目录
- 前期准备
- 请求头
- Cookies
- 问题
- 手动提取Cookies和自动Cookies相结合
- 自动提取Cookies实现
- 手动提取Cookies实现
- 页面分析
- 代码实现
前期准备
我们知道百度其实就是一个爬虫,但是对方的服务器是没有对百度进行反爬的,所以为了防止对方服务器的反爬,我们在爬取网站的时候要尽可能地模拟我们使用的浏览器。
请求头
headers = {'Origin': 'https://www.lagou.com','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3','Referer': 'https://www.lagou.com/utrack/trackMid.html?f=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%3Fcity%3D%25E4%25B8%258A%25E6%25B5%25B7%26cl%3Dfalse%26fromSearch%3Dtrue%26labelWords%3D%26suginput%3D','Connection': 'keep-alive','X-Anit-Forge-Token': 'None',}
Cookies
我们开始给爬虫加登录信息。
思路是这样的,我们首先获取未登录的cookies信息,然后手动获取登录之后的cookies,最后将网页的未登录的cookies来更新手动获取的cookies。
Cookies更新之前:

Cookies更新之后:

问题
为什么我们要用登录之前的Cookies来替代未登录时候的Cookies,而不是直接用登录之后的Cookies呢?
我们来进行下面的操作:
我们用python获取未登录之前的Cookies,代码如下:
r = requests.utils.dict_from_cookiejar(response.cookies) # 获取未登录之前的cookies,并将其保存为字典形式
得到Cookies为:
{'X_HTTP_TOKEN': '42daf4b72327b2815391767951bf5e71415983ed09', 'user_trace_token': '20200817214535-246f31d4-af7a-4789-91aa-8b78a9968cc2', 'JSESSIONID': 'ABAAABAABAGABFA4667C48E469AC7C13D950817DEE99E9E', 'SEARCH_ID': 'bcce59f10c2f47e092507fc45937b092'}
而登录之后的Cookies如下图:
 其中所包含的键值对比未登录之前的Cookies要多,如果我们用手动获取的Cookies来登录,代码是这样的:
其中所包含的键值对比未登录之前的Cookies要多,如果我们用手动获取的Cookies来登录,代码是这样的:
response = requests.post('https://www.lagou.com/jobs/positionAjax.json', headers=headers, params=params,cookies=cookies, data=data) #
我们发现加了Cookies之后,还是获取不到我们想要的数据,还是会出现如下的图:

很多人到这一步如果再爬取不到数据,可能就要怀疑人生了。其实你只是有个小问题一直被你忽视了,那就是我们不能只用当前手动获取的Cookies,还是需要和程序获取的Cookies来结合。因为程序获得的Cookies是动态的,而我们手动获取的Cookies只能是静态的,所以这就导致了我们手动获取的Cookies在复制到了程序当中的时候出现了失效的情况了。
手动提取Cookies和自动Cookies相结合
通过手动提取的Cookies和程序自动Cookies相结合的方式,我们顺利爬取到了页面信息。
自动提取Cookies实现
headers = {'Origin': 'https://www.lagou.com','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3','Referer': 'https://www.lagou.com/utrack/trackMid.html?f=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%3Fcity%3D%25E4%25B8%258A%25E6%25B5%25B7%26cl%3Dfalse%26fromSearch%3Dtrue%26labelWords%3D%26suginput%3D','Connection': 'keep-alive','X-Anit-Forge-Token': 'None',}response = requests.get('https://www.lagou.com/jobs/list_?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=', ##通过首页来提取未登录的Cookiesheaders=headers)r = requests.utils.dict_from_cookiejar(response.cookies) # 获取未登录时cookies的字典形式
手动提取Cookies实现
cookies = {'X_MIDDLE_TOKEN': 'b378b95e10365bf661d07c4677d0796b','JSESSIONID': 'ABAAAECABIEACCA21A19A7E6AC502D30F9E0C895A9D728F','_ga': 'GA1.2.2029710160.1597402404','_gat': '1','Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1597402405','user_trace_token': '20200814185324-964f6276-b305-42bc-ace0-b2d9281183be','LGSID': '20200817212759-d10cedcc-a8bf-4217-be81-dd076a492bef','PRE_UTM': '','PRE_HOST': '','PRE_SITE': '','PRE_LAND': 'https%3A%2F%2Fwww.lagou.com%2F%3F_from_mid%3D1','LGUID': '20200814185325-2014f63b-09d9-4803-bbe1-88d52f7e09be','_gid': 'GA1.2.1977632940.1597402405','index_location_city': '%E4%B8%8A%E6%B5%B7','TG-TRACK-CODE': 'index_hotjob','LGRID': '20200814192428-6a6ac31c-af6b-4a6f-8310-1710a2b061a4','Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1597404269','SEARCH_ID': '50341c0aa78d427cb85b609ca8a00308','X_HTTP_TOKEN':'42daf4b72327b2819780767951bf5e71415983ed09'}
页面分析
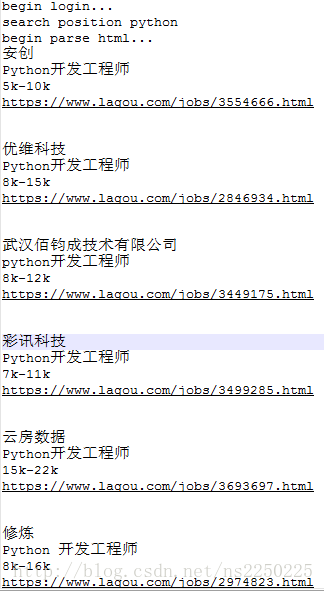
首先我们对拉勾网的网站进行分析,找到数据是在哪个api接口下。这里重点找一个带json的文本信息链接,如下图所示:

其次,构造参数;我们发现浏览器请求的链接是:
https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false
我们直接访问这个网址,是得不到任何数据的,我们还需要给链接构造参数:
 这里有三个参数,通过对比分析得到first为true时为第一页,pn代表了第几页,kd代表搜索关键词。
这里有三个参数,通过对比分析得到first为true时为第一页,pn代表了第几页,kd代表搜索关键词。
cookies = {'X_MIDDLE_TOKEN': 'b378b95e10365bf661d07c4677d0796b','JSESSIONID': 'ABAAAECABIEACCA21A19A7E6AC502D30F9E0C895A9D728F','_ga': 'GA1.2.2029710160.1597402404','_gat': '1','Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1597402405','user_trace_token': '20200814185324-964f6276-b305-42bc-ace0-b2d9281183be','LGSID': '20200817212759-d10cedcc-a8bf-4217-be81-dd076a492bef','PRE_UTM': '','PRE_HOST': '','PRE_SITE': '','PRE_LAND': 'https%3A%2F%2Fwww.lagou.com%2F%3F_from_mid%3D1','LGUID': '20200814185325-2014f63b-09d9-4803-bbe1-88d52f7e09be','_gid': 'GA1.2.1977632940.1597402405','index_location_city': '%E4%B8%8A%E6%B5%B7','TG-TRACK-CODE': 'index_hotjob','LGRID': '20200814192428-6a6ac31c-af6b-4a6f-8310-1710a2b061a4','Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1597404269','SEARCH_ID': '50341c0aa78d427cb85b609ca8a00308','X_HTTP_TOKEN':'42daf4b72327b2819780767951bf5e71415983ed09'}'''参数的解释放在后面
params = (('px', 'default'),('city',city),('needAddtionalResult', 'false'),)
data = {"first":"true", 'kd': '数据分析','pn': pn}if pn>1:data["first"] = "false"
代码运行时候需要取消注释'''
response = requests.post('https://www.lagou.com/jobs/positionAjax.json', headers=headers, params=params,data=data) # 请求接口
于是乎我们开始访问,却得到了这样的链接,等等,我们刚不是已经将参数构造完成了吗?为什么还是出现这样的情况?
我们考虑可能是没有带cookies访问,我们开始尝试加Cookies,这里回到上一节的Cookies。
尝试加了Cookies之后对页面爬取,代码如下:
response = requests.post('https://www.lagou.com/jobs/positionAjax.json', headers=headers, params=params,cookies=cookies, data=data) return response.json()
顺利输出:

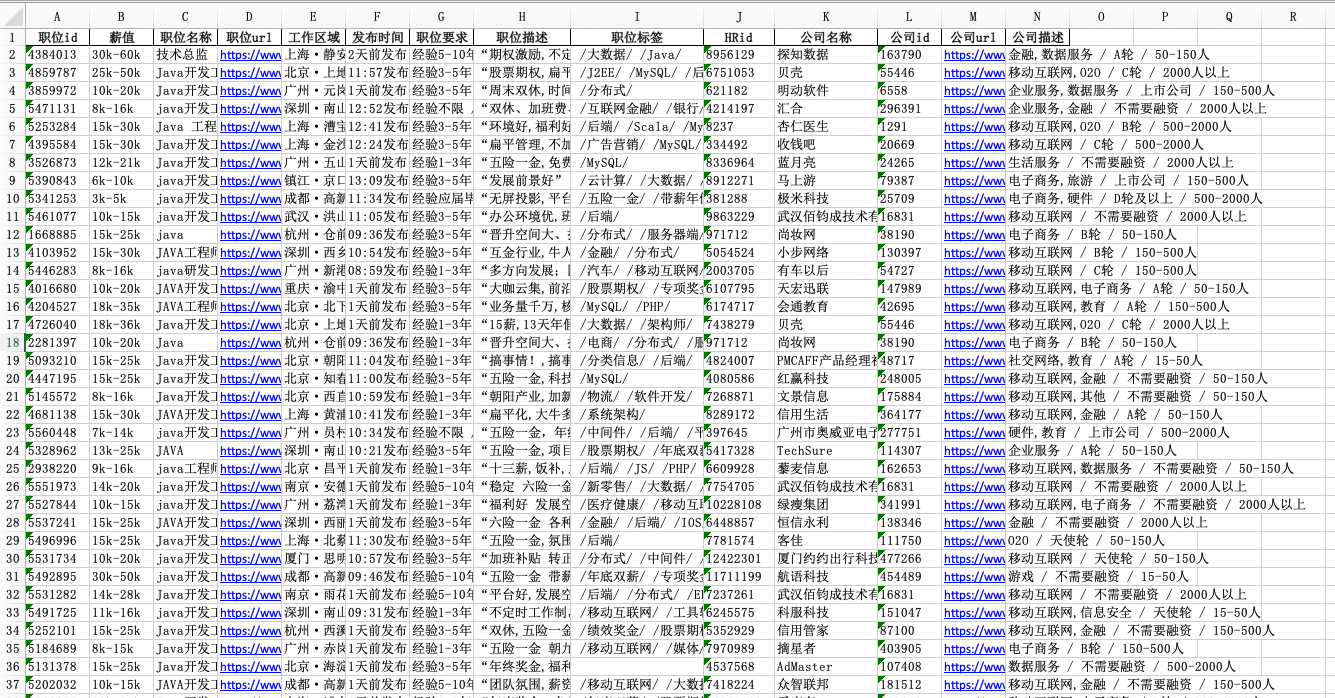
但是这里的数据没有结构化显示出来,所以我们需要使用以下代码来获得结构化数据:
response_json = json.dumps(response_json,indent=4,ensure_ascii=False)

通过字典形式来获取我们想要的数据:
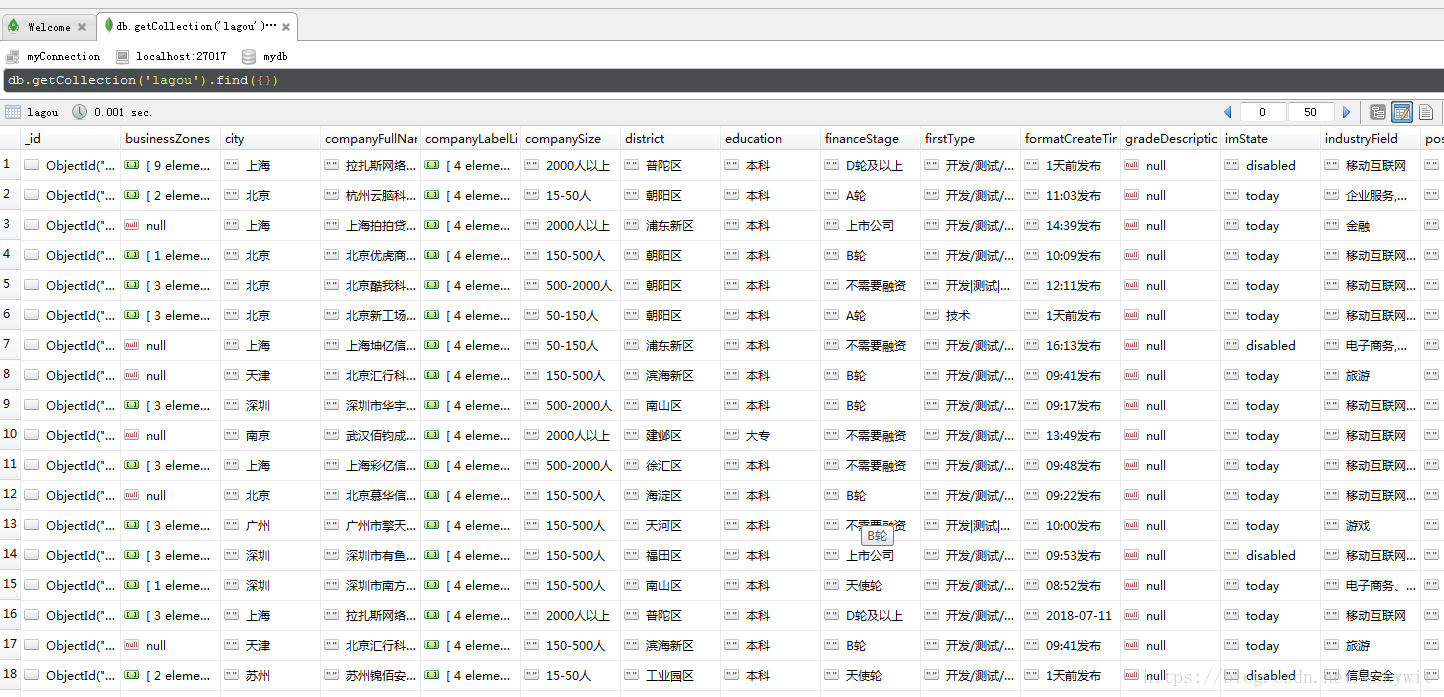
position_list = response_json["content"][ 'positionResult']["result"]

