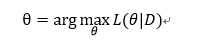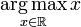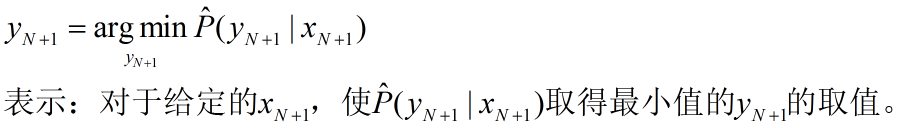文章目录
- 相关介绍
- SGD: Stochastic Gradient Descent
- TG
- 简单加入L1范数
- 简单截断法
- 梯度截断法
- FOBOS: Forward Backward Splitting[^4]
- RDA: Regularized dual averaging[^5]
- FTRL: Follow-the-Regularized-Leader
- 总结
相关介绍
SGD: Stochastic Gradient Descent
由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。 与SGD比较,GD需要每次扫描所有的样本以计算一个全局梯度,SGD则每次只针对一个观测到的样本进行更新。通常情况下SGD可以更快的逼近最优值,而且SGD每次更新只需要一个样本,使得它很适合进行增量或者在线计算(也就是所谓的Online learning)。权重更新方式如下:
Δ ω t = − η g t \Delta {\omega_t} = - \eta {g_t} Δωt=−ηgt
ω t + 1 = ω t + Δ ω t {\omega_{t + 1}} = {\omega_t} + \Delta {\omega_t} ωt+1=ωt+Δωt
特别的,迭代和选取模型的时候我们经常希望得到更加稀疏的模型,这不仅仅起到了特征选择的作用,也降低了预测计算的复杂度。在实际使用LR的时候我们会使用L1或者L2正则,避免模型过拟合和增加模型的鲁棒性。在GD算法下,L1正则化通常能得到更加稀疏的解;可是在SGD算法下模型迭代并不是沿着全局梯度下降,而是沿着某个样本的梯度进行下降,这样即使是L1正则也不一定能得到稀疏解1。
TG
简单加入L1范数
如上所说,在GD算法下,L1正则化通常能得到更加稀疏的解;可是在SGD算法下模型迭代并不是沿着全局梯度下降,而是沿着某个样本的梯度进行下降,这样即使是L1正则也不一定能得到稀疏解。a+b两个float数很难绝对等于零,无法产生真正稀疏的特征权重。权重更新方式如下:
Δ ω t = − g t − λ s g n ( ω t ) \Delta {\omega _t} = - {g_t} - \lambda {\mathop{\rm sgn}} ({\omega _t}) Δωt=−gt−λsgn(ωt)
ω t + 1 = ω t + η Δ ω t {\omega _{t + 1}} = {\omega _t} + \eta \Delta {\omega _t} ωt+1=ωt+ηΔωt
简单截断法
既然L1正则化在Online模式下也不能产生更好的稀疏性,而稀疏性对于高维特征向量以及大数据集又特别的重要,我们应该如何处理的呢?
