这次要爬取拉勾网,拉勾网的反爬做的还是很不错的啊,因为目标网站是Ajax交互的我一开始是直接分析json接口来爬取的,但是真的很麻烦,请求头一旦出点问题就给识别出来了后续我就改了一下方法用selenium来模拟浏览器去获取
招聘求职信息-招聘网站-人才网-拉勾招聘 (lagou.com)![]() https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=先把前面代码写好
https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=先把前面代码写好
思路嘛大概就是 获取主页的源代码——从中获取详情页的url——在去解析 先围绕这三步来写
这里我们已经获取到了主页的源代码
from selenium import webdriver
import requests
from selenium.webdriver import ChromeOptions #这个包用来规避被检测的风险
from lxml import etree
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import reclass lagouSpitder(object):option = webdriver.ChromeOptions()option.add_experimental_option('useAutomationExtension', False)option.add_experimental_option('excludeSwitches', ['enable-automation'])driver_path = r'驱动路径' # 定义好路径def __init__(self):self.driver=webdriver.Chrome(executable_path=lagouSpitder.driver_path,options=lagouSpitder.option)#初始化路径+规避检测selenium框架self. driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})self.url='https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='self.positions=[]def run(self): #主页面self.driver.get(self.url)source = self.driver.page_source # source页面来源 先获取一页if __name__ == '__main__':spider=lagouSpitder() spider.run()接下来获取详情页的url,定义一个函数parse_list_page 显得美观可维护也强,可以看到 是在//a[@class="position_link"]里面的href属性里面,获取到了我们在去请求这个url一样是定义一个函数request_detall_page
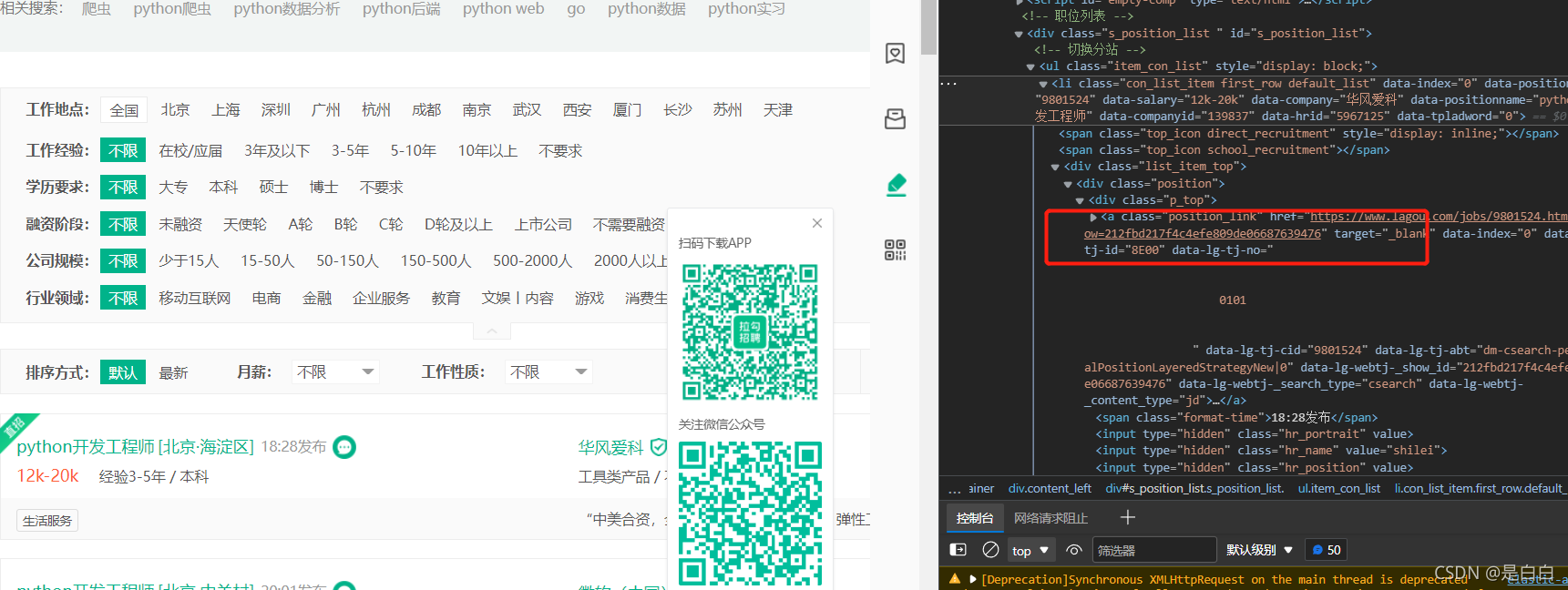
def parse_list_page(self,source): #获取职位详情页urlhtml=etree.HTML(source)links=html.xpath('//a[@class="position_link"]/@href')for link in links:self.request_detall_page(link)time.sleep(2)def request_detall_page(self,url): #去请求细节页面 self.driver.get(url)source=self.driver.page_source #source页面来源接下来我们去解析详情页即可 定义函数 pares_detail_page 这里就不细说了怎么解析获取了大家肯定都会,后面我要说一下具体的优化
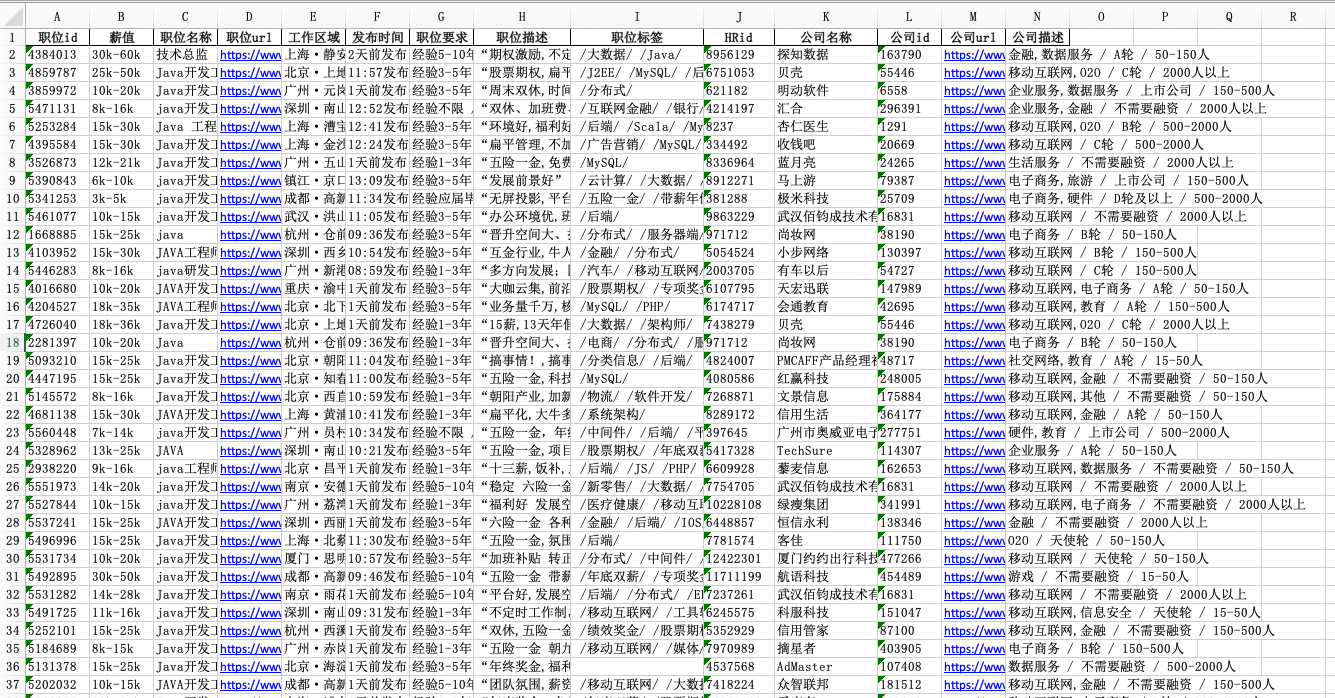
