一、简介
网址:https://www.lagou.com/jobs/list_/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=
效果:信息
使用框架:requests
难度系数:✩✩✩
二、教程
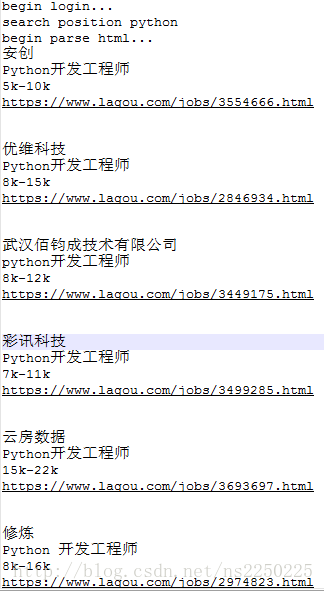
今天我们要为我们的工作写爬虫!我们今天的目标是互联网行业的招聘网——拉勾网。
1. 网站分析
这一次我们使用上一篇教程所学习得接口爬取法,接口爬取法将是我们后面用的最主要的方法。
打开浏览器调试界面,经过一番分析与查找,我们发现了职位信息所在的接口:
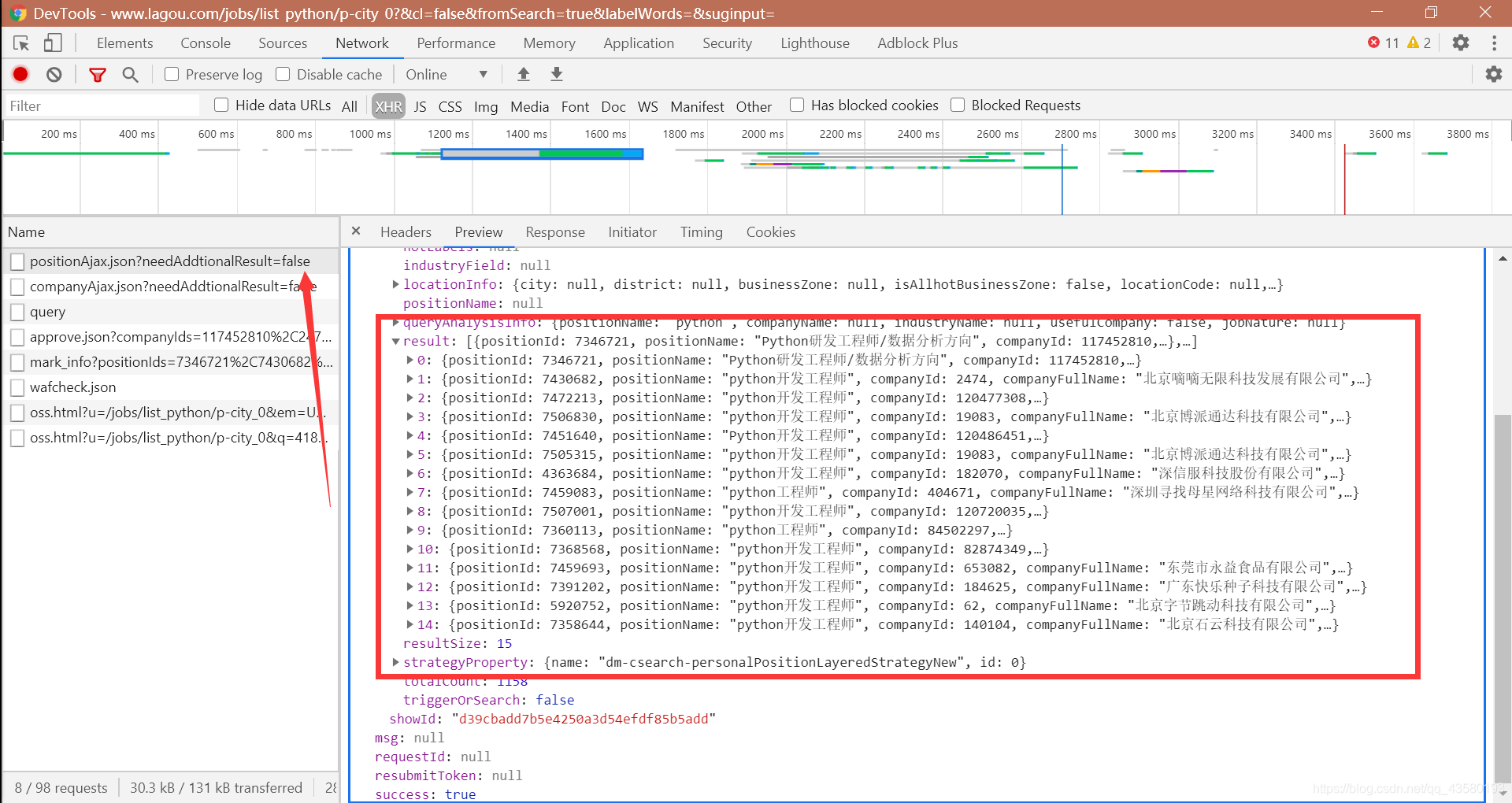
下一步查看接口链接与请求方式:
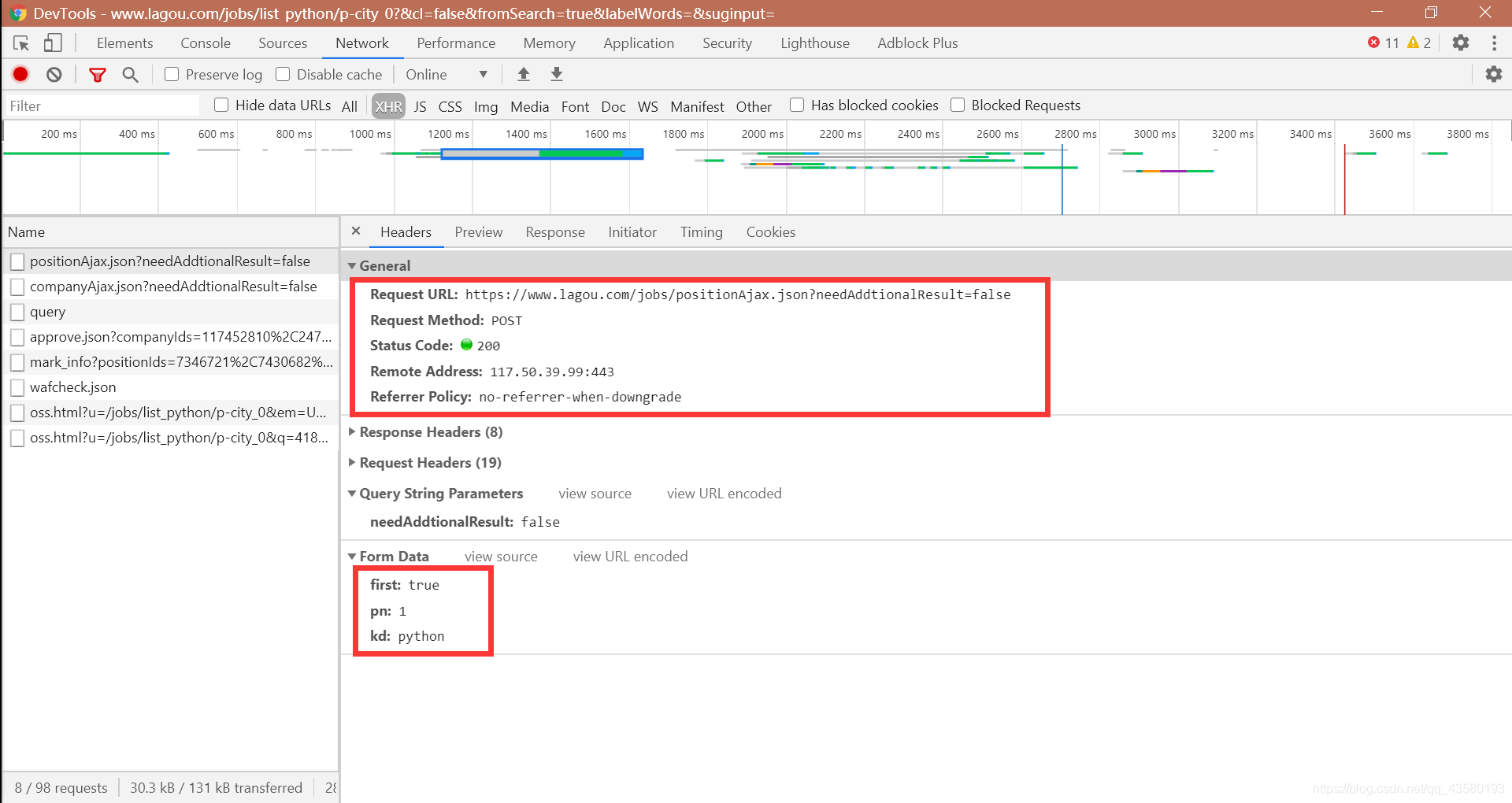
我们发现该请求的请求方式为 POST(不了解 post 的请进传送门),经过几次尝试发现下面提交的数据分别有以下几个含义:
- first:请求的是否是第一页
- pn:请求页码
- kd:搜索关键词
2. 爬虫构造
了解请求方式之后我们就可以进行爬虫的构造了:
import requestsurl = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",'Referer': 'https://www.lagou.com/jobs/list_/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
}
data = {'first': 'true','pn': 1,'kd': 'python'
}
resp = requests.post(url=url, data=data, headers=headers)
print(resp.text)
然鹅事情出乎了我们的意料,因为返回结果是这个样样的:
{"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"222.73.153.43","state":2402}
这么明显的提示。。。我们这只小小的爬虫已经被人发现了。。。
不行,我就不相信今天还搞不了你了!
