拉勾网的反爬介绍和解决方法(更新时间:2019/2/20)
目录直达:
文章目录
- 拉勾网的反爬介绍和解决方法(更新时间:2019/2/20)
- 1. 前言
- 2. 简述
- 3. 反爬介绍
- 3.1、对于职位的详情页和公司的详情页的反爬:
- 3.2、对于职位列表页的反爬:
- 3.3、注意:
1. 前言
最近拉勾的反爬改动比较频繁,公司采集拉勾网的爬虫又无法正式运行,花了近一周的时间来处理拉勾网的反爬问题,特别写一篇博客来记录一下拉勾的反爬
2. 简述
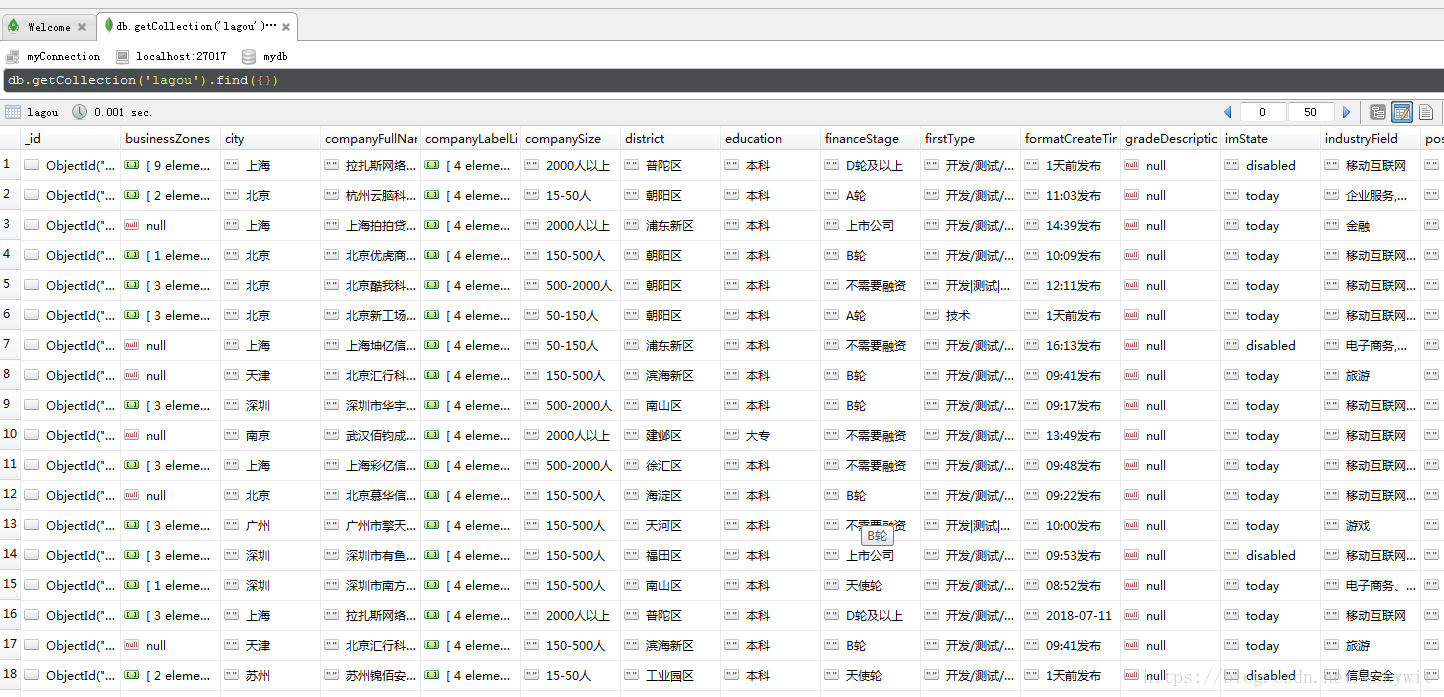
爬拉勾的时候,主要是采集职位相关的信息,涉及到页面有3个:
- 输入关键词搜索后得到的职位列表页:https://www.lagou.com/jobs/list_python?px=new&city=%E4%B8%8A%E6%B5%B7#order
- 职位详情页:https://www.lagou.com/jobs/5371803.html
- 公司详情页:https://www.lagou.com/gongsi/225514.html
3. 反爬介绍
3.1、对于职位的详情页和公司的详情页的反爬:
职位的详情页和公司的详情页的信息都能在页面源代码中获取到,请求这两个页面也没有使用太多反爬,只需要在请求的时候加入headers参数即可,不过前提是你知道页面的URL,即你需要在职位列表页中获取到职位id和公司id,才能拼接URL,得到相关的职位详情页和公司详情页
3.2、对于职位列表页的反爬:
要获取职位列表的信息,相对于比职位和公司的详情页,难度的要大一点
列表页使用了ajax加载,直接去请求原网页是获取不到想要的信息,我们打开网页:https://www.lagou.com/jobs/list_java?labelWords=&fromSearch=true&suginput=?labelWords=hot,看一下源代码
源代码没有我们需要的数据,但是网页上有显示数据,那么数据肯定是以别的方式传过来的,我们找一下数据,看哪个请求中有返回有我们需要的数据,看下找到的请求,按一下F12进入开发者模式,再点击Network–>XHR–>点击第一个请求–>response
这里返回的是一个json的可是,里面有我们需要的信息(按ctrl+F搜索关键字验证信息是否在返回的数据中)
既然找到我们需要的数据,那么如何让爬虫来获取到呢,点击Headers,我们看一下请求头,发现是个post请求,直接去构造请求来访问这个接口,发现返回的是
{"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"183.160.238.206","state":2402}并不是你访问频繁,是因为网站对cookies设置了反爬,cookies每次访问都会发生变化,想要获取这个接口的数据,需要请求2次,第一次请求的页面是源代码那个页面(即:https://www.lagou.com/jobs/list_java?labelWords=&fromSearch=true&suginput=?labelWords=hot),直接get请求这个页面,虽然不能直接获取到需要的数据,但是能获取到cookies,服务器返回的时候会返回一个cookies参数,来更新cookies,我们在把更新后的cookies,放到post请求的参数中,就可以获取到接口的数据了
我们看一下成功请求的代码:
import requests
'''
说明:本代码只是测试,你能够使用它获得一次请求的数据,需要连续请求还请修改代码'''
headers = {'Connection': 'keep-alive','Cache-Control': 'max-age=0','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
response = requests.get('https://www.lagou.com/jobs/list_?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=',headers=headers) # 请求原网页