简单粗暴的方法是设置一个阀值,当W的某纬度的系数小于这个阀值的时候,将其直接设置为0。这样我们就得到了简单截断法。简单截断法以 k k k为窗口,当 t k {t \over k} kt不为整数时采用标准的SGD进行迭代,当 t k {t \over k} kt为整数时,权重更新方式如下:
ω t + 1 = T 0 ( ω t + η Δ ω t , θ ) {\omega _{t + 1}} = {T_0}({\omega _t} + \eta \Delta {\omega _t},\theta ) ωt+1=T0(ωt+ηΔωt,θ)
T 0 ( v i , θ ) = { 0 , i f ∣ v i ∣ ≤ 0 v i , o t h e r w i s e {T_0}({v_i},\theta )=\left\{\begin{array}{cc} 0, & {if \quad|{v_i}| \le 0}\\ {{v_i}}, & otherwise \end{array}\right. T0(vi,θ)={0,vi,if∣vi∣≤0otherwise
θ \theta θ为一正数, v i v_i vi为一向量。
梯度截断法
简单截断法法简单且易于理解,但是在实际训练过程中的某一步, ω \omega ω的某个特征系数可能因为该特征训练不足引起的,简单的截断过于简单粗暴(too aggresive),会造成该特征的缺失。那么我们有没有其他的方法,使得权重的归零和截断处理稍微温柔一些呢?那就是梯度截断法。
ω t + 1 = T 0 ( ω t + η ∇ L ( ω t ) , η g i , θ ) {\omega _{t + 1}} = {T_0}({\omega _t} + \eta \nabla L({\omega _t}),\eta {g_i},\theta ) ωt+1=T0(ωt+η∇L(ωt),ηgi,θ)
T 1 ( v i , α , θ ) = { max ( 0 , v i − α ) , i f v i ∈ [ 0 , θ ] min ( 0 , v i + α ) , i f v i ∈ [ − θ , 0 ] v i , o t h e r w i s e (1) {T_1}({v_i},\alpha ,\theta )=\left\{\begin{array}{cc} \max (0,{v_i} - \alpha ),&{\rm{ }}if\quad {v_i} \in [0,\theta ]\\ \min (0,{v_i} + \alpha ),&{\rm{ }}if\quad {v_i} \in [ - \theta ,0]\\ {v_i}, & otherwise \end{array}\right.\tag1 T1(vi,α,θ)=⎩⎨⎧max(0,vi−α),min(0,vi+α),vi,ifvi∈[0,θ]ifvi∈[−θ,0]otherwise(1)
同样的梯度截断法也是以 k k k为窗口,每 k k k步进行一次截断。当 t k {t \over k} kt不为整数时,当 t k {t \over k} kt为整数时 g i = k g {g_i}=kg gi=kg。从Eq.(1)可以看出 g g g和 θ \theta θ决定了截断的区域,也决定了 ω \omega ω的稀疏程度。这两个数值越大,截断区域越大,稀疏性也越强。尤其这两个值相等的时候,只需要调节一个参数就能控制稀疏性。
FOBOS: Forward Backward Splitting2
FOBOS将每一个数据的迭代过程,分解成一个经验损失梯度下降迭代Eq.(1)和一个最优化问题Eq.(2)。分解出的最优化问题Eq.(2),有两项:第一项l2范数表示不能离第一步loss损失迭代结果太远,第二项是正则化项,用来限定模型复杂度抑制过拟合和做稀疏化等3。
ω t + 1 2 = ω t − η t g t f (1) {\omega _{t + {1 \over 2}}} = {\omega _t} - {\eta _t}{g_t}^f\tag1 ωt+21=ωt−ηtgtf(1)
ω t + 1 = arg min ω { 1 2 ∥ ω − ω t + 1 2 ∥ 2 + η t + 1 2 r ( ω t ) } (2) {\omega _{t + 1}} = \mathop {\arg \min }\limits_\omega \left\{ {{1 \over 2}{{\left\| {\omega - {\omega _{t + {1 \over 2}}}} \right\|}^2} + {\eta _{t + {1 \over 2}}}r({\omega _t})} \right\}\tag2 ωt+1=ωargmin{21∥∥∥ω−ωt+21∥∥∥2+ηt+21r(ωt)}(2)
对Eq.(2)求 ω t + 1 {\omega _{t + 1}} ωt+1导数,我们可以得出一个结论: 0 0 0一定属于Eq.(2)等号右边的导数集!