def pares_detail_page(self,source): #获取职位细节信息html=etree.HTML(source)Position_name=html.xpath('//span[@class="position-head-wrap-position-name"]/text()')[0] #职位名字salary=html.xpath('//span[@class="salary"]/text()')[0] #薪水Position_the_temptation=html.xpath('//dd[@class="job-advantage"]/p/text()')[0] #职位诱惑Job_description=html.xpath('//div[@class="job-detail"]/text()') #职位详情Job_description=''.join(html.xpath('//div[@class="job-detail"]/text()')).strip() #拼接work_address=html.xpath('//div[@class="work_addr"]/text()')[3] #工作地址CompanyName = html.xpath('//h3[@class="fl"]/em/text()')[0] # 公司名字Company_Basic_Information=html.xpath('//li/h4/text()') #公司基本信息position={'职位名字':Position_name,'薪水':salary,'职位诱惑':Position_the_temptation,'职位详情':Job_description,'工作地址':work_address,'公司名字': CompanyName,'公司基本信息':Compnya_Basic_Information,}self.positions.append(position)time.sleep(5)
这样其实我们就已经写完了这个程序,不过这只能获取第一页对吧,我们肯定不只爬取第一页的所以就要进行优化
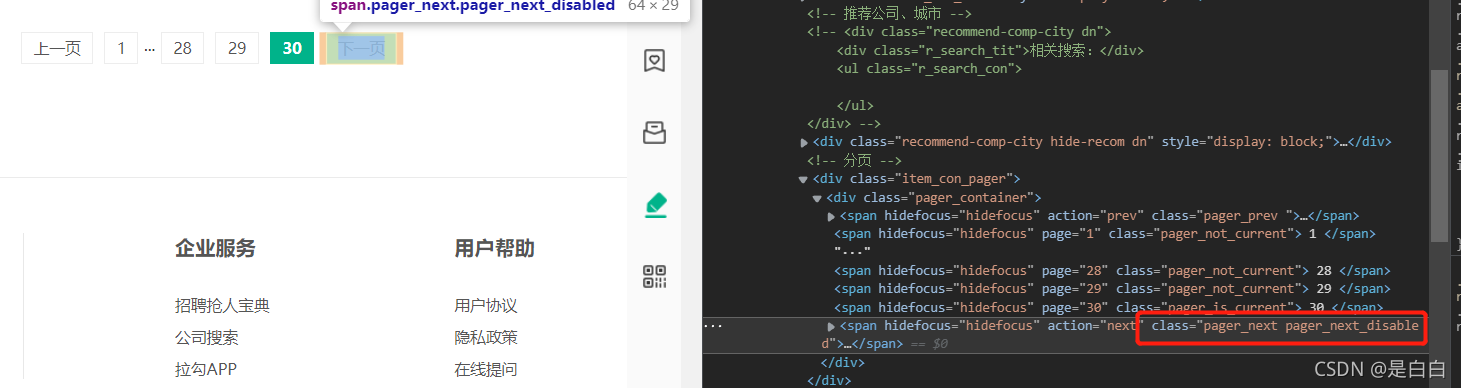