观察请求参数,构造和浏览器访问一样的参数:
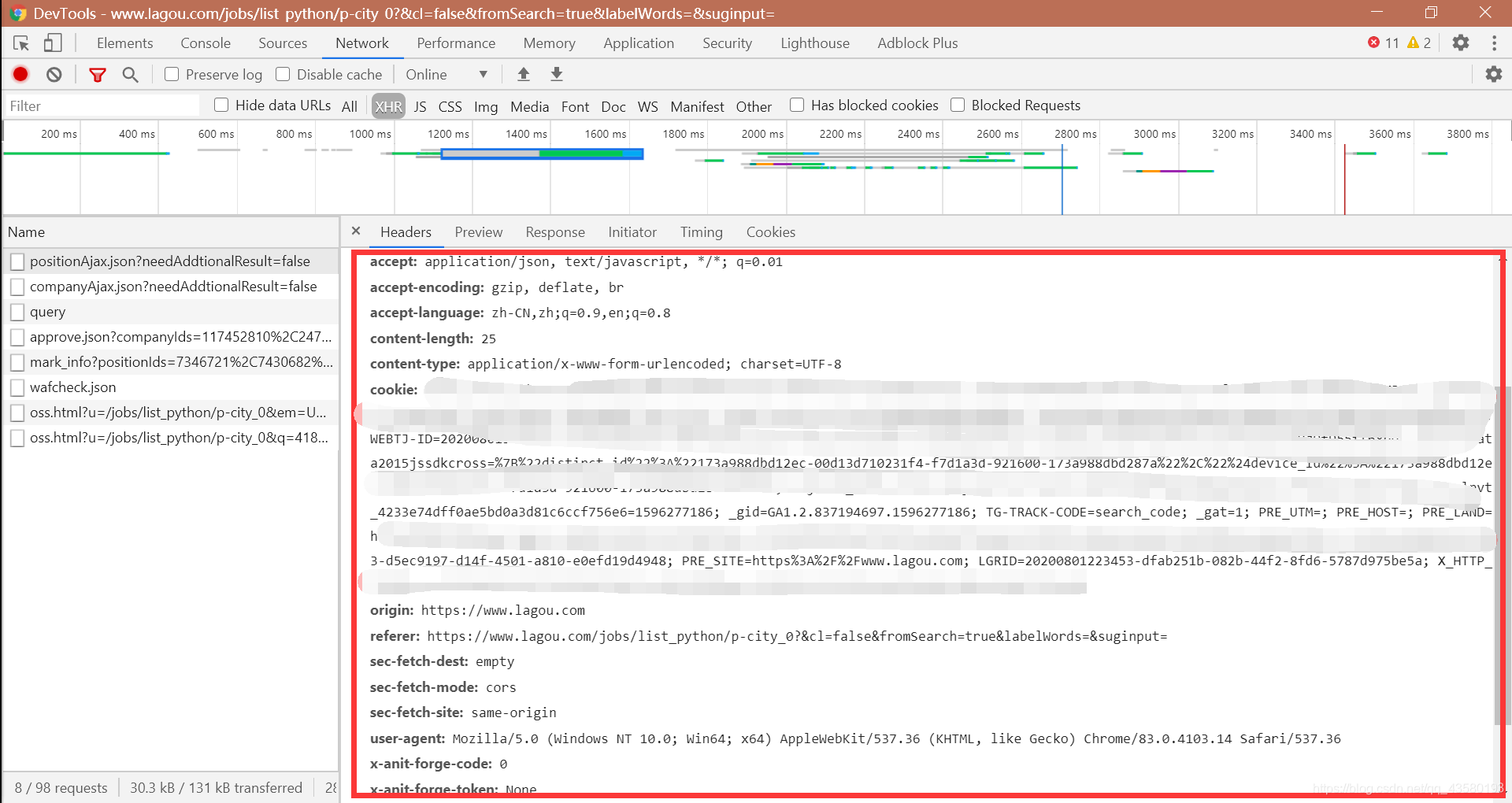
经过多次实验,终于发现造成这样结果的原因是我们没有加 cookie(不了解的请进传送门),但是我们又不能每一次都去手动添加 cookie 啊,这是 “人工智能” 啊!