0 ∈ ∂ { 1 2 ∥ ω − ω t + 1 2 ∥ 2 + η t + 1 2 ∂ r ( ω t + 1 ) } ∣ ω = ω t + 1 (3) 0 \in \partial {\left. {\left\{ {{1 \over 2}{{\left\| {\omega - {\omega _{t + {1 \over 2}}}} \right\|}^2} + {\eta _{t + {1 \over 2}}}\partial r({\omega _{t + 1}})} \right\}} \right|_{\omega = {\omega _{t + 1}}}}\tag3 0∈∂{21∥∥∥ω−ωt+21∥∥∥2+ηt+21∂r(ωt+1)}∣∣∣∣ω=ωt+1(3)
由于 ω t + 1 = ω t − η t g t f {\omega _{t + 1}} = {\omega _t} - {\eta _t}{g_t}^f ωt+1=ωt−ηtgtf,可得
0 ∈ ω t + 1 − ω t + η t g t f + η t + 1 2 ∂ r ( ω t + 1 ) (4) 0 \in {\omega _{t + 1}} - {\omega _t} + {\eta _t}{g_t}^f + {\eta _{t + \frac{1}{2}}}\partial r({\omega _{t + 1}})\tag4 0∈ωt+1−ωt+ηtgtf+ηt+21∂r(ωt+1)(4)
Eq.(4)意味着只要选择使得Eq.(3)最小的 ω t + 1 {\omega _{t + 1}} ωt+1,那么就保证可以获得向量 g t + 1 f ∈ ∂ r ( ω t + 1 ) {g_{t + 1}}^f \in \partial r({\omega _{t + 1}}) gt+1f∈∂r(ωt+1)使得:
0 = ω t + 1 − ω t + η t g t f + η t + 1 2 g t + 1 f (5) 0 = {\omega _{t + 1}} - {\omega _t} + {\eta _t}{g_t}^f + {\eta _{t + \frac{1}{2}}}{g_{t + 1}}^f\tag5 0=ωt+1−ωt+ηtgtf+ηt+21gt+1f(5)
从而将 ω t + 1 {\omega _{t + 1}} ωt+1写成:
ω t + 1 = ω t − η t g t f − η t + 1 2 g t + 1 f (6) {\omega _{t + 1}} = {\omega _t} - {\eta _t}{g_t}^f - {\eta _{t + {1 \over 2}}}{g_{t + 1}}^f\tag6 ωt+1=ωt−ηtgtf−ηt+21gt+1f(6)
最后论文中推导了带L1正则的FOBOS算法。权重更新式为:
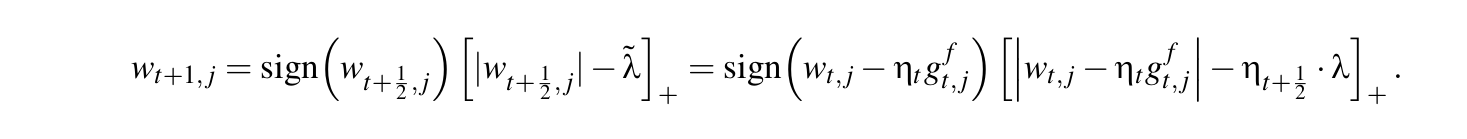
算法伪代码如下:

RDA: Regularized dual averaging4
之前的算法都是在SGD的基础上,属于梯度下降类型的方法,这类型的方法的优点是精度比较高,并且TG、FOBOS也能在稀疏性上得到提升。但是RDA却从另一个方面进行在线求解,并且有效提升了特征权重的稀疏性。
L1-RDA特征权重各个纬度更新方式为:
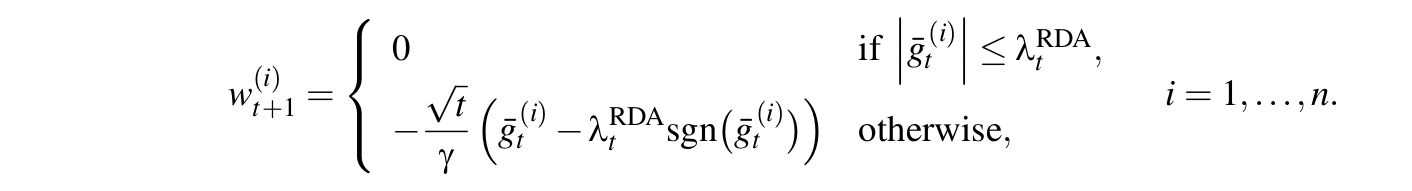
这里当某个纬度上累积梯度平均值小于阀值的时候,该纬度权重将被设置为0,特征稀疏性由此产生。
对比L1-FOBOS我们可以发现,L1-FOBOS是TG的一种特殊形式,在L1-FOBOS中,进行截断的判定条件是$|{\omega _t} - {\eta _t}{g_t}^f| \le {\lambda _{TG}} = {\eta _{t + {1 \over 2}}}\lambda 。 通 常 会 定 义 为 正 相 关 函 数 。通常会定义为正相关函数 。通常会定义为正相关函数\eta = \Theta \left( {{1 \over {\sqrt t }}} \right) 。 因 此 L 1 − F O B O S 的 截 断 阀 值 为 。因此L1-FOBOS的截断阀值为 。因此L1−FOBOS的截断阀值为\Theta \left( {{1 \over {\sqrt t }}} \right)\lambda , 随 着 ,随着 ,随着t$增加,这个阀值会逐渐降低。而相比较而言L1-RDA的截断阀值为,是一个固定的常数,因此可以认定L1-RDA比L1-FOBOS更加aggressive。此外L1-FOBOS判定是针对单次梯度计算进行判定,避免由于训练不足导致的截断问题。并且通过调节一个参数,很容易在精度和稀疏性上进行权衡。
给出其两种实现的伪代码:


FTRL: Follow-the-Regularized-Leader
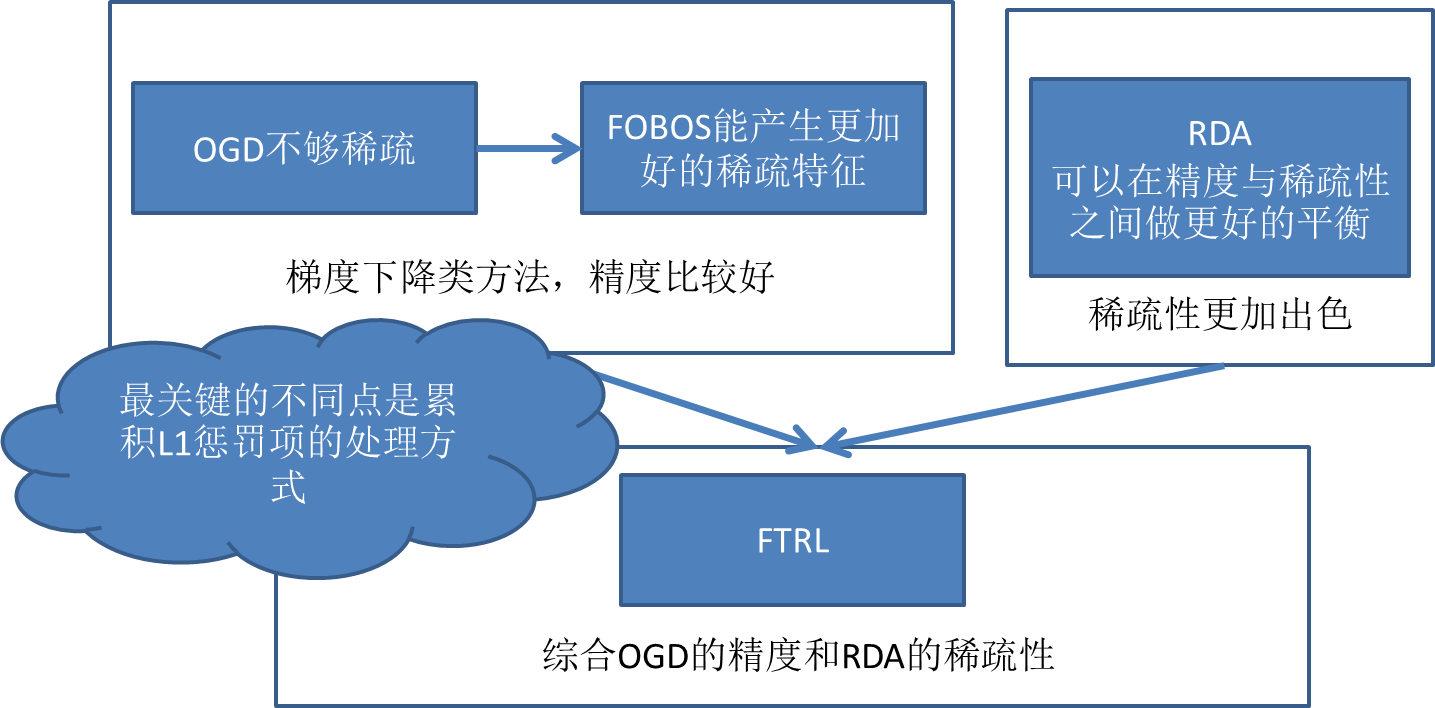
有实验证明,L1-FOBOS这一类基于梯度下降的方法有较高的精度,但是L1-RDA却能在损失一定精度的情况下产生更好的稀疏性。如何能把这两者的优点同时体现出来的呢?这就是FTRL,L1-FOBOS与L1-RDA在形式上的统一。这里有张来自引用[3]的图:
FTRL综合考虑了FOBOS和RDA对于正则项和W的限制,其特征权重为:
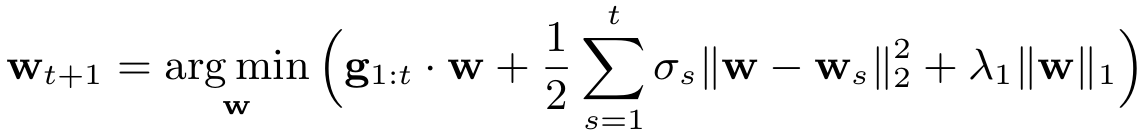
而后可导出更新式为:
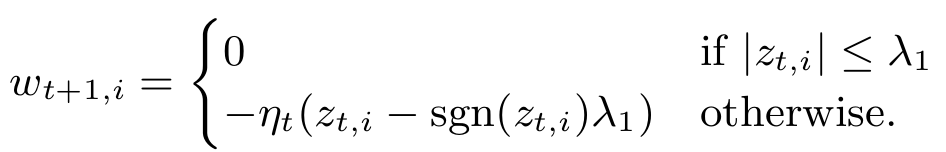
具体的变换推导,请参考2013年发表的FTRL工程化实现的论文5。
其采用L1和L2混合正则的FTRL的伪代码如下:

上面所谓的per-coordinate,其意思是FTRL是对 w w w每一维分开训练更新的,每一维使用的是不同的学习速率,也是上面代码中 λ 2 \lambda_2 λ2之前的那一项。与 w w w所有特征维度使用统一的学习速率相比,这种方法考虑了训练样本本身在不同特征上分布的不均匀性,如果包含 w w w某一个维度特征的训练样本很少,每一个样本都很珍贵,那么该特征维度对应的训练速率可以独自保持比较大的值,每来一个包含该特征的样本,就可以在该样本的梯度上前进一大步,而不需要与其他特征维度的前进步调强行保持一致。
总结
从类型上来看,简单截断法、TG、FOBOS属于同一类,都是梯度下降类的算法,并且TG在特定条件可以转换成简单截断法和FOBOS;RDA属于简单对偶平均的扩展应用;FTRL6可以视作RDA和FOBOS的结合,同时具备二者的优点。目前来看,RDA和FTRL是最好的稀疏模型Online Training的算法。FTRL并行化处理,一方面可以参考ParallelSGD,另一方面可以使用高维向量点乘,及梯度分量并行计算的思路。
机器学习(五)— FTRL一路走来,从LR -> SGD -> TG -> FOBOS -> RDA -> FTRL ↩︎
Efficient Online and Batch Learning Using Forward Backward Splitting ↩︎
各大公司广泛使用的在线学习算法FTRL详解 ↩︎
Dual Averaging Methods for Regularized Stochastic Learning and Online Optimization ↩︎
Ad Click Prediction: a View from the Trenches ↩︎
Follow-the-Regularized-Leader and Mirror Descent: Equivalence Theorems and L1 Regularization ↩︎