网站是通过点击下一页翻页,那么我们先获取到下一页的元素

 获取到元素我们可以写个循环嘛,让他解析完一页之后去点击下一页,那什么时候停止呢?可以看到我们点击第三十页的时候 它的class是不是就变了呀我们写个判断语句当它class=pager_next pager_next_disabled 这个的时候我们就停止否则就继续点击,这里也要一起写一个显示等待我爬取的时候就有几次因为这个没有加载出来导致报错
获取到元素我们可以写个循环嘛,让他解析完一页之后去点击下一页,那什么时候停止呢?可以看到我们点击第三十页的时候 它的class是不是就变了呀我们写个判断语句当它class=pager_next pager_next_disabled 这个的时候我们就停止否则就继续点击,这里也要一起写一个显示等待我爬取的时候就有几次因为这个没有加载出来导致报错
def run(self): #主页面self.driver.get(self.url) #去请求主页面while True:source = self.driver.page_source # source页面来源 先获取一页WebDriverWait(driver=self.driver,timeout=10).until(EC.presence_of_element_located((By.XPATH,'//span[@action="next"]'))) #等待按钮加载出来,避免没加载出来就点击导致的报错self.parse_list_page(source) # 获取这一页职位urlnext_btn = self.driver.find_element_by_xpath('//span[@action="next"]')#下一页的元素位置if "pager_next pager_next_disabled" in next_btn.get_attribute('class'): # 如果class等于最后一页则停止,否则继续点击breakelse:next_btn.click() #点击下一页time.sleep(1)接下来我们还得新开窗口,为什么呢详情页哪里来的下一页按钮这不得报错呀
