1. 明确需求
1. 初学爬虫时,看着各路大佬以拉勾网为案例进行爬虫讲解,自己也这样尝试。结果因为个人水平实在太低,很快就触发反爬虫机制,甚至连个人的账号都被封禁。所以这次想要重新挑战一下,爬取拉勾展示的招聘数据。
2. 对拉勾网进行简单分析后,发现至少有两种抓取数据的方法:
1) 通过拉勾首页获取所有职业分类及其对应url,然后对每个职业分类构造url进行翻页,直接从返回html代码中抓取内容
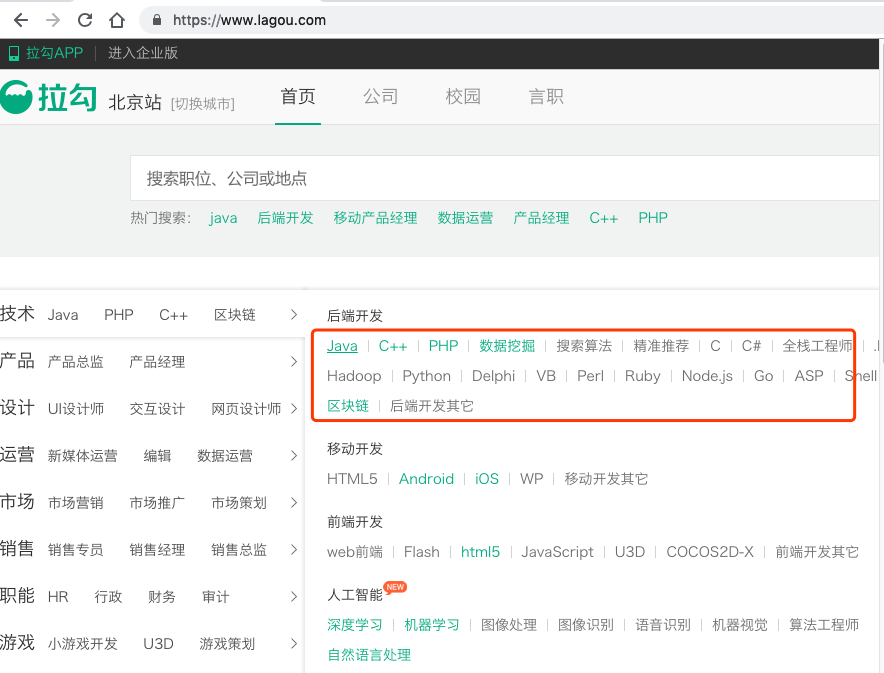
2) 通过关键字搜索获取岗位信息,从对应接口抓取信息
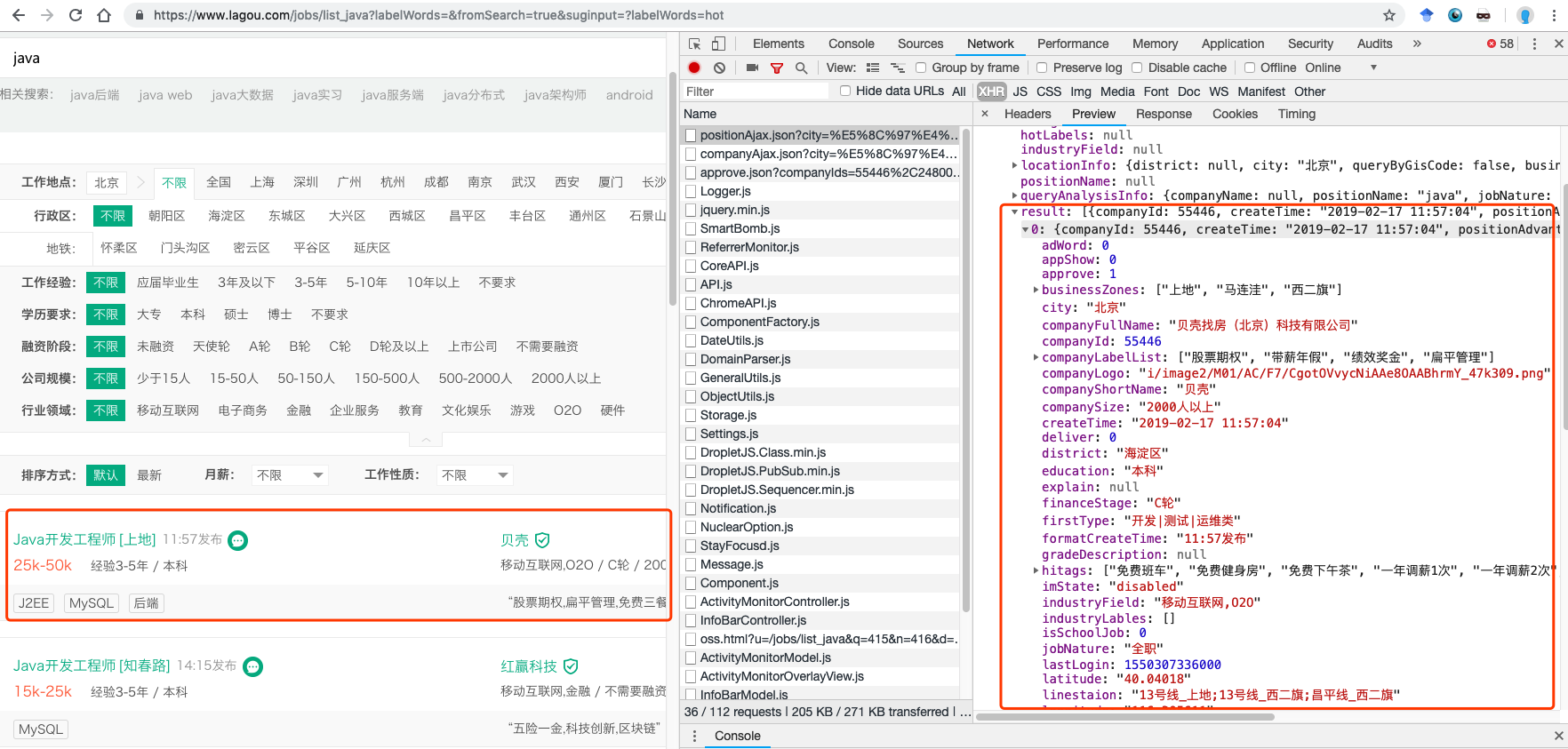
这个方法的难点在于cookies处理,可以参考如下博文实现:
【Python3爬虫】拉勾网爬虫
Python数据可视化:浅谈拉勾网Python爬虫职位
3. 网络上较多的博文都是介绍方法二,通过接口进行数据抓取。由于拉勾每次访问的cookies都不一致,爬取时需要先访问页面获取cookies再使用获取的cookies访问接口才可以获得数据,相比起方法一更为繁琐(方法一不通过接口,访问页面后即可获得数据),这次就使用方法一来抓取数据。
2. 分析页面
1. 首先通过拉勾首页获取每个职位对应的名称及url,可以直接从首页html代码中提取
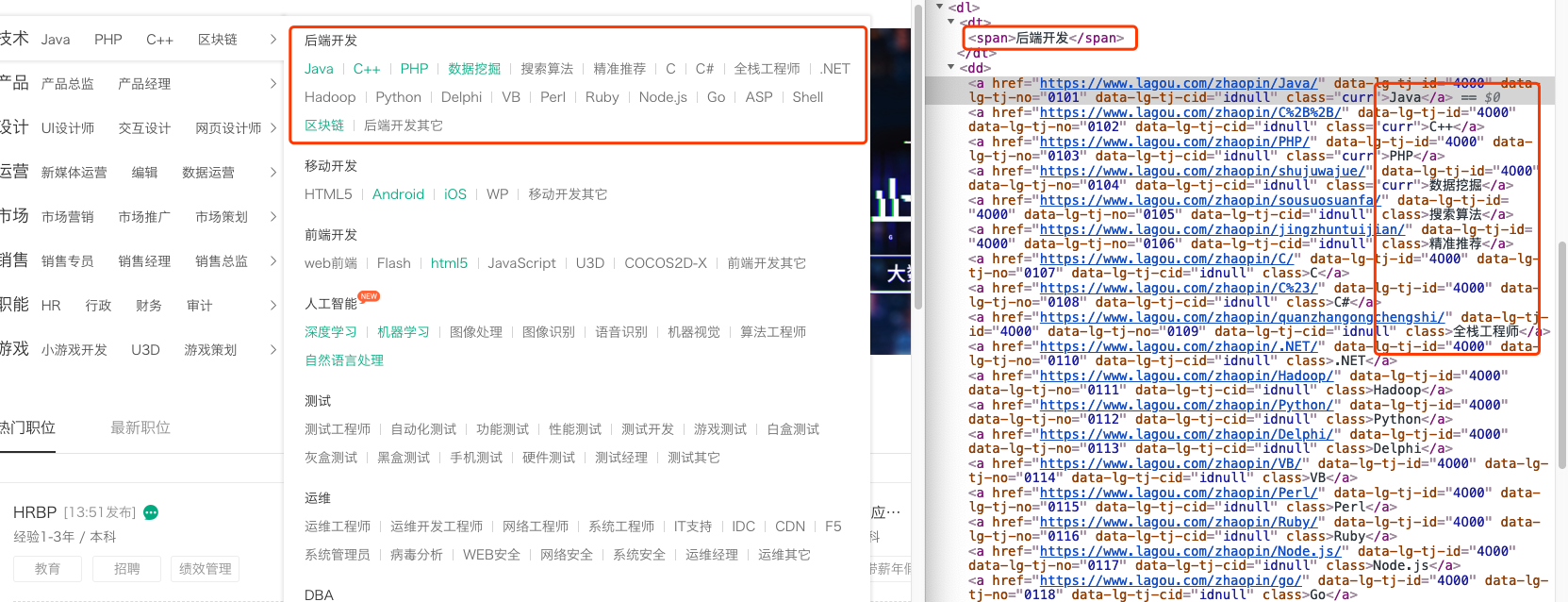
2. 从首页获取的url点击进入相应职位的列表页,以Java为例。
未发现接口,直接通过列表页返回的html代码进行提取
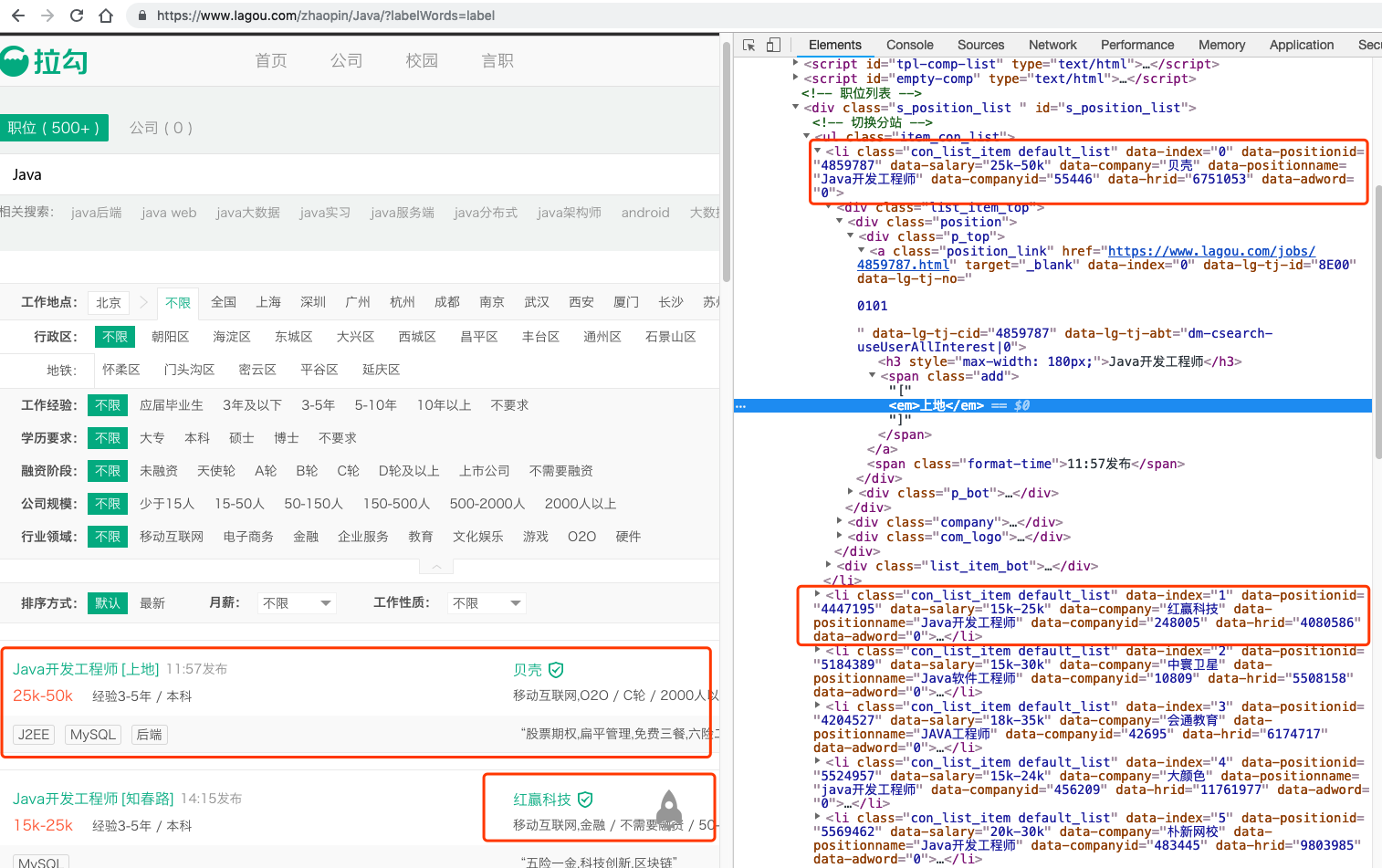
3. 每个职位只展示最多30页的数据
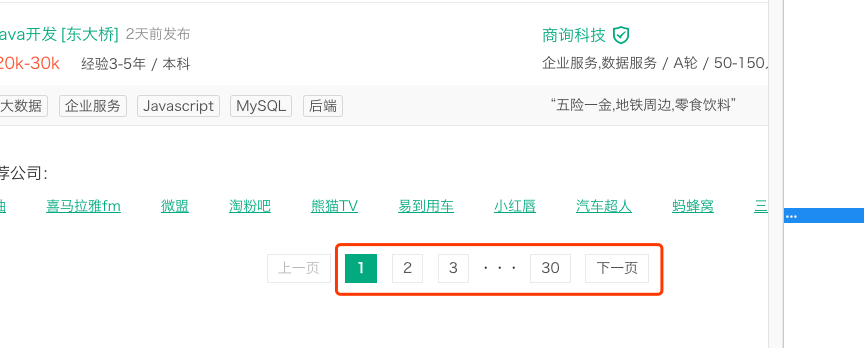
对应url为:
第一页:https://www.lagou.com/zhaopin/Java/?filterOption=3
