文章目录
- 前言
- 一、准备我们的库
- 二、数据清洗
- 三、核密度图及词云制作
- 四、完整代码
- 五、扩展
上一篇:什么你还不知道招聘信息,小唐来教你——最新2021爬取拉勾网招聘信息(一)
下一篇:没有拉!
前言
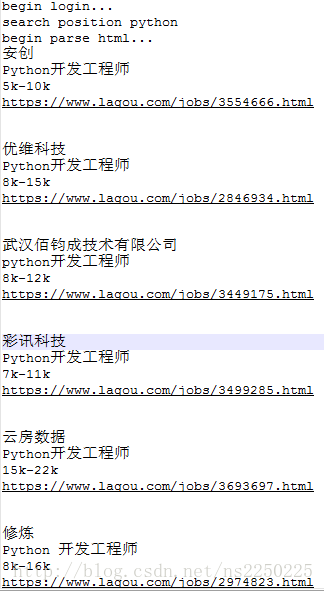
既然我们上面已经爬取到我们的数据了,这下怎么说都要对他经行一个数据分析和词云制作了吧,在这里小唐主要是就他的数据清洗和词云制作来说一下
一、准备我们的库
import pandas as pd
import re
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import cv2
#这里是为了让我们的中文可以显示出来
font = r'C:\Windows\Fonts\simfang.ttf'
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
二、数据清洗
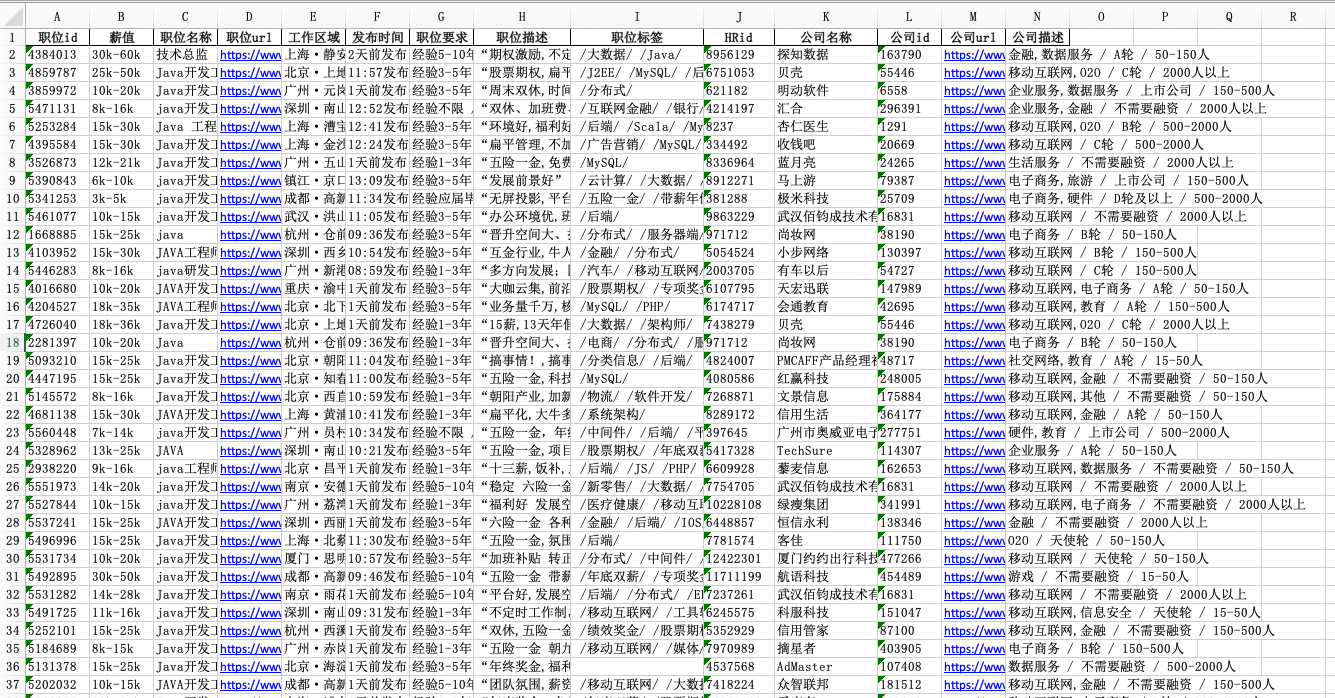
由于我们工资都是给定一个范围,所以说,我们要对他求一个平均值,在这里我们用正则表达式来识别
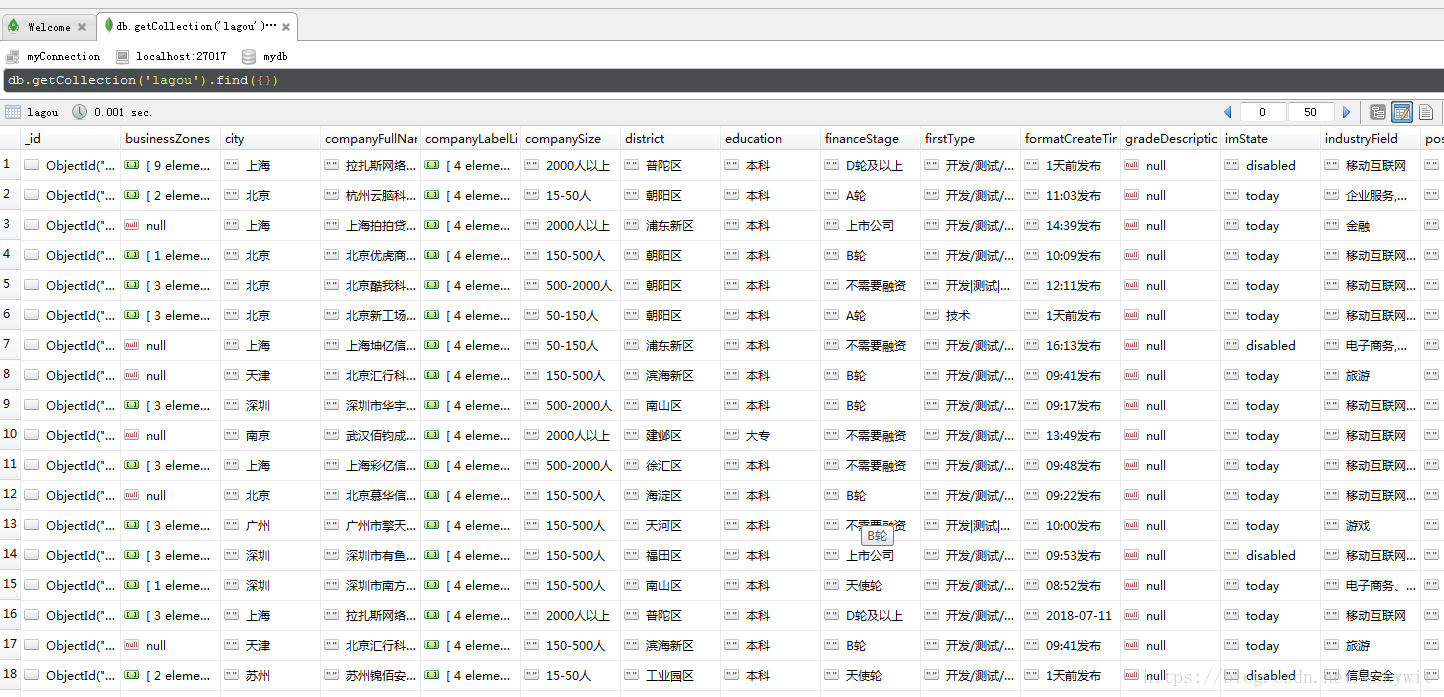
def ciyun():df = pd.read_excel('工程师.xls')#这个就是我们要分析的表for i in range(df.shape[0]):gz = df.loc[i, '工资']#选择工资那一列if re.search(r'.*k-.*k', gz):a = eval(re.search('(.*)k-(.*)k', gz).group(1)) * 1000b = eval(re.search('(.*)k-(.*)k', gz).group(2)) * 1000num = (a + b) / 2#求平均值try:df.loc[i, '工资'] = int(num)/1000except:print("跳过")df.loc[i, '工资'] =0visualization(df)#将我们洗好的数据传到我们下一个制作图表里面
三、核密度图及词云制作
def visualization(df):salarys=df['工资']for i in salarys:print(i)mean = round(salarys.mean(), 1)#求我们的平均值plt.figure(figsize=(8, 6), dpi=200)#确定下来我们的行列数sns.distplot(salarys, hist=True, kde=True, kde_kws={"color": "r", "linewidth": 1.5, 'linestyle': '-'})#画核密度图plt.axvline(mean, color='r', linestyle=":")#在中间值那里画一条红线plt.text(mean, 0.05, '平均月薪: %.1f千' % (mean), color='k', horizontalalignment='center', fontsize=15)#在红线中间输出中间值是多少plt.xlim(0, 35)plt.xlabel('月薪(单位:千)')plt.title('工程师行业的薪资分布')plt.show()a = df['需求']#这里可以更改,可以显示地区呀,需求呀的词云text = []n = 0#统计词频for i in a:text.append(i)n += 1text = ",".join(str(i) for i in text)mask = cv2.imread(r'D:\data\timg.jpg')#这个是我们的要他形成的一个形状,没有的话可以删掉这一行,记得后面的mask也要删掉喔wordcloud = WordCloud(font_path=font, background_color="white", mask=mask).generate(text)plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.show()



四、完整代码
import pandas as pd
import re
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import cv2
font = r'C:\Windows\Fonts\simfang.ttf'
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
def ciyun():df = pd.read_excel('工程师.xls')for i in range(df.shape[0]):gz = df.loc[i, '工资']if re.search(r'.*k-.*k', gz):a = eval(re.search('(.*)k-(.*)k', gz).group(1)) * 1000b = eval(re.search('(.*)k-(.*)k', gz).group(2)) * 1000num = (a + b) / 2try:df.loc[i, '工资'] = int(num)/1000except:print("跳过")df.loc[i, '工资'] =0visualization(df)
def visualization(df):salarys=df['工资']for i in salarys:print(i)mean = round(salarys.mean(), 1)plt.figure(figsize=(8, 6), dpi=200)sns.distplot(salarys, hist=True, kde=True, kde_kws={"color": "r", "linewidth": 1.5, 'linestyle': '-'})plt.axvline(mean, color='r', linestyle=":")plt.text(mean, 0.05, '平均月薪: %.1f千' % (mean), color='k', horizontalalignment='center', fontsize=15)plt.xlim(0, 35)plt.xlabel('月薪(单位:千)')plt.title('工程师行业的薪资分布')plt.show()a = df['需求']text = []n = 0for i in a:text.append(i)n += 1text = ",".join(str(i) for i in text)wordcloud = WordCloud(font_path=font, background_color="white").generate(text)plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.show()ciyun()五、扩展
什么!居然还可以扩展!咱就是说小唐去做了一个界面,有需要的可以直接私信小唐,然后发你源码喔!
震惊,某高校男子考前考打代码复习四六级 网络爬虫真好玩