def request_detall_page(self,url): #去请求细节页面# self.driver.get(url)self.driver.execute_script("window.open('%s')"%url) #新打开一个职位页面self.driver.switch_to_window(self.driver.window_handles[1]) #切换到当前页面来解析,不切换的话selenium会停留在上一页source=self.driver.page_source #source页面来源self.pares_detail_page(source) #解析页面self.driver.close() #解析完关闭页面time.sleep(0.5)self.driver.switch_to_window(self.driver.window_handles[0]) #切换回主页面我们来看下效果,也是没有问题呀
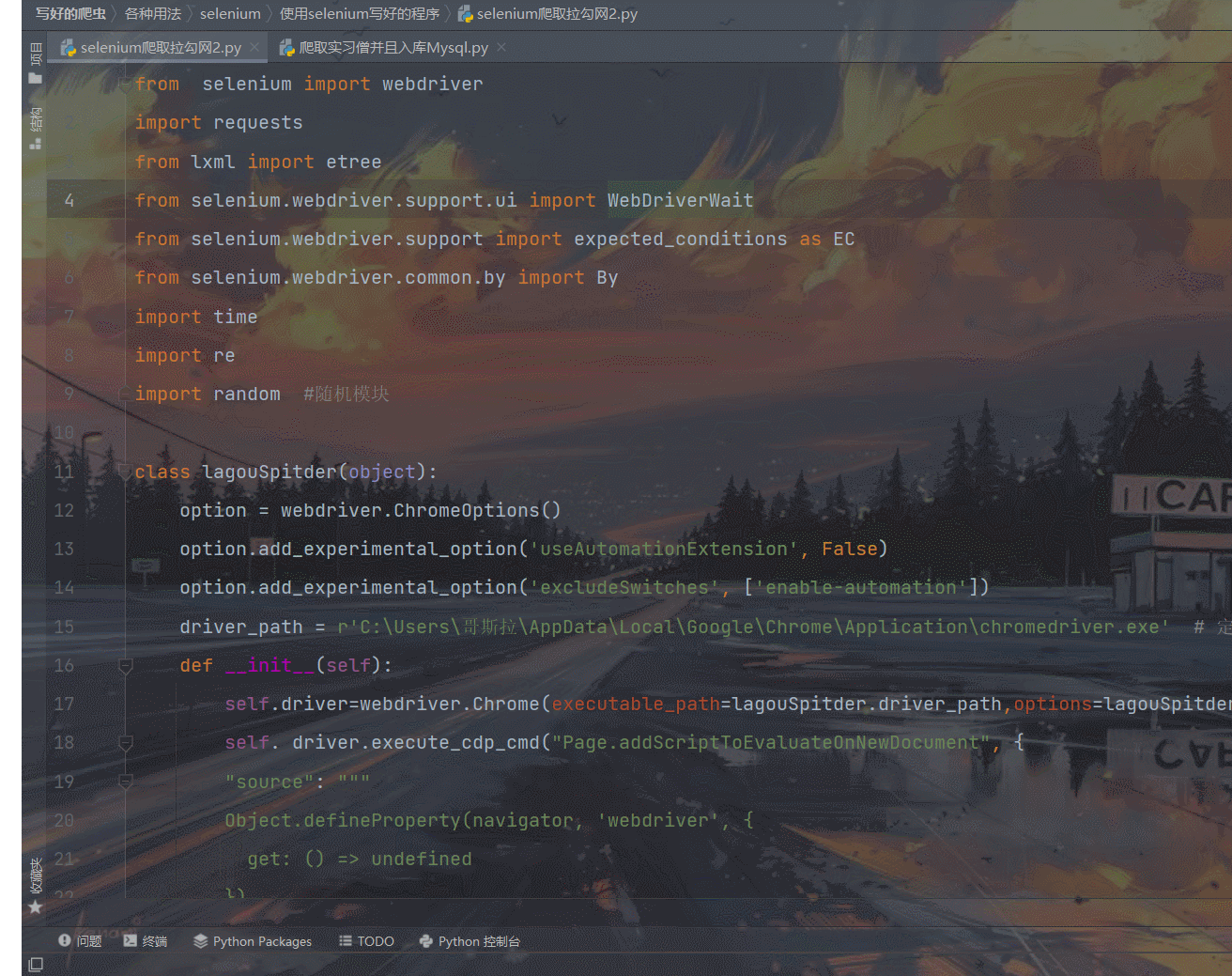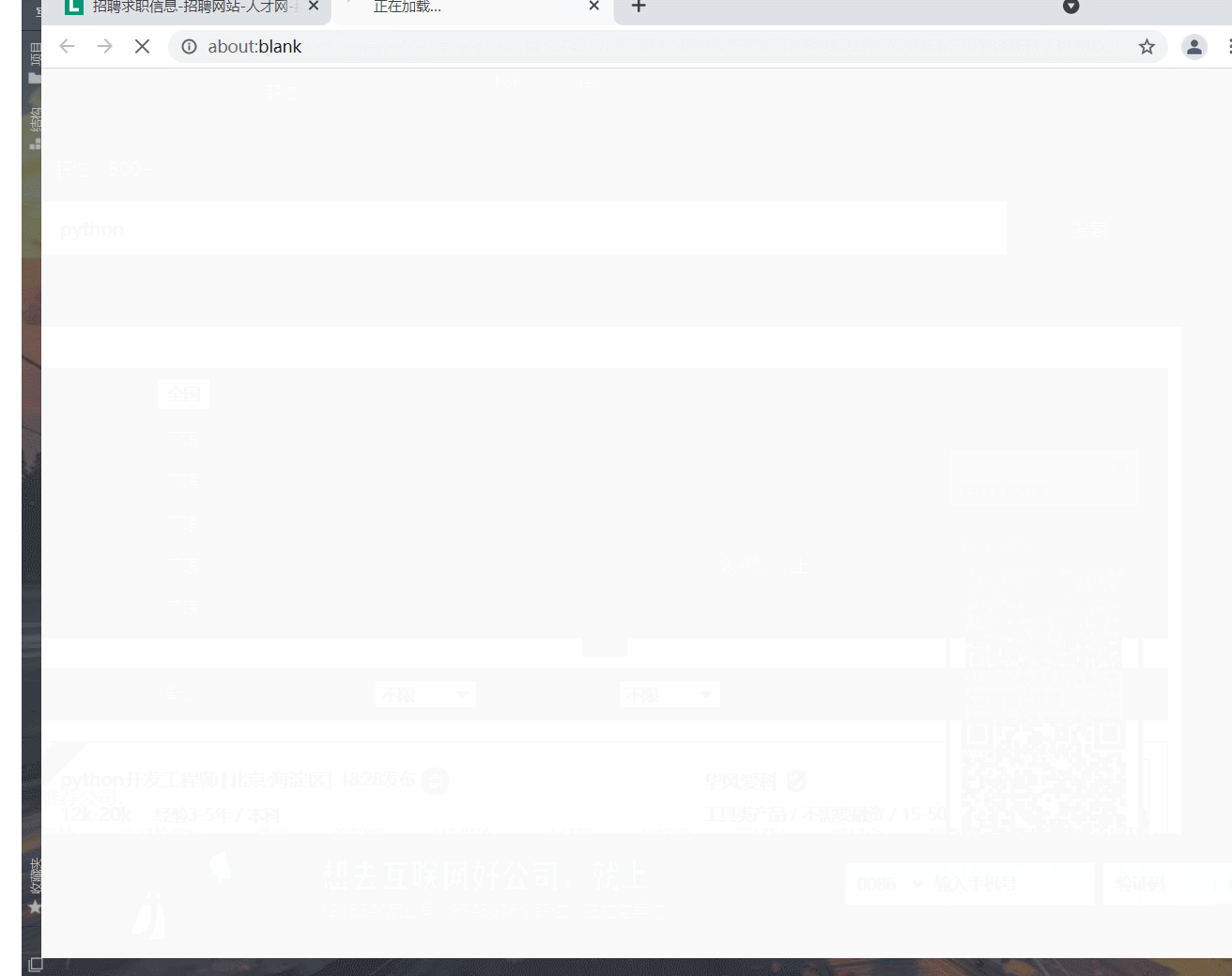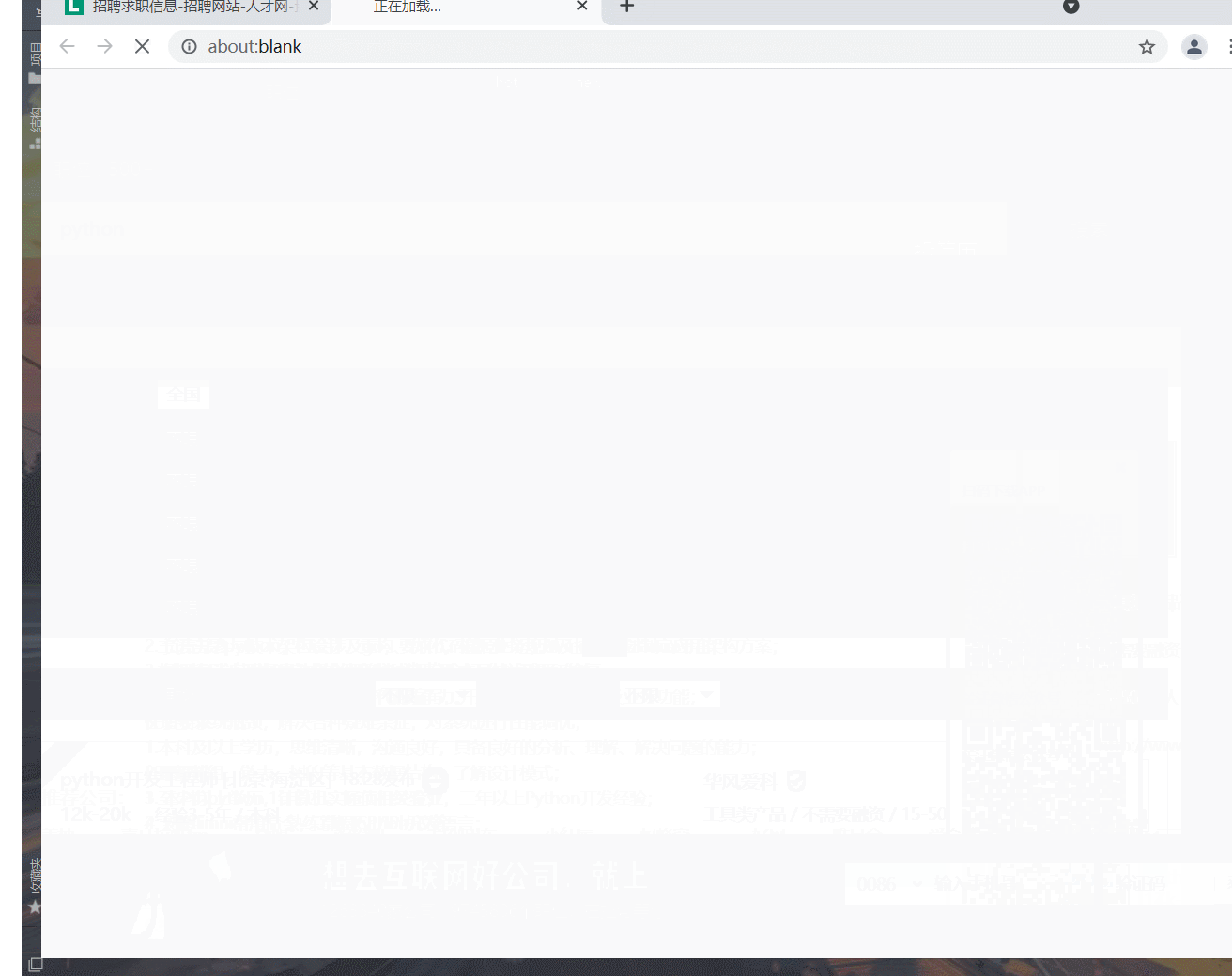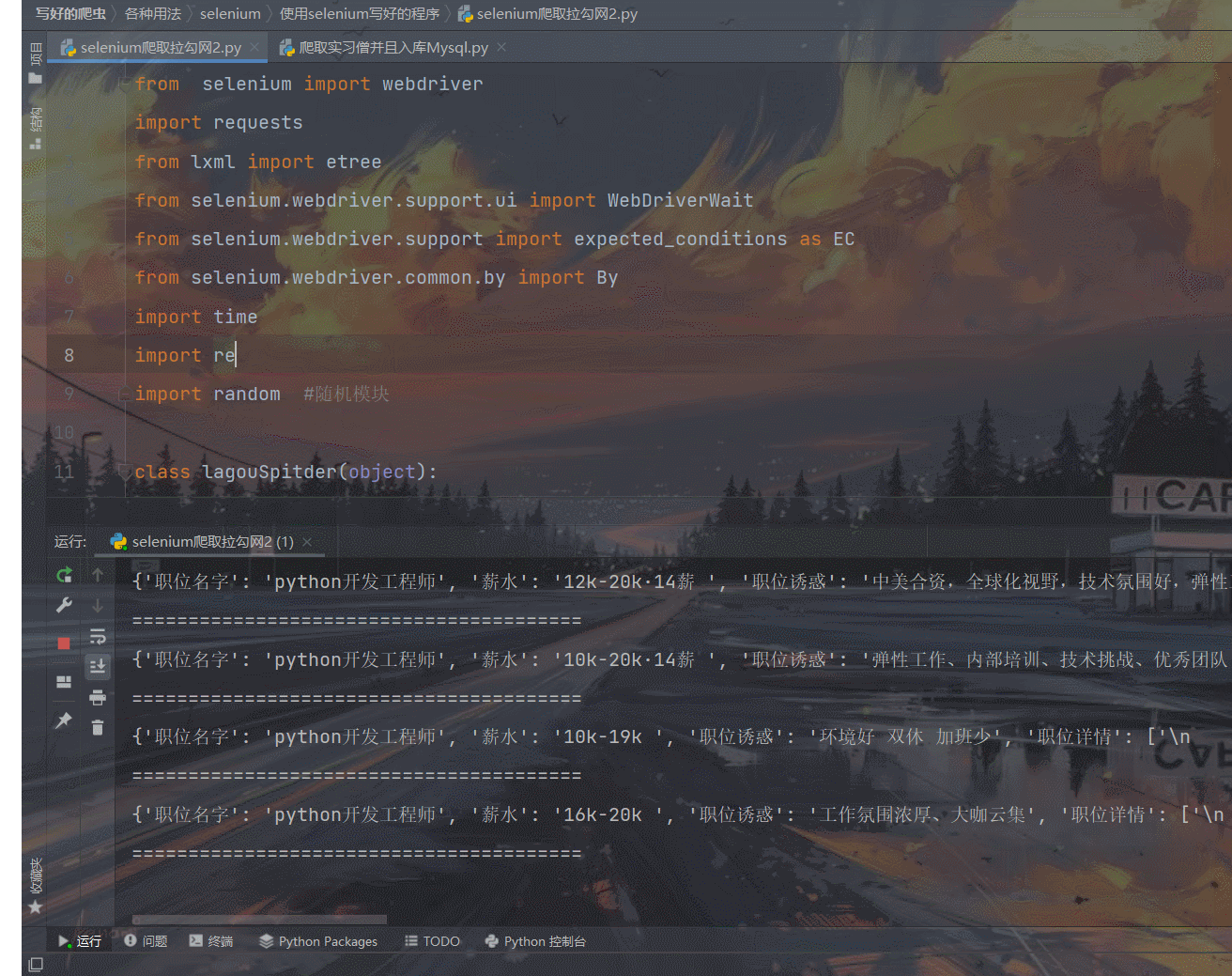
全部源代码如下:
from selenium import webdriver
import requests
from lxml import etree
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import re
import random #随机模块class lagouSpitder(object):option = webdriver.ChromeOptions()option.add_experimental_option('useAutomationExtension', False)option.add_experimental_option('excludeSwitches', ['enable-automation'])driver_path = r'驱动路径' # 定义好路径def __init__(self):self.driver=webdriver.Chrome(executable_path=lagouSpitder.driver_path,options=lagouSpitder.option)#初始化路径+规避检测selenium框架self. driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})self.url='https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='self.positions=[]def run(self): #主页面self.driver.get(self.url) #去请求主页面while True:source = self.driver.page_source # source页面来源 先获取一页WebDriverWait(driver=self.driver,timeout=10).until(EC.presence_of_element_located((By.XPATH,'//span[@action="next"]'))) #等待按钮加载出来,避免没加载出来就点击导致的报错self.parse_list_page(source) # 解析完获取的这一页职位之后,去点击下一页next_btn = self.driver.find_element_by_xpath('//span[@action="next"]')#下一页的元素位置if "pager_next pager_next_disabled" in next_btn.get_attribute('class'): # 如果class等于最后一页则停止,否则继续点击breakelse:next_btn.click() #点击下一页time.sleep(1)def parse_list_page(self,source): #获取职位详情页urlhtml=etree.HTML(source)links=html.xpath('//a[@class="position_link"]/@href')for link in links: #循环去解析详情页self.request_detall_page(link)time.sleep(random.uniform(1, 3))#随机暂停def request_detall_page(self,url): #去请求细节页面# self.driver.get(url)self.driver.execute_script("window.open('%s')"%url) #新打开一个职位页面self.driver.switch_to_window(self.driver.window_handles[1]) #切换到当前页面来解析,不切换的话selenium会停留在上一页source=self.driver.page_source #source页面来源self.pares_detail_page(source) #解析页面self.driver.close() #解析完关闭页面time.sleep(0.5)self.driver.switch_to_window(self.driver.window_handles[0]) #切换回主页面def pares_detail_page(self,source): #获取职位细节信息html=etree.HTML(source)Position_name=html.xpath('//span[@class="position-head-wrap-position-name"]/text()')[0] #职位名字salary=html.xpath('//span[@class="salary"]/text()')[0] #薪水Position_the_temptation=html.xpath('//dd[@class="job-advantage"]/p/text()')[0] #职位诱惑Job_description=html.xpath('//div[@class="job-detail"]//text()') #职位详情# Job_description=re.sub(r'[\s/]','',Job_description)desc=''.join(html.xpath('//div[@class="job-detail"]//text()')).strip() #拼接work_address=html.xpath('//div[@class="work_addr"]//text()')[3] #工作地址CompanyName = html.xpath('//h3[@class="fl"]/em/text()')[0] # 公司名字Company_Basic_Information=html.xpath('//li/h4/text()') #公司基本信息position={'职位名字':Position_name,'薪水':salary,'职位诱惑':Position_the_temptation,'职位详情':Job_description,'工作地址':work_address,'公司名字': CompanyName,'公司基本信息':Company_Basic_Information,}self.positions.append(position)print(position)print('='*40)if __name__ == '__main__':spider=lagouSpitder()spider.run()对了还有一件事~看完觉得可以的话点个赞吧,切莫白嫖
至此程序就全部写完啦
声明
本文仅限于做技术交流学习,请勿用作任何非法用途!

















![[android] 百度地图开发 (三).定位当前位置及getLastKnownLocation获取location总为空问题](https://img-blog.csdn.net/20150110210258956)