这个时候我们的 requests 库就又站了出来,requests 库的 Session类会帮我们自动管理cookie,我们就不需要手动添加了。
爬虫 2.0:
import requests# 用于与网站建立session的链接
url1 = "https://www.lagou.com/jobs/list_/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput="
# 请求数据的链接
url2 = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",'Referer': 'https://www.lagou.com/jobs/list_/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='}
data = {'first': 'true','pn': 1,'kd': 'python'}session = requests.session()
session.get(url1, headers=headers)
resp = session.post(url=url2, data=data, headers=headers)
print(resp.text)
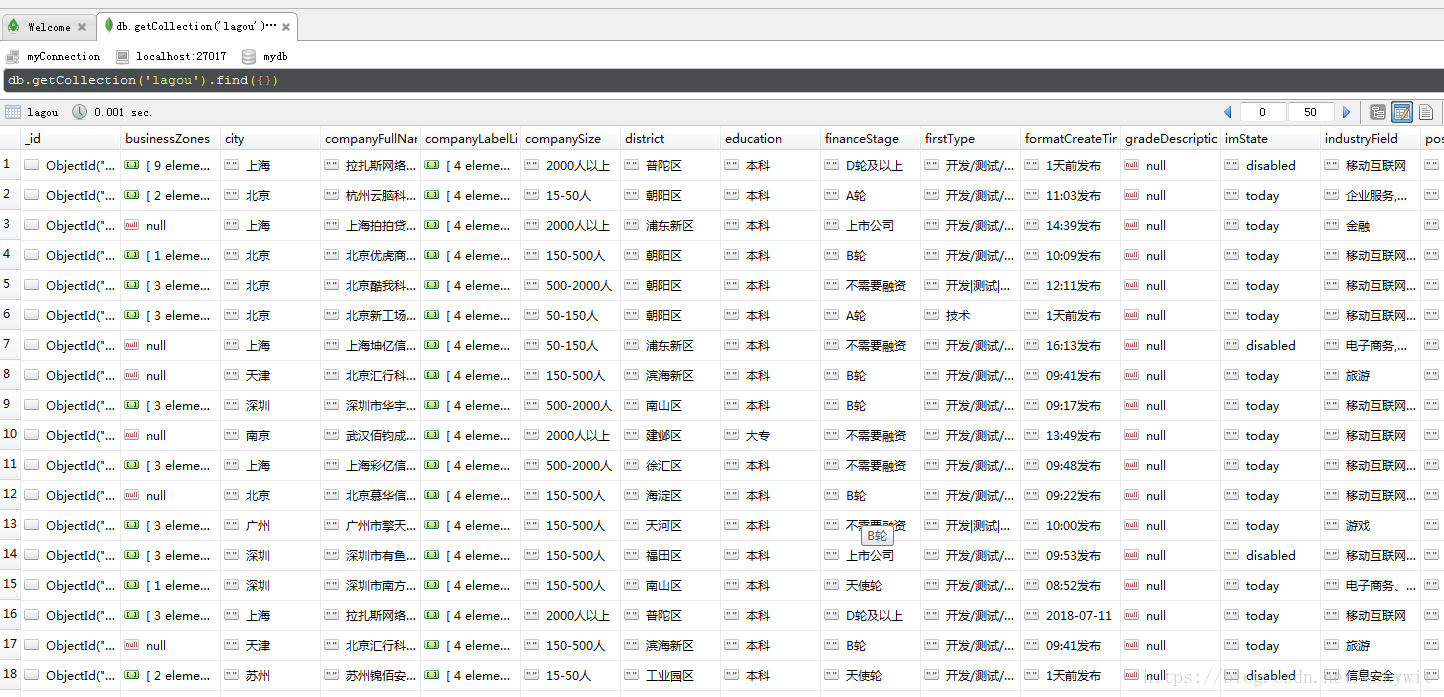
我们升级后的爬虫已经成功拿到了数据!
那么今天的教程就到此结束了,朋友们快去试一试吧!
3. 完整代码
传送门