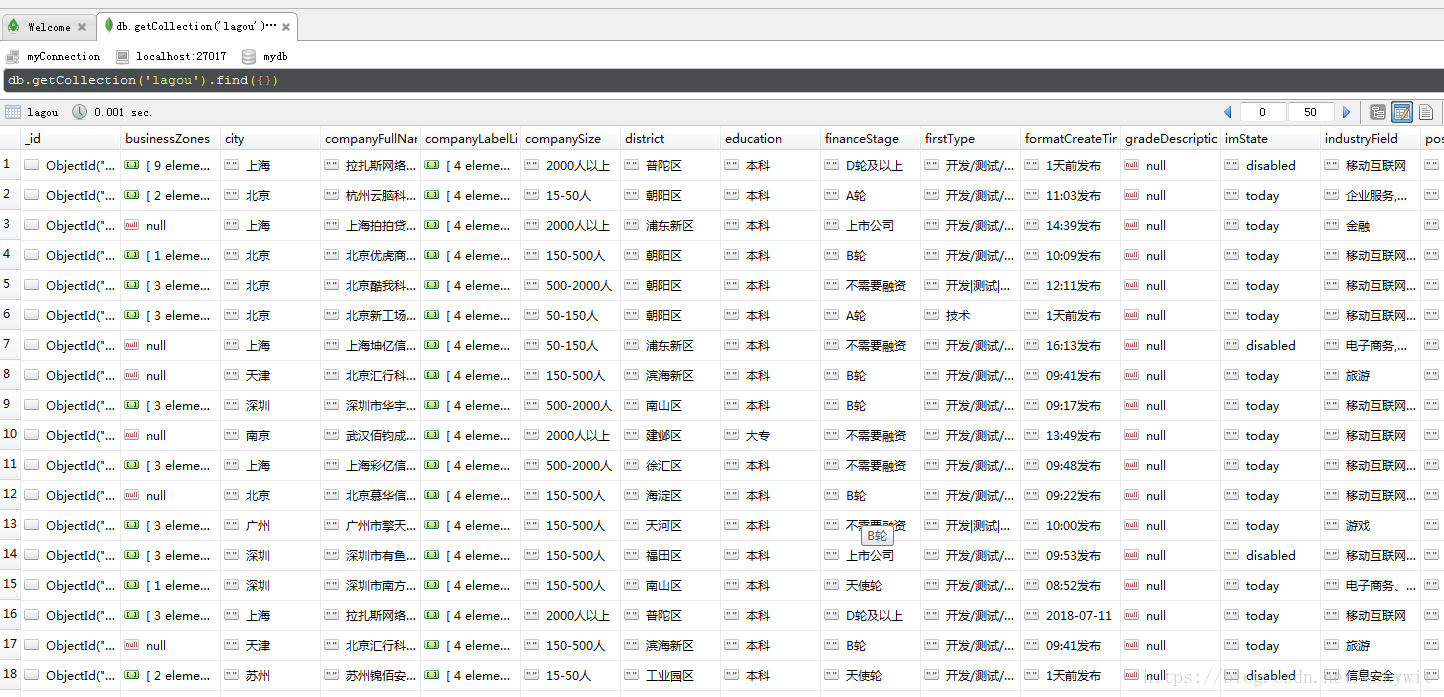
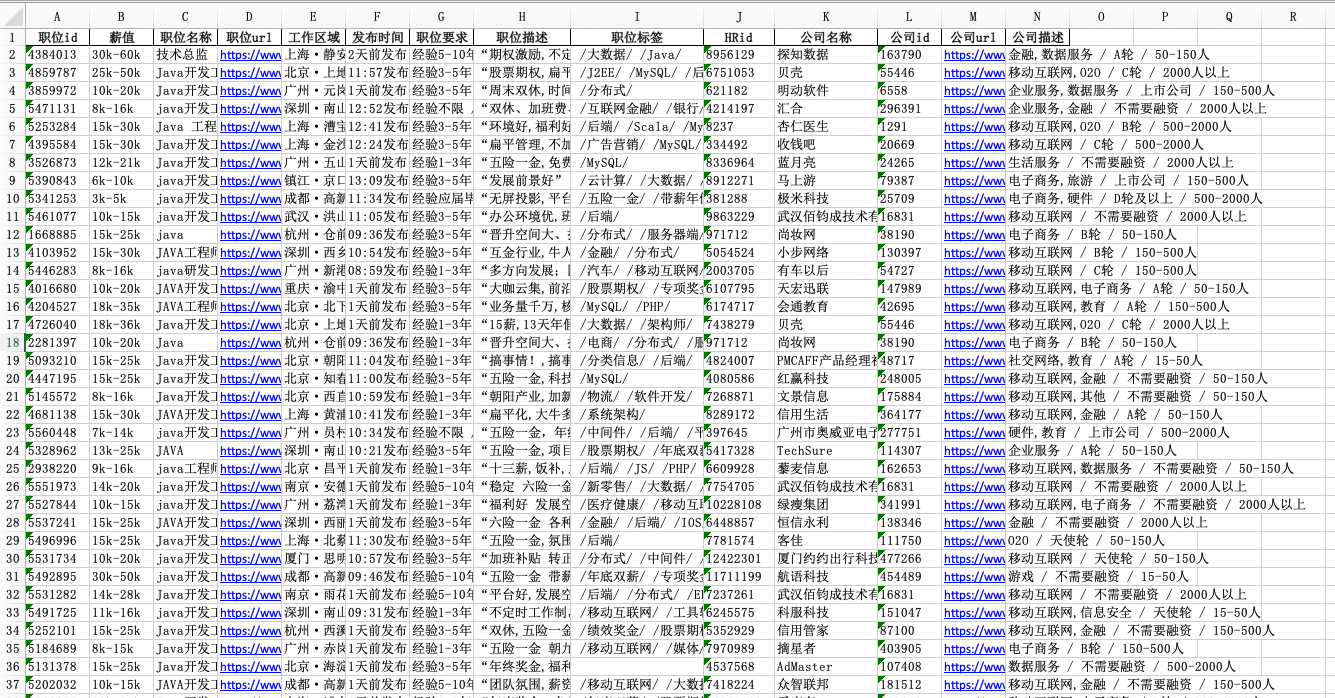
源代码:https://github.com/carlblocking/xxw-for-public/tree/master/LaGouSpider
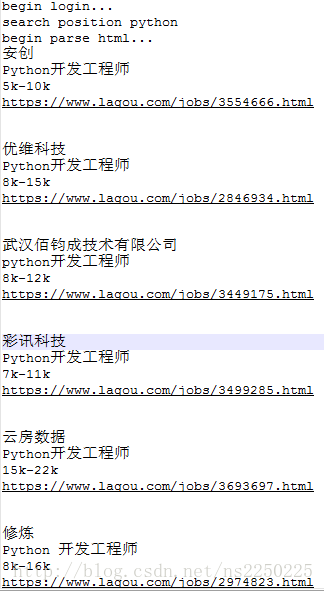
前几天写了一个知乎网的爬虫并爬取了一些数据,然而新鲜感消失的很快。于是,大概2天前开始试着爬取拉勾网上的数据。
在解析数据的过程中,知乎爬虫主要通过正则表达式来解析网页,而这次则通过jsoup来解析。在运行的过程中,能明显感受到二者的区别。
首先是使用正则表达式:优点:代码简洁。缺点:正则表达式较为复杂,初学者理解有难度。
其次是使用jsoup解析网页:优点:代码简洁,上手容易,而且运行速度一流,程序效率有了大幅度的提升。
/**该代码用于存储职位详情链接*/
public static List<String> getUserUrl(String string){
List<String> userUrls=new ArrayList<String>();
try {
Document document=Jsoup.connect(string).get();
Elements hrefs=document.getElementsByClass("position_link");
for(Element element:hrefs){
userUrls.add(element.attr("href").replace("//", ""));
}
return userUrls;
} catch (IOException e) {
// TODO: handle exception
e.printStackTrace();
return null;
}
}
/**该代码主要用于解析网页*/
Document document=Jsoup.connect(url).get();
Element element=document.select("meta[name]").get(2);
/*获得含有工作名称、公司名称的字符串,之后可以进行进一步的解析*/
String content=element.attr("content");
jobName=getJobName(content);
jobCompany=getJobComapany(content);
/*获得工资字符串*/
salary=document.getElementsByTag("span").get(3).text();
/*获得最大、最小字符串*/
String[] salarys=salary.split("[-]");
try {
minSalary=salarys[0];
maxSalary=salarys[1];
} catch (ArrayIndexOutOfBoundsException e) {
minSalary=null;
maxSalary=null;
}
/*获得公司地址*/
jobAddress=document.getElementsByTag("span").get(4).text();
/*获得工作经验*/
experience=document.getElementsByTag("span").get(5).text();
/*获得学历要求*/
education=document.getElementsByTag("span").get(6).text();
/*查找领域、融资情况*/
Elements results=document.select(".c_feature").select("li");
/*领域*/
industry=results.get(0).text().replace("领域 ", "");
/*融资*/
growth=results.get(3).text().replace("目前阶段 ", "");