至此,我们就完成了页面的分析
代码实现
import json
import random
import timeimport requestsdef get_cookie():headers = {'Connection': 'keep-alive','Cache-Control': 'max-age=0','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}response = requests.get('https://www.lagou.com/jobs/list_?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=',headers=headers) # 请求原网页r = requests.utils.dict_from_cookiejar(response.cookies) # 获取cookiesprint(r)cookies = {'X_MIDDLE_TOKEN': 'b378b95e10365bf661d07c4677d0796b','JSESSIONID': 'ABAAAECABIEACCA21A19A7E6AC502D30F9E0C895A9D728F','_ga': 'GA1.2.2029710160.1597402404','_gat': '1','Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1597402405','user_trace_token': '20200814185324-964f6276-b305-42bc-ace0-b2d9281183be','LGSID': '20200817212759-d10cedcc-a8bf-4217-be81-dd076a492bef','PRE_UTM': '','PRE_HOST': '','PRE_SITE': '','PRE_LAND': 'https%3A%2F%2Fwww.lagou.com%2F%3F_from_mid%3D1','LGUID': '20200814185325-2014f63b-09d9-4803-bbe1-88d52f7e09be','_gid': 'GA1.2.1977632940.1597402405','index_location_city': '%E4%B8%8A%E6%B5%B7','TG-TRACK-CODE': 'index_hotjob','LGRID': '20200814192428-6a6ac31c-af6b-4a6f-8310-1710a2b061a4','Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6': '1597404269','SEARCH_ID': '50341c0aa78d427cb85b609ca8a00308','X_HTTP_TOKEN':'42daf4b72327b2819780767951bf5e71415983ed09'}cookies.update(r) # 更新接口的cookies #以r为准print(cookies) return cookiesdef crawl(city = "", pn = 1, cookies = None):headers = {'Origin': 'https://www.lagou.com','X-Anit-Forge-Code': '0','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Accept': 'application/json, text/javascript, */*; q=0.01','Referer': 'https://www.lagou.com/jobs/list_java?px=new&city=%E4%B8%8A%E6%B5%B7','X-Requested-With': 'XMLHttpRequest','Connection': 'keep-alive','X-Anit-Forge-Token': 'None',}params = (('px', 'default'),('city',city),('needAddtionalResult', 'false'),)data = {"first":"true",'kd': '数据分析','pn': pn}if pn>1:data["first"] = "false"response = requests.post('https://www.lagou.com/jobs/positionAjax.json', headers=headers, params=params,cookies=cookies, data=data) # 请求接口return response.json()
city_list = ["北京","上海","深圳","广州","杭州","成都","南京","武汉","西安","厦门","长沙","苏州","天津"]for city in city_list:print("*"*60)print("{city} start".format(city=city))for i in range(1,31):if (i-1)%5==0:cookies = get_cookie() ##因为Cookies是有时效性的,每隔一段时间Cookies就会动态地发生变化time.sleep(random.random()+random.randint(1,2)) ##很重要!!加随机时间防止反爬response_json = crawl(city=city,pn=i,cookies=cookies) ##pn是第几页time.sleep(1.2)# response_json = json.dumps(response_json,indent=4,ensure_ascii=False)# print('response_json',response_json) ##输出结构化数据try:position_list = response_json["content"][ 'positionResult']["result"]print(position_list)except:print(response_json)if len(position_list)<1:print("{city} start".format(city=city))print("*"*60)breakprint("{city} end".format(city=city))print("*"*60)
至此,我们就完成了对拉勾网数据的爬取了,需要注意的有以下几点:
- 在爬取网页之前要尽可能让你的爬虫伪装成浏览器的访问。这里加了Cookies和Headers。
- 在批量爬取时候要加随机时间,特别重要!!!
- Cookies是有时效的,切忌将手动提取的登陆之后的Cookies来替代未登陆时的Cookies。
小贴士:根据经验来看,网页的数据一般是在json链接中,所以我们一般情况下重点关注带json的链接信息。
至此,我们的数据爬取任务就完成了,后面会专门写一个清洗和写入数据库,以及通过爬取的数据来分析就业的文章,有需要的可以继续关注别的博客。
如有转载请注明出处!!!