最近爬取拉勾网上的公司信息碰到了很多问题,但是都一一解决了。作为一个招聘网站,他的反爬措施做的还是很好的。
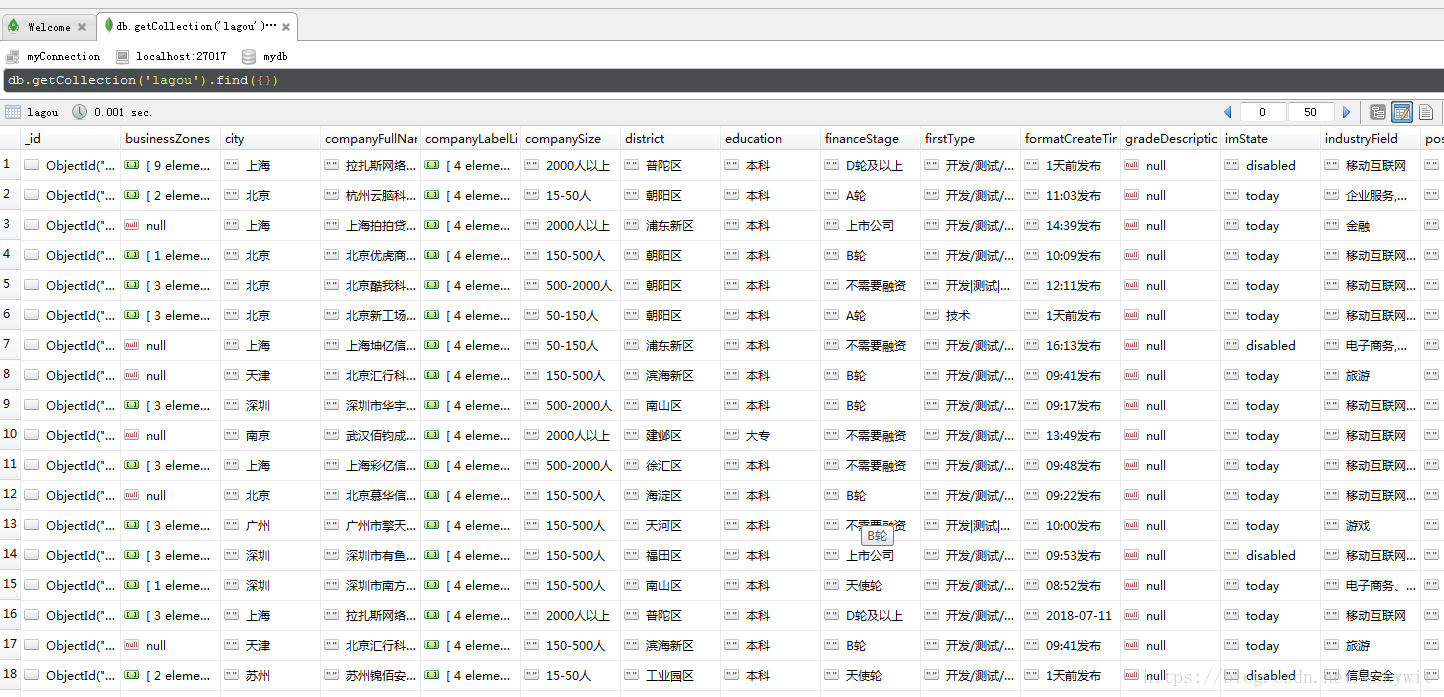
为了调查招聘网站上有多少公司,以及公司信息,并把公司信息存入MongoDB数据库中。
先上运行成功代码:
import requests
import json,time,random
import pymongo
from lxml import etree #导入需要用到的库文件client=pymongo.MongoClient('localhost',27017)
test=client['info_company']
lagou=test['lagou'] #连接数据库def gongsi_info(url): #定义获取公司信息的函数for pn in range(2,31):params={'first':'false','pn':str(pn),'sortField':'0','havemark':'0'} #post请求参数try:with open('已下载页面.txt','r',)as f: #如果存在该文件,就打开并读取内容,否则就创建该文件t=f.readlines()if str(pn)+'\n' in t:print('第'+str(pn)+'页已经爬取过了')else: urls='https://www.lagou.com/gongsi/'s = requests.Session()s.get(urls, headers=headers, timeout=3) # 请求首页获取cookiescookie = s.cookies # 为此次获取的cookiesprint(cookie)response = s.post(url, data=params, headers=headers, cookies=cookie, timeout=5) # 获取此次文本
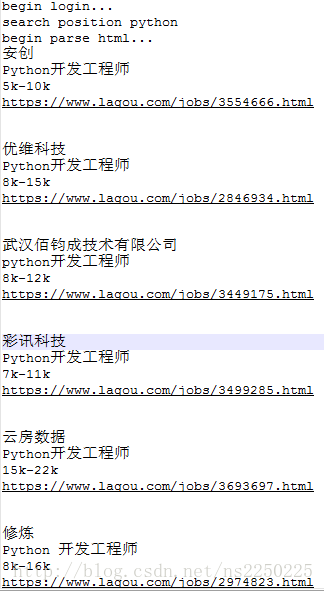
# time.sleep(3)response.encoding = response.apparent_encodingjson_data = json.loads(response.text)print(json_data['pageNo'])print(json_data['totalCount'])results=json_data['result']for result in results:infos={'公司简称':result['companyShortName'],'公司城市':result['city'],'公司全名':result['companyFullName'],'公司特色':result['companyFeatures'] if 'companyFeatures' in result else '','专注行业':result['industryField'],'公司规模':result['companySize'],'融资阶段':result['financeStage'],'面试评价数':result['interviewRemarkNum'],'在招职位':result['positionNum'],'简历处理率':result['processRate']}lagou.insert_one(infos) #将数据插入数据库ti=10+random.random() #设置间隔时间,防止被服务器屏蔽time.sleep(ti)with open('已下载页面.txt','a+')as f: #将已经下载过的页面保存在txt文件中f.write(str(pn)+'\n')f.close()except requests.exceptions.ConnectionError:pass
if __name__=='__main__':url='https://www.lagou.com/gongsi/0-0-0-0.json'headers = {'Accept': 'application/json, text/javascript, */*; q=0.01','Referer': 'https://www.lagou.com/gongsi/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}gongsi_info(url)print('finished!!')
拉勾网结合了异步加载技术和提交表单,通过逆向工程爬取公司信息。
一开始的思路是:拉勾网在登录后才能拿到数据,因此需要在headers中带上cookie模拟登陆。结果发现在浏览器端能获得数据,但是程序一运行就返回:
'status': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '1120.229.134.196', 'state': 2402}
去网上又找了类似问题的解决方法,觉得应该是post表单少了参数导致的,因此我把f12中看到的headers参数全部带上,接着尝试运行程序,结果还是一样。
直到看到一篇文章说cookie的问题,上面说到cookie时间戳的问题,于是我去拉勾网看了一下发现这个:

这说明cookie中带有时间戳就是问题所在:一次性,在开发者工具中复制的cookie不能重复使用(其他网站的可以)。直到问题所在,接下来只要解决cookie问题就可以了。

这几行代码就解决了这个问题。解决灵感来自于博客,发现每次的cookie都不一样,至于更深层次的原因,暂不清楚,等后面接触服务器再来更新。