r = requests.utils.dict_from_cookiejar(response.cookies) # 获取cookies
r["user_trace_token"] = r["LGRID"]
r["LGSID"] = r["LGRID"]
r["LGUID"] = r["LGRID"] # 构造cookies的参数
cookies = {'X_MIDDLE_TOKEN': '797bc148d133274a162ba797a6875817','JSESSIONID': 'ABAAABAAAIAACBI03F33A375F98E05C5108D4D742A34114','_ga': 'GA1.2.1912257997.1548059451','_gat': '1','Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1548059451','user_trace_token': '20190121163050-dbd72da2-1d56-11e9-8927-525400f775ce','LGSID': '20190121163050-dbd72f67-1d56-11e9-8927-525400f775ce','PRE_UTM': '','PRE_HOST': '','PRE_SITE': '','PRE_LAND': 'https%3A%2F%2Fwww.lagou.com%2F%3F_from_mid%3D1','LGUID': '20190121163050-dbd73128-1d56-11e9-8927-525400f775ce','_gid': 'GA1.2.1194828713.1548059451','index_location_city': '%E5%85%A8%E5%9B%BD','TG-TRACK-CODE': 'index_hotjob','LGRID': '20190121163142-fb0cc9c0-1d56-11e9-8928-525400f775ce','Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1548059503','SEARCH_ID': '86ed37f5d8da417dafb53aa25cd6fbc0',
}
cookies.update(r) # 更新接口的cookies
headers = {'Origin': 'https://www.lagou.com','X-Anit-Forge-Code': '0','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Accept': 'application/json, text/javascript, */*; q=0.01','Referer': 'https://www.lagou.com/jobs/list_java?px=new&city=%E4%B8%8A%E6%B5%B7','X-Requested-With': 'XMLHttpRequest','Connection': 'keep-alive','X-Anit-Forge-Token': 'None',
}params = (('px', 'new'),('city', '\u4E0A\u6D77'),('needAddtionalResult', 'false'),
)data = {'first': True,'kd': 'java','pn': 1}
response = requests.post('https://www.lagou.com/jobs/positionAjax.json', headers=headers, params=params,cookies=cookies, data=data) # 请求接口
print(response.json())3.3、注意:
- 这样可以单次请求接口获取到数据,每次请求接口之前都要请求原网页,以获取cookies
- 每次请求列表页数据接口的时间间隔保持在1秒以上,不然可能会被封ip