第二页:https://www.lagou.com/zhaopin/Java/2/?filterOption=3
第三页:https://www.lagou.com/zhaopin/Java/3/?filterOption=3
测试发现filterOption参数未影响查询结果,因此只需要对url结尾修改数字即可翻页:https://www.lagou.com/zhaopin/Java/页数/
3. 编写代码
1. 访问首页获取每个职位对应url
def get_index(index_url):'''通过拉勾首页获取各职位对应名称及url因为对首页只是一次访问即可获取,不做headers/cookies设置'''r = requests.get(index_url)soup_index = BeautifulSoup(r.text, 'lxml')position_list = [] # 保存各职位名称+urlfor each_first in soup_index.select('#sidebar > div > .menu_box'):first_name = each_first.select_one('h2').get_text().strip(' \n') # 第一分类名称for each_second in each_first.select('div.menu_sub.dn > dl'):second_name = each_second.select_one('dt > span').get_text() # 第二分类名称for each_third in each_second.select('dd > a'):third_name = each_third.get_text() # 职位名称third_url = each_third['href'] # 职位urlposition_list.append([first_name, second_name, third_name, third_url])return position_list
2. 使用Session维持会话,访问某个职业分类时使用同一个会话
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'max-age=0','Connection': 'keep-alive','DNT': '1','Host': 'www.lagou.com','Upgrade-Insecure-Requests': '1','User-Agent': choose_ua() # 每个职位,随机选择一个User-Agent
}s = requests.Session() # 创建会话
s.headers.update(headers) # 需要设置headers信息,否则返回登陆页面
s.proxies = { # 设置ip代理池'HTTP': 'http://110.52.235.241:9999','HTTP': 'http://121.61.1.2:9999'}
s.get('http://www.lagou.com') # session首先访问首页,获得cookies3. 翻页抓取职位数据
position_info = [] # 保存职位数据for pn in range(1, 31, 1):r = s.get(positions_url + str(pn) + '/') # 构建url,进行翻页访问time.sleep(random.uniform(1.2, 3.4))if len(r.text)<2000: break # 如果翻页完毕(返回页面长度<2000),退出当前职位的爬取soup_positon = BeautifulSoup(r.text, 'lxml')for each_position in soup_positon.select('#s_position_list > ul > li'):position_id = each_position['data-positionid'] # 职位idposition_salary = each_position['data-salary'] # 薪资position_name = each_position['data-positionname'] # 职位名称position_url = each_position.select_one('.position_link')['href'] # 职位urlposition_area = each_position.select_one('.add > em').get_text() # 工作地点position_publishtime = each_position.select_one('.format-time').get_text() # 发布时间position_requ = each_position.select_one('div.position > div.p_bot > div.li_b_l').get_text().split('\n')[-2] # 职位要求position_desc = each_position.select_one('div.li_b_r').get_text() # 职位描述position_tags = each_position.select_one('div.list_item_bot > div.li_b_l').get_text('/') # 职位tagshr_id = each_position['data-hrid'] # HRidcompany_name = each_position['data-company'] # 供职公司company_id = each_position['data-companyid'] # 公司idcompany_url = each_position.select_one('.company_name > a')['href'] # 公司urlcompany_desc = each_position.select_one('div.industry').get_text().strip() # 公司行业描述position_info.append([position_id, position_salary, position_name, position_url, position_area, position_publishtime, position_requ, position_desc, position_tags, hr_id, company_name, company_id, company_url, company_desc])print(pn, position_name, 'done')
4. 完整代码查看
https://github.com/snistty/python_spider/blob/master/lagou_spider.py
4. 结果查验
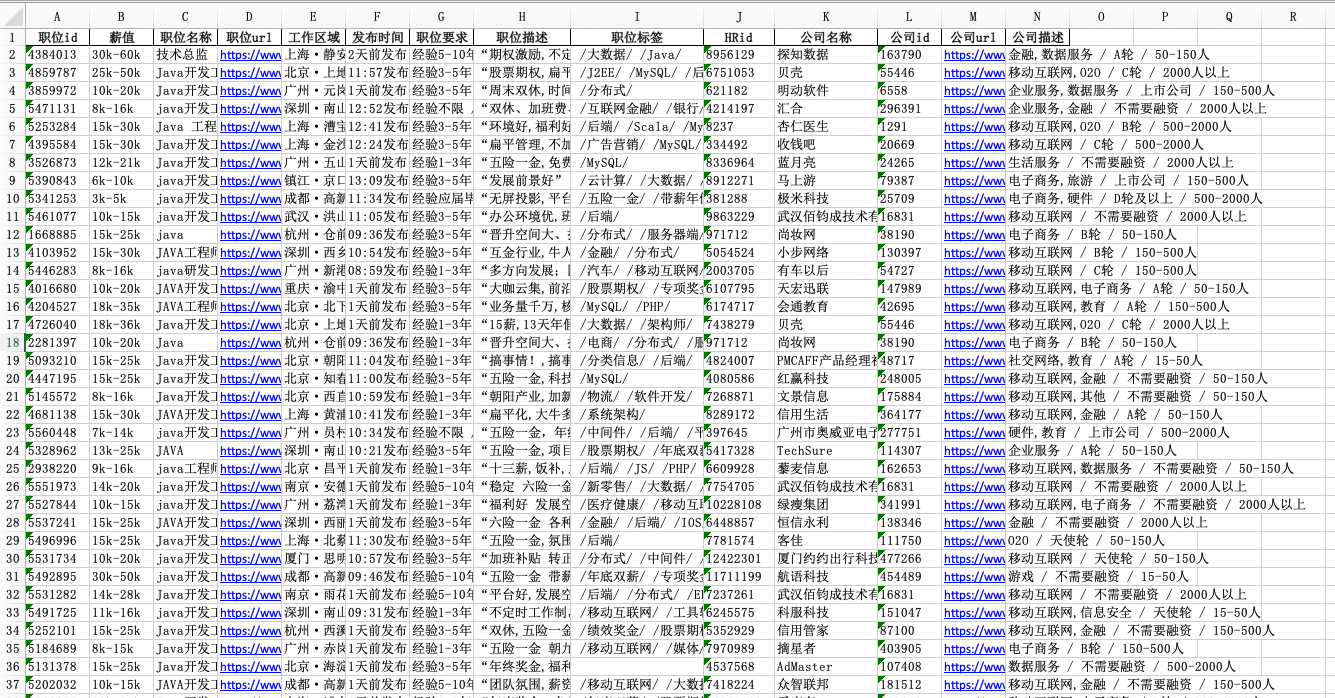
因为只是一个小练习,只抓取了四千条数据。将抓取结果保存至excel表,如图
5. 总结
1. 初期尝试爬取拉勾导致账号被封的主要原因在于:使用个人账号的cookies进行高频访问,被拦截后仍然进行多次尝试
2. 这次爬取成功的原因:
1) 爬取过程中有设置time.sleep进行延时,避免对对方服务器造成较大压力
2) 通过session会话维持解决了cookies和referer问题
3) 访问时有更换User-Agent和代理ip

















![[android] 百度地图开发 (三).定位当前位置及getLastKnownLocation获取location总为空问题](https://img-blog.csdn.net/20150110210258956)