众所周知,拉勾网的反爬机制一直做的很好,前些年还可以通过找到网页源代码找到岗位详情页面的地址,而现在拉勾网的详情页面地址直接没了,这就很奇怪,那么鼠标点击他又是如何跳转到别的页面

点开源代码中,每一个职位都包含在<div class="item__10RTO">,但就是没有对应的地址信息,但我们点开每个岗位信息可以看到,地址中唯一有变化的就是html前面的数字。

所以现在的问题是找到前面的数字存在了什么地方,直接搜索:


点开第一个,这里有个key值为positionId,猜测可能所有岗位详情页面都有一个对应的positionId,只要找到每一个对应的id就可以自己构造url,访问到详情页面。
拉勾网把具体网页地址的id放在了网页源代码底下的script标签中,把他们复制出来,查看一下是是否是json数据:

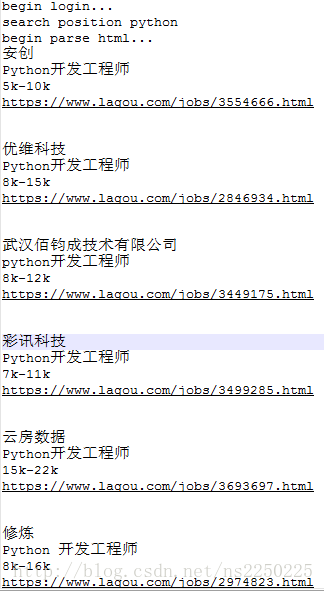
果然是json形式的数据(如果直接在网页源代码中查看这部分数据,会发现到了最后面数据不全,json数据识别不出来,所以我是直接用让代码去拿去网页的数据,就可以看到全部的json数据)
测试代码如下:
import requests
from selenium import webdriver
import re
from lxml import etree
import jsonurl = "https://www.lagou.com/wn/jobs?pn=1&cl=false&fromSearch=true&kd=python"
url_temp = "https://www.lagou.com/wn/jobs/{}.html"
drivers = webdriver.Chrome()
drivers.get(url)
html_str = drivers.page_source
html = etree.HTML(html_str)
json_str = html.xpath("//script[@id='__NEXT_DATA__']/text()")[0]
json_dict = json.loads(json_str)
list = []
for i in range(15): # 每次页面有15个岗位信息positionId = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]["positionId"]print(url_temp.format(positionId))list.append(url_temp.format(positionId))
drivers.get(list[2]) # 测试一下构造的网页是否有效最后测试了一下构造的网页是否有效,可以正常访问。

证明可以成功访问到!